 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCQA: Quality and Capacity-aware grouped Query Attention
Jun 08, 2024



Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7\,$B model, QCQA achieves $\mathbf{20}$\% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $\mathbf{10.55}\,$\% higher accuracy than GQA. Furthermore, QCQA requires $40\,$\% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.
Robust 3D Scene Segmentation through Hierarchical and Learnable Part-Fusion
Nov 16, 2021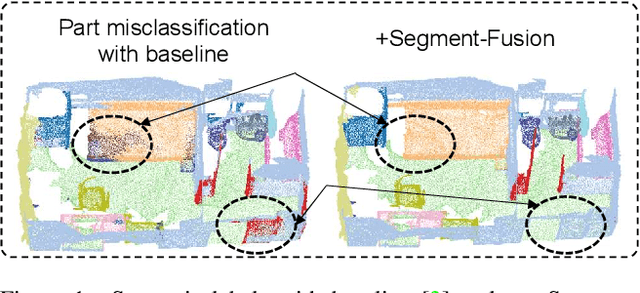
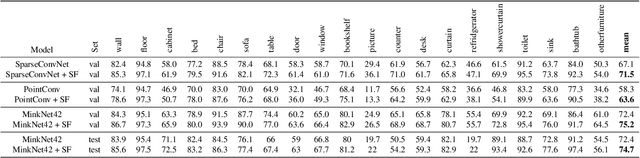
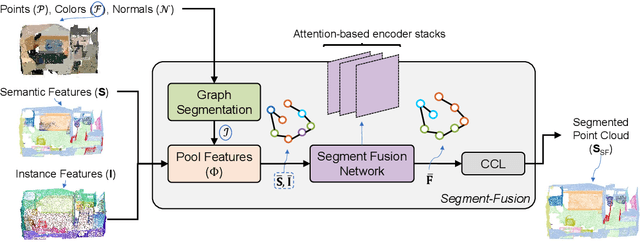
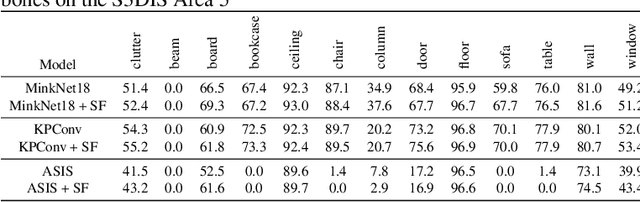
3D semantic segmentation is a fundamental building block for several scene understanding applications such as autonomous driving, robotics and AR/VR. Several state-of-the-art semantic segmentation models suffer from the part misclassification problem, wherein parts of the same object are labelled incorrectly. Previous methods have utilized hierarchical, iterative methods to fuse semantic and instance information, but they lack learnability in context fusion, and are computationally complex and heuristic driven. This paper presents Segment-Fusion, a novel attention-based method for hierarchical fusion of semantic and instance information to address the part misclassifications. The presented method includes a graph segmentation algorithm for grouping points into segments that pools point-wise features into segment-wise features, a learnable attention-based network to fuse these segments based on their semantic and instance features, and followed by a simple yet effective connected component labelling algorithm to convert segment features to instance labels. Segment-Fusion can be flexibly employed with any network architecture for semantic/instance segmentation. It improves the qualitative and quantitative performance of several semantic segmentation backbones by upto 5% when evaluated on the ScanNet and S3DIS datasets.