 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNOME: Generating Negotiations through Open-Domain Mapping of Exchanges
Jun 16, 2024
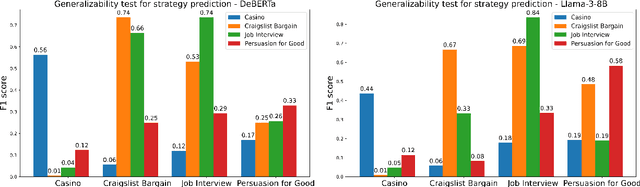

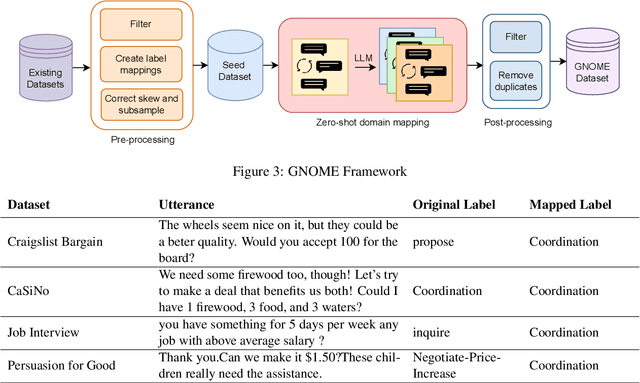
Language Models have previously shown strong negotiation capabilities in closed domains where the negotiation strategy prediction scope is constrained to a specific setup. In this paper, we first show that these models are not generalizable beyond their original training domain despite their wide-scale pretraining. Following this, we propose an automated framework called GNOME, which processes existing human-annotated, closed-domain datasets using Large Language Models and produces synthetic open-domain dialogues for negotiation. GNOME improves the generalizability of negotiation systems while reducing the expensive and subjective task of manual data curation. Through our experimental setup, we create a benchmark comparing encoder and decoder models trained on existing datasets against datasets created through GNOME. Our results show that models trained on our dataset not only perform better than previous state of the art models on domain specific strategy prediction, but also generalize better to previously unseen domains.
Combating high variance in Data-Scarce Implicit Hate Speech Classification
Aug 29, 2022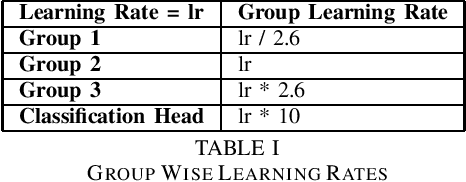
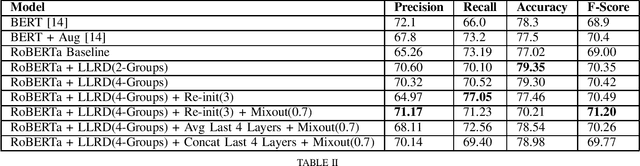
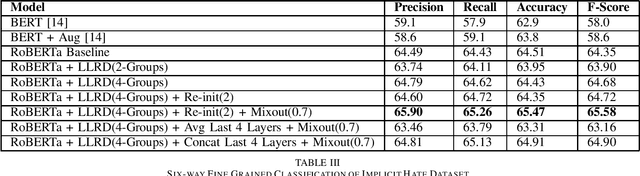
Hate speech classification has been a long-standing problem in natural language processing. However, even though there are numerous hate speech detection methods, they usually overlook a lot of hateful statements due to them being implicit in nature. Developing datasets to aid in the task of implicit hate speech classification comes with its own challenges; difficulties are nuances in language, varying definitions of what constitutes hate speech, and the labor-intensive process of annotating such data. This had led to a scarcity of data available to train and test such systems, which gives rise to high variance problems when parameter-heavy transformer-based models are used to address the problem. In this paper, we explore various optimization and regularization techniques and develop a novel RoBERTa-based model that achieves state-of-the-art performance.
Data Agnostic RoBERTa-based Natural Language to SQL Query Generation
Oct 11, 2020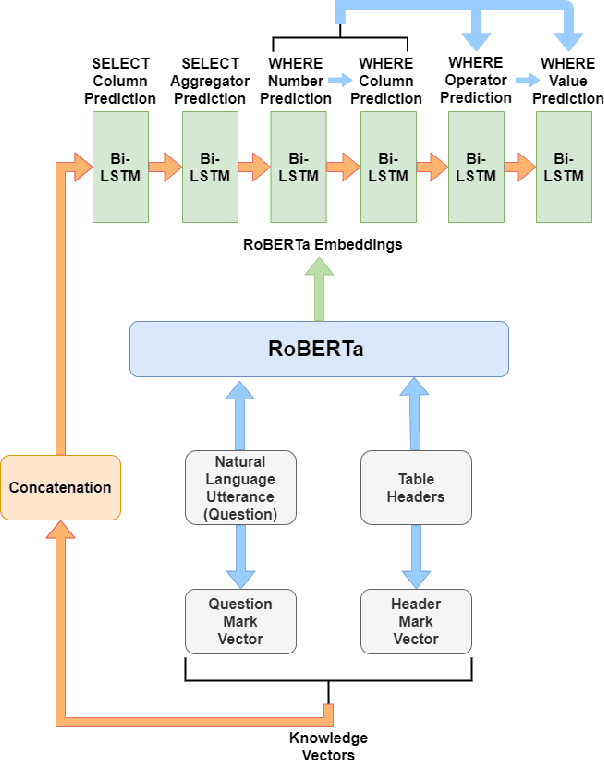
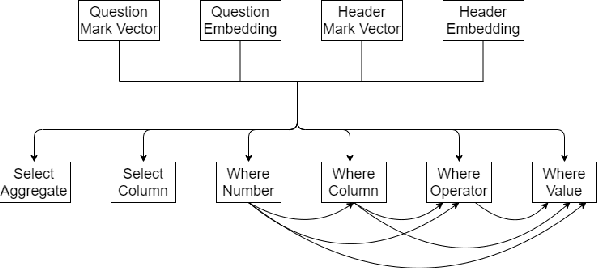
Relational databases are among the most widely used architectures to store massive amounts of data in the modern world. However, there is a barrier between these databases and the average user. The user often lacks the knowledge of a query language such as SQL required to interact with the database. The NL2SQL task aims at finding deep learning approaches to solve this problem by converting natural language questions into valid SQL queries. Given the sensitive nature of some databases and the growing need for data privacy, we have presented an approach with data privacy at its core. We have passed RoBERTa embeddings and data-agnostic knowledge vectors into LSTM based submodels to predict the final query. Although we have not achieved state of the art results, we have eliminated the need for the table data, right from the training of the model, and have achieved a test set execution accuracy of 76.7%. By eliminating the table data dependency while training we have created a model capable of zero shot learning based on the natural language question and table schema alone.