 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Model Checking for DNN Analysis via State-Space Reduction and Input Segmentation
Jul 03, 2023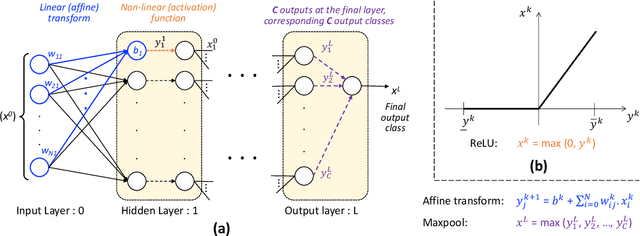
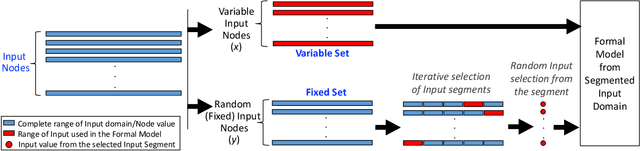
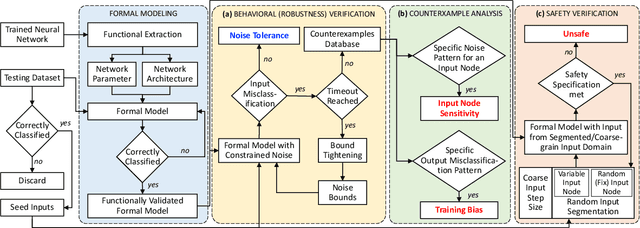
Owing to their remarkable learning capabilities and performance in real-world applications, the use of machine learning systems based on Neural Networks (NNs) has been continuously increasing. However, various case studies and empirical findings in the literature suggest that slight variations to NN inputs can lead to erroneous and undesirable NN behavior. This has led to considerable interest in their formal analysis, aiming to provide guarantees regarding a given NN's behavior. Existing frameworks provide robustness and/or safety guarantees for the trained NNs, using satisfiability solving and linear programming. We proposed FANNet, the first model checking-based framework for analyzing a broader range of NN properties. However, the state-space explosion associated with model checking entails a scalability problem, making the FANNet applicable only to small NNs. This work develops state-space reduction and input segmentation approaches, to improve the scalability and timing efficiency of formal NN analysis. Compared to the state-of-the-art FANNet, this enables our new model checking-based framework to reduce the verification's timing overhead by a factor of up to 8000, making the framework applicable to NNs even with approximately $80$ times more network parameters. This in turn allows the analysis of NN safety properties using the new framework, in addition to all the NN properties already included with FANNet. The framework is shown to be efficiently able to analyze properties of NNs trained on healthcare datasets as well as the well--acknowledged ACAS Xu NNs.
Poster: Link between Bias, Node Sensitivity and Long-Tail Distribution in trained DNNs
Apr 03, 2023



Owing to their remarkable learning (and relearning) capabilities, deep neural networks (DNNs) find use in numerous real-world applications. However, the learning of these data-driven machine learning models is generally as good as the data available to them for training. Hence, training datasets with long-tail distribution pose a challenge for DNNs, since the DNNs trained on them may provide a varying degree of classification performance across different output classes. While the overall bias of such networks is already highlighted in existing works, this work identifies the node bias that leads to a varying sensitivity of the nodes for different output classes. To the best of our knowledge, this is the first work highlighting this unique challenge in DNNs, discussing its probable causes, and providing open challenges for this new research direction. We support our reasoning using an empirical case study of the networks trained on a real-world dataset.
UnbiasedNets: A Dataset Diversification Framework for Robustness Bias Alleviation in Neural Networks
Mar 13, 2023Performance of trained neural network (NN) models, in terms of testing accuracy, has improved remarkably over the past several years, especially with the advent of deep learning. However, even the most accurate NNs can be biased toward a specific output classification due to the inherent bias in the available training datasets, which may propagate to the real-world implementations. This paper deals with the robustness bias, i.e., the bias exhibited by the trained NN by having a significantly large robustness to noise for a certain output class, as compared to the remaining output classes. The bias is shown to result from imbalanced datasets, i.e., the datasets where all output classes are not equally represented. Towards this, we propose the UnbiasedNets framework, which leverages K-means clustering and the NN's noise tolerance to diversify the given training dataset, even from relatively smaller datasets. This generates balanced datasets and reduces the bias within the datasets themselves. To the best of our knowledge, this is the first framework catering to the robustness bias problem in NNs. We use real-world datasets to demonstrate the efficacy of the UnbiasedNets for data diversification, in case of both binary and multi-label classifiers. The results are compared to well-known tools aimed at generating balanced datasets, and illustrate how existing works have limited success while addressing the robustness bias. In contrast, UnbiasedNets provides a notable improvement over existing works, while even reducing the robustness bias significantly in some cases, as observed by comparing the NNs trained on the diversified and original datasets.
* Springer Machine Learning 2023
Robust Machine Learning Systems: Challenges, Current Trends, Perspectives, and the Road Ahead
Jan 04, 2021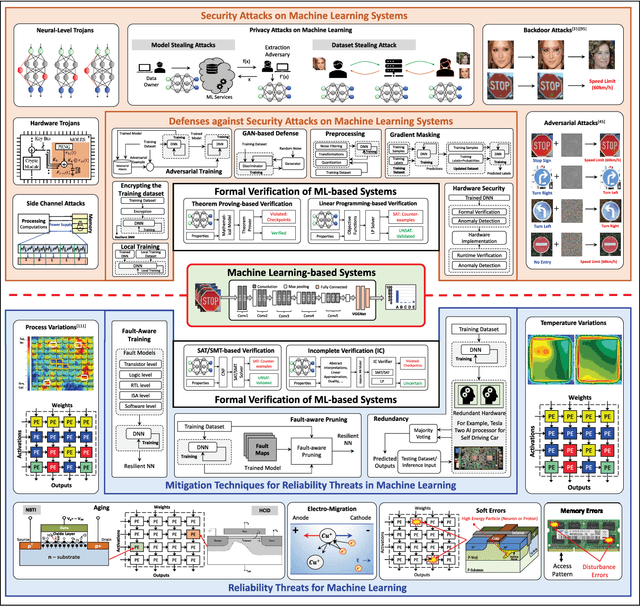

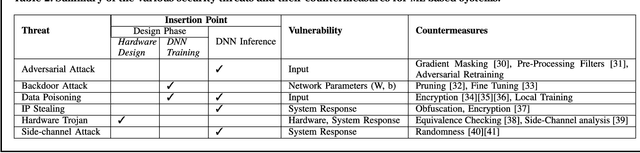
Machine Learning (ML) techniques have been rapidly adopted by smart Cyber-Physical Systems (CPS) and Internet-of-Things (IoT) due to their powerful decision-making capabilities. However, they are vulnerable to various security and reliability threats, at both hardware and software levels, that compromise their accuracy. These threats get aggravated in emerging edge ML devices that have stringent constraints in terms of resources (e.g., compute, memory, power/energy), and that therefore cannot employ costly security and reliability measures. Security, reliability, and vulnerability mitigation techniques span from network security measures to hardware protection, with an increased interest towards formal verification of trained ML models. This paper summarizes the prominent vulnerabilities of modern ML systems, highlights successful defenses and mitigation techniques against these vulnerabilities, both at the cloud (i.e., during the ML training phase) and edge (i.e., during the ML inference stage), discusses the implications of a resource-constrained design on the reliability and security of the system, identifies verification methodologies to ensure correct system behavior, and describes open research challenges for building secure and reliable ML systems at both the edge and the cloud.
* Final version appears in https://ieeexplore.ieee.org/document/8979377
FANNet: Formal Analysis of Noise Tolerance, Training Bias and Input Sensitivity in Neural Networks
Dec 03, 2019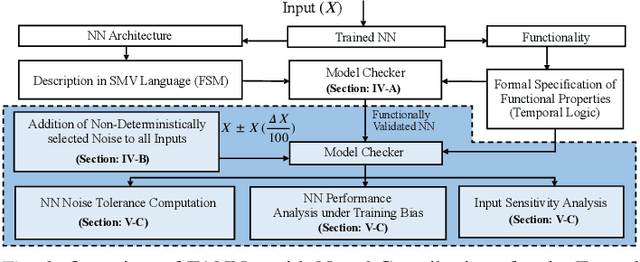
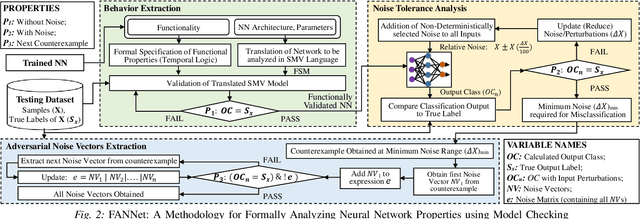
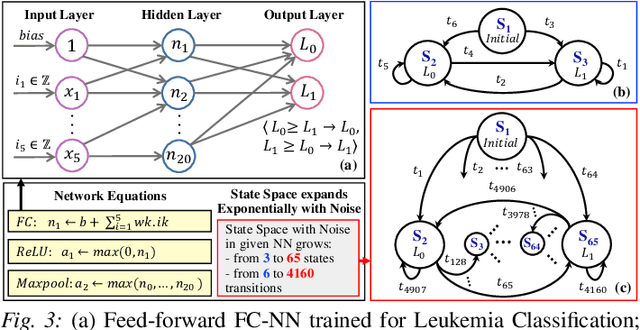
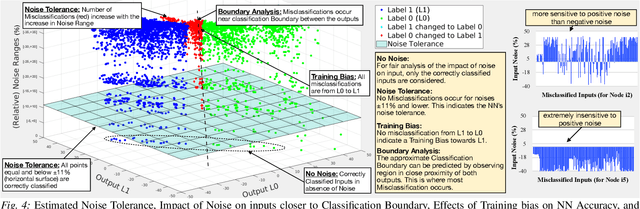
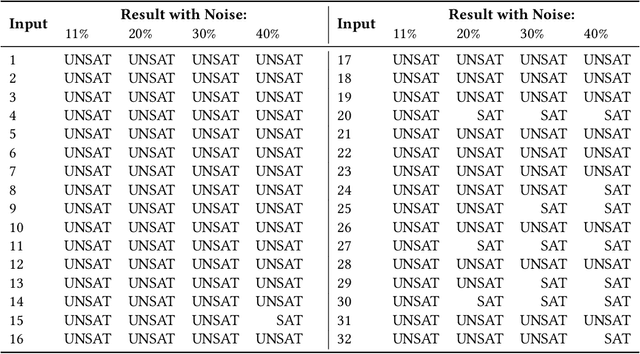
With a constant improvement in the network architectures and training methodologies, Neural Networks (NNs) are increasingly being deployed in real-world Machine Learning systems. However, despite their impressive performance on "known inputs", these NNs can fail absurdly on the "unseen inputs", especially if these real-time inputs deviate from the training dataset distributions, or contain certain types of input noise. This indicates the low noise tolerance of NNs, which is a major reason for the recent increase of adversarial attacks. This is a serious concern, particularly for safety-critical applications, where inaccurate results lead to dire consequences. We propose a novel methodology that leverages model checking for the Formal Analysis of Neural Network (FANNet) under different input noise ranges. Our methodology allows us to rigorously analyze the noise tolerance of NNs, their input node sensitivity, and the effects of training bias on their performance, e.g., in terms of classification accuracy. For evaluation, we use a feed-forward fully-connected NN architecture trained for the Leukemia classification. Our experimental results show $\pm 11\%$ noise tolerance for the given trained network, identify the most sensitive input nodes, and confirm the biasness of the available training dataset.