 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCQA: Quality and Capacity-aware grouped Query Attention
Jun 08, 2024



Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7\,$B model, QCQA achieves $\mathbf{20}$\% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $\mathbf{10.55}\,$\% higher accuracy than GQA. Furthermore, QCQA requires $40\,$\% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.
Towards Joint Optimization for DNN Architecture and Configuration for Compute-In-Memory Hardware
Feb 19, 2024With the recent growth in demand for large-scale deep neural networks, compute in-memory (CiM) has come up as a prominent solution to alleviate bandwidth and on-chip interconnect bottlenecks that constrain Von-Neuman architectures. However, the construction of CiM hardware poses a challenge as any specific memory hierarchy in terms of cache sizes and memory bandwidth at different interfaces may not be ideally matched to any neural network's attributes such as tensor dimension and arithmetic intensity, thus leading to suboptimal and under-performing systems. Despite the success of neural architecture search (NAS) techniques in yielding efficient sub-networks for a given hardware metric budget (e.g., DNN execution time or latency), it assumes the hardware configuration to be frozen, often yielding sub-optimal sub-networks for a given budget. In this paper, we present CiMNet, a framework that jointly searches for optimal sub-networks and hardware configurations for CiM architectures creating a Pareto optimal frontier of downstream task accuracy and execution metrics (e.g., latency). The proposed framework can comprehend the complex interplay between a sub-network's performance and the CiM hardware configuration choices including bandwidth, processing element size, and memory size. Exhaustive experiments on different model architectures from both CNN and Transformer families demonstrate the efficacy of the CiMNet in finding co-optimized sub-networks and CiM hardware configurations. Specifically, for similar ImageNet classification accuracy as baseline ViT-B, optimizing only the model architecture increases performance (or reduces workload execution time) by 1.7x while optimizing for both the model architecture and hardware configuration increases it by 3.1x.
Reclaimer: A Reinforcement Learning Approach to Dynamic Resource Allocation for Cloud Microservices
Apr 17, 2023Many cloud applications are migrated from the monolithic model to a microservices framework in which hundreds of loosely-coupled microservices run concurrently, with significant benefits in terms of scalability, rapid development, modularity, and isolation. However, dependencies among microservices with uneven execution time may result in longer queues, idle resources, or Quality-of-Service (QoS) violations. In this paper we introduce Reclaimer, a deep reinforcement learning model that adapts to runtime changes in the number and behavior of microservices in order to minimize CPU core allocation while meeting QoS requirements. When evaluated with two benchmark microservice-based applications, Reclaimer reduces the mean CPU core allocation by 38.4% to 74.4% relative to the industry-standard scaling solution, and by 27.5% to 58.1% relative to a current state-of-the art method.
VEGETA: Vertically-Integrated Extensions for Sparse/Dense GEMM Tile Acceleration on CPUs
Feb 23, 2023



Deep Learning (DL) acceleration support in CPUs has recently gained a lot of traction, with several companies (Arm, Intel, IBM) announcing products with specialized matrix engines accessible via GEMM instructions. CPUs are pervasive and need to handle diverse requirements across DL workloads running in edge/HPC/cloud platforms. Therefore, as DL workloads embrace sparsity to reduce the computations and memory size of models, it is also imperative for CPUs to add support for sparsity to avoid under-utilization of the dense matrix engine and inefficient usage of the caches and registers. This work presents VEGETA, a set of ISA and microarchitecture extensions over dense matrix engines to support flexible structured sparsity for CPUs, enabling programmable support for diverse DL models with varying degrees of sparsity. Compared to the state-of-the-art (SOTA) dense matrix engine in CPUs, a VEGETA engine provides 1.09x, 2.20x, 3.74x, and 3.28x speed-ups when running 4:4 (dense), 2:4, 1:4, and unstructured (95%) sparse DNN layers.
ApHMM: Accelerating Profile Hidden Markov Models for Fast and Energy-Efficient Genome Analysis
Jul 20, 2022
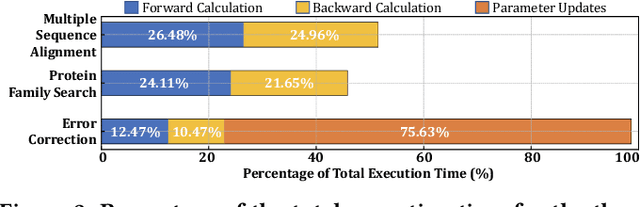
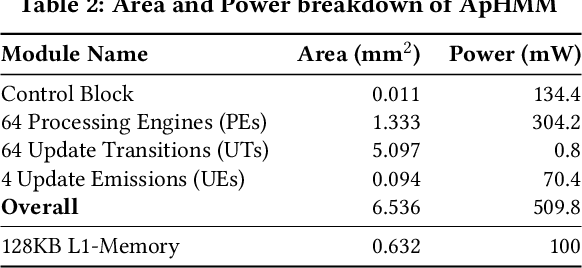
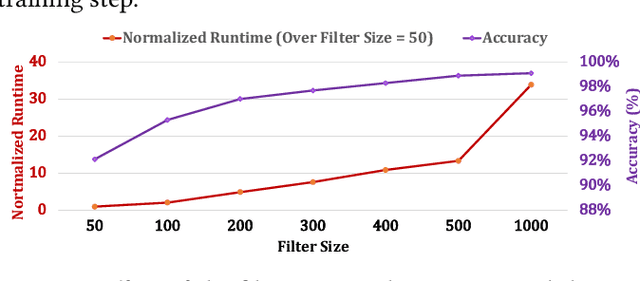
Profile hidden Markov models (pHMMs) are widely used in many bioinformatics applications to accurately identify similarities between biological sequences (e.g., DNA or protein sequences). PHMMs use a commonly-adopted and highly-accurate method, called the Baum-Welch algorithm, to calculate these similarities. However, the Baum-Welch algorithm is computationally expensive, and existing works provide either software- or hardware-only solutions for a fixed pHMM design. When we analyze the state-of-the-art works, we find that there is a pressing need for a flexible, high-performant, and energy-efficient hardware-software co-design to efficiently and effectively solve all the major inefficiencies in the Baum-Welch algorithm for pHMMs. We propose ApHMM, the first flexible acceleration framework that can significantly reduce computational and energy overheads of the Baum-Welch algorithm for pHMMs. ApHMM leverages hardware-software co-design to solve the major inefficiencies in the Baum-Welch algorithm by 1) designing a flexible hardware to support different pHMMs designs, 2) exploiting the predictable data dependency pattern in an on-chip memory with memoization techniques, 3) quickly eliminating negligible computations with a hardware-based filter, and 4) minimizing the redundant computations. We implement our 1) hardware-software optimizations on a specialized hardware and 2) software optimizations for GPUs to provide the first flexible Baum-Welch accelerator for pHMMs. ApHMM provides significant speedups of 15.55x-260.03x, 1.83x-5.34x, and 27.97x compared to CPU, GPU, and FPGA implementations of the Baum-Welch algorithm, respectively. ApHMM outperforms the state-of-the-art CPU implementations of three important bioinformatics applications, 1) error correction, 2) protein family search, and 3) multiple sequence alignment, by 1.29x-59.94x, 1.03x-1.75x, and 1.03x-1.95x, respectively.
Unsupervised Learning of Depth, Camera Pose and Optical Flow from Monocular Video
May 19, 2022



We propose DFPNet -- an unsupervised, joint learning system for monocular Depth, Optical Flow and egomotion (Camera Pose) estimation from monocular image sequences. Due to the nature of 3D scene geometry these three components are coupled. We leverage this fact to jointly train all the three components in an end-to-end manner. A single composite loss function -- which involves image reconstruction-based loss for depth & optical flow, bidirectional consistency checks and smoothness loss components -- is used to train the network. Using hyperparameter tuning, we are able to reduce the model size to less than 5% (8.4M parameters) of state-of-the-art DFP models. Evaluation on KITTI and Cityscapes driving datasets reveals that our model achieves results comparable to state-of-the-art in all of the three tasks, even with the significantly smaller model size.
Robust 3D Scene Segmentation through Hierarchical and Learnable Part-Fusion
Nov 16, 2021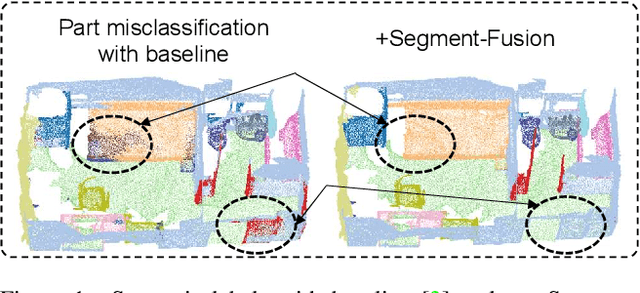
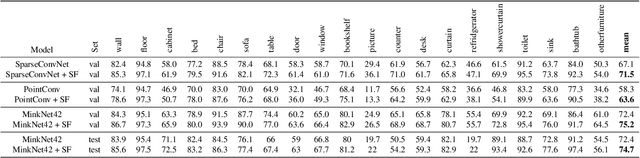
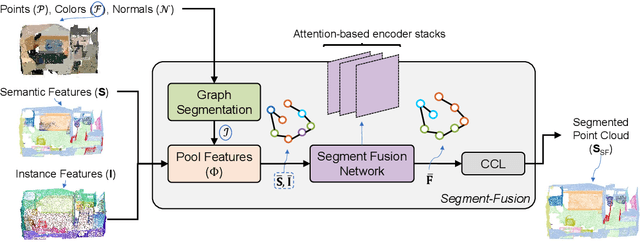
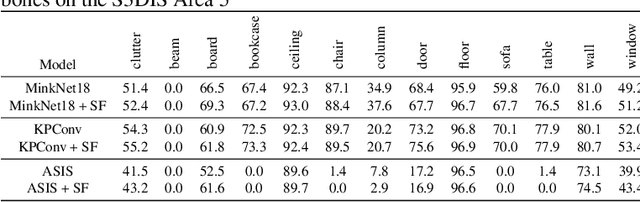
3D semantic segmentation is a fundamental building block for several scene understanding applications such as autonomous driving, robotics and AR/VR. Several state-of-the-art semantic segmentation models suffer from the part misclassification problem, wherein parts of the same object are labelled incorrectly. Previous methods have utilized hierarchical, iterative methods to fuse semantic and instance information, but they lack learnability in context fusion, and are computationally complex and heuristic driven. This paper presents Segment-Fusion, a novel attention-based method for hierarchical fusion of semantic and instance information to address the part misclassifications. The presented method includes a graph segmentation algorithm for grouping points into segments that pools point-wise features into segment-wise features, a learnable attention-based network to fuse these segments based on their semantic and instance features, and followed by a simple yet effective connected component labelling algorithm to convert segment features to instance labels. Segment-Fusion can be flexibly employed with any network architecture for semantic/instance segmentation. It improves the qualitative and quantitative performance of several semantic segmentation backbones by upto 5% when evaluated on the ScanNet and S3DIS datasets.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021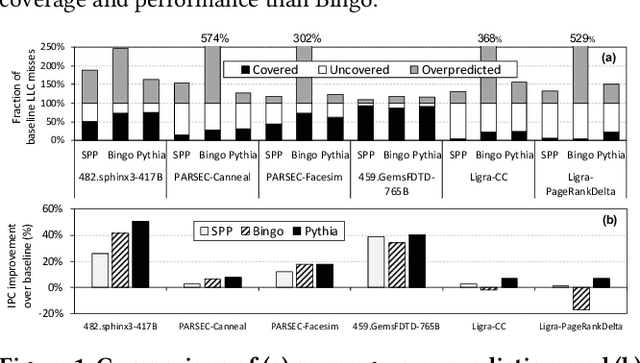
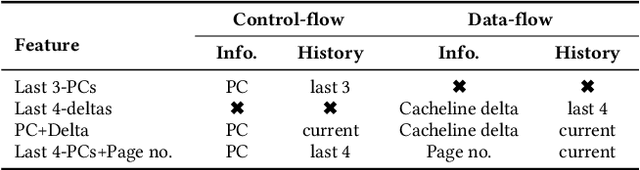

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.
RASA: Efficient Register-Aware Systolic Array Matrix Engine for CPU
Oct 05, 2021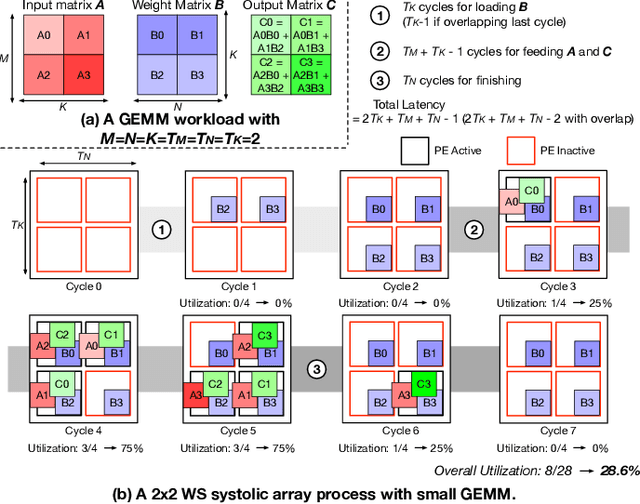
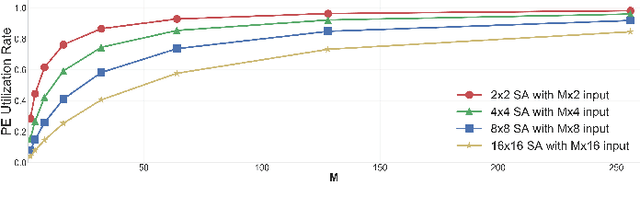
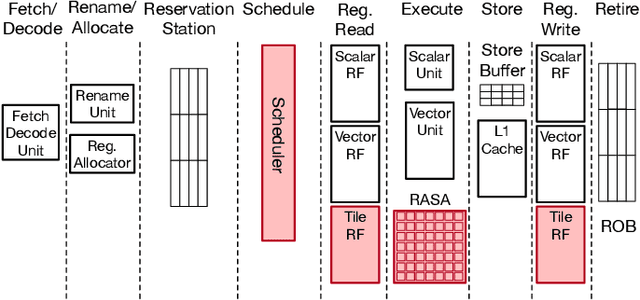
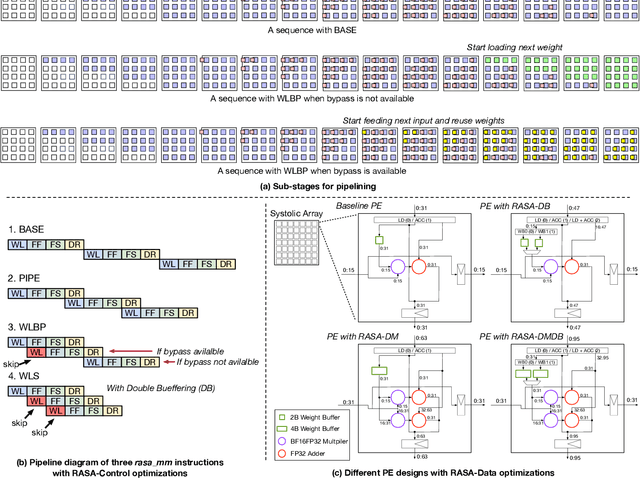
As AI-based applications become pervasive, CPU vendors are starting to incorporate matrix engines within the datapath to boost efficiency. Systolic arrays have been the premier architectural choice as matrix engines in offload accelerators. However, we demonstrate that incorporating them inside CPUs can introduce under-utilization and stalls due to limited register storage to amortize the fill and drain times of the array. To address this, we propose RASA, Register-Aware Systolic Array. We develop techniques to divide an execution stage into several sub-stages and overlap instructions to hide overheads and run them concurrently. RASA-based designs improve performance significantly with negligible area and power overhead.