 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNOME: Generating Negotiations through Open-Domain Mapping of Exchanges
Jun 16, 2024
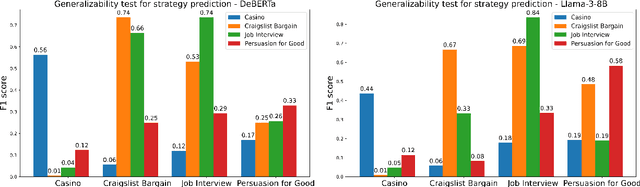

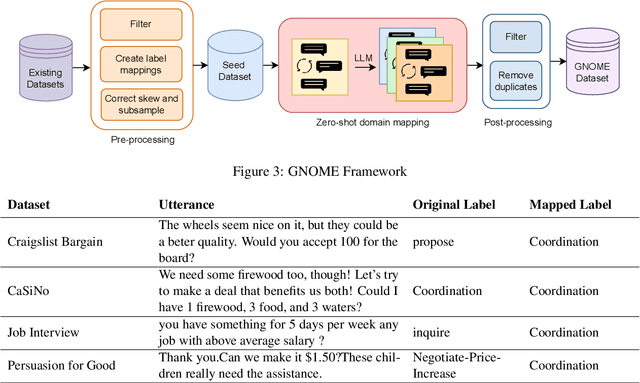
Language Models have previously shown strong negotiation capabilities in closed domains where the negotiation strategy prediction scope is constrained to a specific setup. In this paper, we first show that these models are not generalizable beyond their original training domain despite their wide-scale pretraining. Following this, we propose an automated framework called GNOME, which processes existing human-annotated, closed-domain datasets using Large Language Models and produces synthetic open-domain dialogues for negotiation. GNOME improves the generalizability of negotiation systems while reducing the expensive and subjective task of manual data curation. Through our experimental setup, we create a benchmark comparing encoder and decoder models trained on existing datasets against datasets created through GNOME. Our results show that models trained on our dataset not only perform better than previous state of the art models on domain specific strategy prediction, but also generalize better to previously unseen domains.
QCQA: Quality and Capacity-aware grouped Query Attention
Jun 08, 2024



Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7\,$B model, QCQA achieves $\mathbf{20}$\% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $\mathbf{10.55}\,$\% higher accuracy than GQA. Furthermore, QCQA requires $40\,$\% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.