 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
BRIDGE and TCH-Net: Heterogeneous Benchmark and Multi-Branch Baseline for Cross-Domain IoT Botnet Detection
Apr 13, 2026IoT botnet detection has advanced, yet most published systems are validated on a single dataset and rarely generalise across environments. Heterogeneous feature spaces make multi-dataset training practically impossible without discarding semantic interpretability or introducing data integrity violations. No prior work has addressed both problems with a formally specified, reproducible methodology. This paper does. We introduce BRIDGE (Benchmark Reference for IoT Domain Generalisation Evaluation), the first formally specified heterogeneous multi-dataset benchmark for IoT intrusion detection, unifying CICIDS-2017, CIC-IoT-2023, Bot-IoT, Edge-IIoTset, and N-BaIoT through a 46-feature semantic canonical vocabulary grounded in CICFlowMeter nomenclature, with genuine-equivalence-only feature mapping, explicit zero-filling, and per-dataset coverage from 15% to 93%. A leave-one-dataset-out (LODO) protocol makes the generalisation gap precisely measurable: all five evaluated architectures achieve mean LODO F1 between 0.39 and 0.47, and we establish the first community generalisation baseline at mean LODO F1 = 0.5577, a result that shifts the agenda from single-benchmark optimisation toward cross-environment generalisation. We propose TCH-Net, a multi-branch network fusing a three-path Temporal branch (residual convolutional-BiGRU, stride-downsampled BiGRU, pre-LayerNorm Transformer), a provenance-conditioned Contextual branch, and a Statistical branch via Cross-Branch Gated Attention Fusion (CB-GAF) with learnable sigmoid gates for dynamic feature-wise mixing. Across five random seeds, TCH-Net achieves F1 = 0.8296 +/- 0.0028, AUC = 0.9380 +/- 0.0025, and MCC = 0.6972 +/- 0.0056, outperforming all twelve baselines (p < 0.05, Wilcoxon) and recording the highest LODO F1 overall. BRIDGE and the full pipeline are at https://github.com/Ammar-ss/TCH-Net.
FiMI: A Domain-Specific Language Model for Indian Finance Ecosystem
Feb 05, 2026We present FiMI (Finance Model for India), a domain-specialized financial language model developed for Indian digital payment systems. We develop two model variants: FiMI Base and FiMI Instruct. FiMI adapts the Mistral Small 24B architecture through a multi-stage training pipeline, beginning with continuous pre-training on 68 Billion tokens of curated financial, multilingual (English, Hindi, Hinglish), and synthetic data. This is followed by instruction fine-tuning and domain-specific supervised fine-tuning focused on multi-turn, tool-driven conversations that model real-world workflows, such as transaction disputes and mandate lifecycle management. Evaluations reveal that FiMI Base achieves a 20% improvement over the Mistral Small 24B Base model on finance reasoning benchmark, while FiMI Instruct outperforms the Mistral Small 24B Instruct model by 87% on domain-specific tool-calling. Moreover, FiMI achieves these significant domain gains while maintaining comparable performance to models of similar size on general benchmarks.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
From Facts to Conclusions : Integrating Deductive Reasoning in Retrieval-Augmented LLMs
Dec 18, 2025Retrieval-Augmented Generation (RAG) grounds large language models (LLMs) in external evidence, but fails when retrieved sources conflict or contain outdated or subjective information. Prior work address these issues independently but lack unified reasoning supervision. We propose a reasoning-trace-augmented RAG framework that adds structured, interpretable reasoning across three stages : (1) document-level adjudication, (2) conflict analysis, and (3) grounded synthesis, producing citation-linked answers or justified refusals. A Conflict-Aware Trust-Score (CATS) pipeline is introduced which evaluates groundedness, factual correctness, refusal accuracy, and conflict-behavior alignment using an LLM-as-a-Judge. Our 539-query reasoning dataset and evaluation pipeline establish a foundation for conflict-aware, interpretable RAG systems. Experimental results demonstrate substantial gains over baselines, most notably with Qwen, where Supervised Fine-Tuning improved End-to-End answer correctness from 0.069 to 0.883 and behavioral adherence from 0.074 to 0.722.
Dynamic Shape Control of Soft Robots Enabled by Data-Driven Model Reduction
Nov 06, 2025Soft robots have shown immense promise in settings where they can leverage dynamic control of their entire bodies. However, effective dynamic shape control requires a controller that accounts for the robot's high-dimensional dynamics--a challenge exacerbated by a lack of general-purpose tools for modeling soft robots amenably for control. In this work, we conduct a comparative study of data-driven model reduction techniques for generating linear models amendable to dynamic shape control. We focus on three methods--the eigensystem realization algorithm, dynamic mode decomposition with control, and the Lagrangian operator inference (LOpInf) method. Using each class of model, we explored their efficacy in model predictive control policies for the dynamic shape control of a simulated eel-inspired soft robot in three experiments: 1) tracking simulated reference trajectories guaranteed to be feasible, 2) tracking reference trajectories generated from a biological model of eel kinematics, and 3) tracking reference trajectories generated by a reduced-scale physical analog. In all experiments, the LOpInf-based policies generated lower tracking errors than policies based on other models.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
ThematicPlane: Bridging Tacit User Intent and Latent Spaces for Image Generation
Aug 08, 2025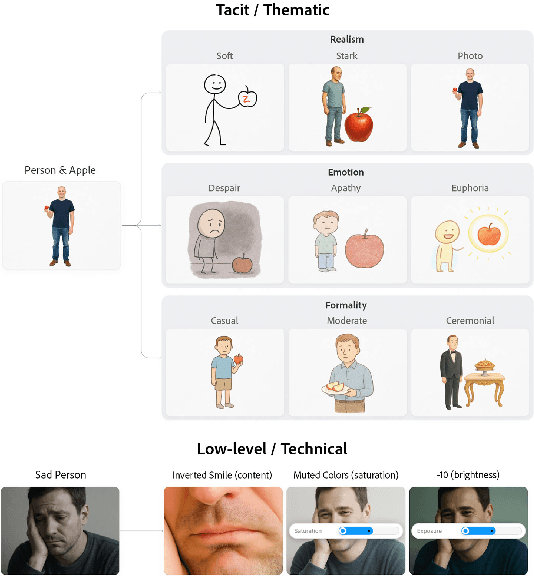
Generative AI has made image creation more accessible, yet aligning outputs with nuanced creative intent remains challenging, particularly for non-experts. Existing tools often require users to externalize ideas through prompts or references, limiting fluid exploration. We introduce ThematicPlane, a system that enables users to navigate and manipulate high-level semantic concepts (e.g., mood, style, or narrative tone) within an interactive thematic design plane. This interface bridges the gap between tacit creative intent and system control. In our exploratory study (N=6), participants engaged in divergent and convergent creative modes, often embracing unexpected results as inspiration or iteration cues. While they grounded their exploration in familiar themes, differing expectations of how themes mapped to outputs revealed a need for more explainable controls. Overall, ThematicPlane fosters expressive, iterative workflows and highlights new directions for intuitive, semantics-driven interaction in generative design tools.
Team ACK at SemEval-2025 Task 2: Beyond Word-for-Word Machine Translation for English-Korean Pairs
Apr 29, 2025Translating knowledge-intensive and entity-rich text between English and Korean requires transcreation to preserve language-specific and cultural nuances beyond literal, phonetic or word-for-word conversion. We evaluate 13 models (LLMs and MT models) using automatic metrics and human assessment by bilingual annotators. Our findings show LLMs outperform traditional MT systems but struggle with entity translation requiring cultural adaptation. By constructing an error taxonomy, we identify incorrect responses and entity name errors as key issues, with performance varying by entity type and popularity level. This work exposes gaps in automatic evaluation metrics and hope to enable future work in completing culturally-nuanced machine translation.