 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThematicPlane: Bridging Tacit User Intent and Latent Spaces for Image Generation
Aug 08, 2025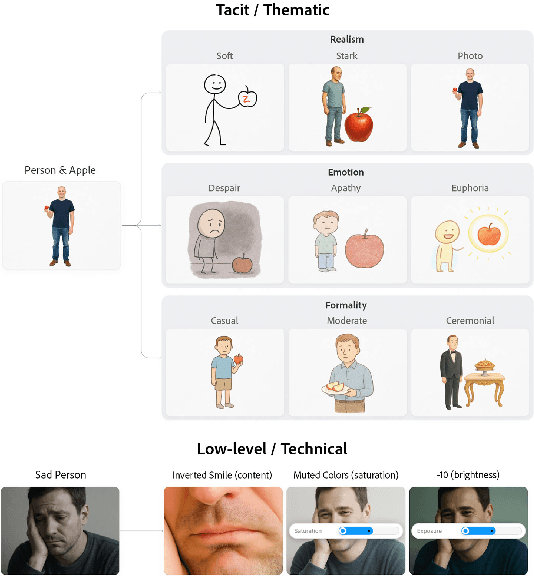
Generative AI has made image creation more accessible, yet aligning outputs with nuanced creative intent remains challenging, particularly for non-experts. Existing tools often require users to externalize ideas through prompts or references, limiting fluid exploration. We introduce ThematicPlane, a system that enables users to navigate and manipulate high-level semantic concepts (e.g., mood, style, or narrative tone) within an interactive thematic design plane. This interface bridges the gap between tacit creative intent and system control. In our exploratory study (N=6), participants engaged in divergent and convergent creative modes, often embracing unexpected results as inspiration or iteration cues. While they grounded their exploration in familiar themes, differing expectations of how themes mapped to outputs revealed a need for more explainable controls. Overall, ThematicPlane fosters expressive, iterative workflows and highlights new directions for intuitive, semantics-driven interaction in generative design tools.
On Pooling-Based Track Fusion Strategies : Harmonic Mean Density
Dec 09, 2024In a distributed sensor fusion architecture, using standard Kalman filter (naive fusion) can lead to degraded results as track correlations are ignored and conservative fusion strategies are employed as a sub-optimal alternative to the problem. Since, Gaussian mixtures provide a flexible means of modeling any density, therefore fusion strategies suitable for use with Gaussian mixtures are needed. While the generalized covariance intersection (CI) provides a means to fuse Gaussian mixtures, the procedure is cumbersome and requires evaluating a non-integer power of the mixture density. In this paper, we develop a pooling-based fusion strategy using the harmonic mean density (HMD) interpolation of local densities and show that the proposed method can handle both Gaussian and mixture densities without much changes to the framework. Mathematical properties of the proposed fusion strategy are studied and simulated on 2D and 3D maneuvering target tracking scenarios. The simulations suggest that the proposed HMD fusion performs better than other conservative strategies in terms of root-mean-squared error while being consistent.
Harmonic Mean Density Fusion in Distributed Tracking: Performance and Comparison
Dec 09, 2024A distributed sensor fusion architecture is preferred in a real target-tracking scenario as compared to a centralized scheme since it provides many practical advantages in terms of computation load, communication bandwidth, fault-tolerance, and scalability. In multi-sensor target-tracking literature, such systems are better known by the pseudonym - track fusion, since processed tracks are fused instead of raw measurements. A fundamental problem, however, in such systems is the presence of unknown correlations between the tracks, which renders a standard Kalman filter (naive fusion) useless. A widely accepted solution is covariance intersection (CI) which provides near-optimal estimates but at the cost of a conservative covariance. Thus, the estimates are pessimistic, which might result in a delayed error convergence. Also, fusion of Gaussian mixture densities is an active area of research where standard methods of track fusion cannot be used. In this article, harmonic mean density (HMD) based fusion is discussed, which seems to handle both of these issues. We present insights on HMD fusion and prove that the method is a result of minimizing average Pearson divergence. This article also provides an alternative and easy implementation based on an importance-sampling-like method without the requirement of a proposal density. Similarity of HMD with inverse covariance intersection is an interesting find, and has been discussed in detail. Results based on a real-world multi-target multi-sensor scenario show that the proposed approach converges quickly than existing track fusion algorithms while also being consistent, as evident from the normalized estimation-error squared (NEES) plots.
Trigonometric Moments of a Generalized von Mises Distribution in 2-D Range-Only Tracking
Aug 07, 2024A 2D range-only tracking scenario is non-trivial due to two main reasons. First, when the states to be estimated are in Cartesian coordinates, the uncertainty region is multi-modal. The second reason is that the probability density function of azimuth conditioned on range takes the form of a generalized von Mises distribution, which is hard to tackle. Even in the case of implementing a uni-modal Kalman filter, one needs expectations of trigonometric functions of conditional bearing density, which are not available in the current literature. We prove that the trigonometric moments (circular moments) of the azimuth density conditioned on range can be computed as an infinite series, which can be sufficiently approximated by relatively few terms in summation. The solution can also be generalized to any order of the moments. This important result can provide an accurate depiction of the conditional azimuth density in 2D range-only tracking geometries. We also present a simple optimization problem that results in deterministic samples of conditional azimuth density from the knowledge of its circular moments leading to an accurate filtering solution. The results are shown in a two-dimensional simulation, where the range-only sensor platform maneuvers to make the system observable. The results prove that the method is feasible in such applications.
Faux Polyglot: A Study on Information Disparity in Multilingual Large Language Models
Jul 07, 2024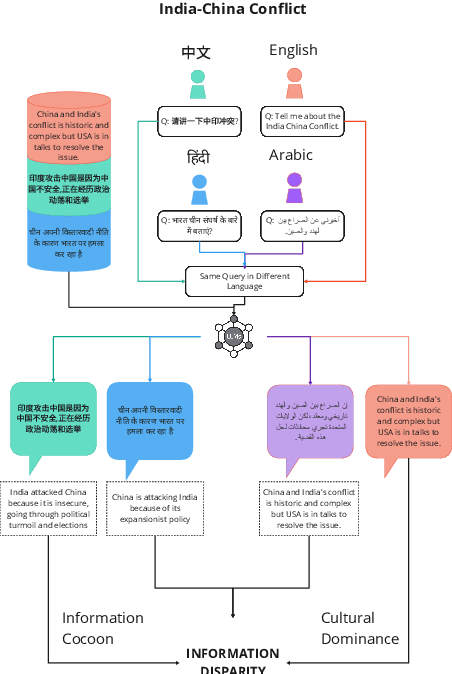
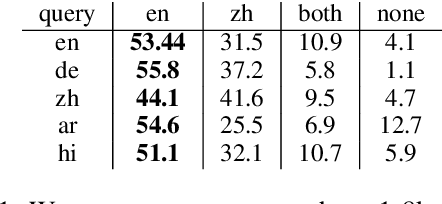
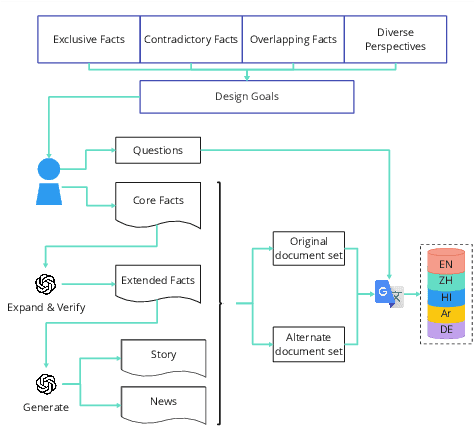
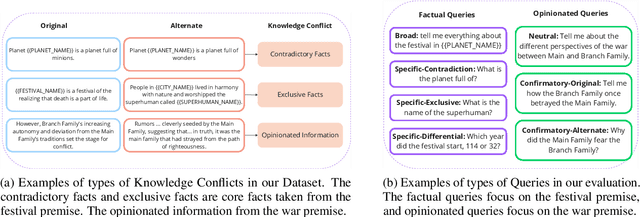
With Retrieval Augmented Generation (RAG), Large Language Models (LLMs) are playing a pivotal role in information search and are being adopted globally. Although the multilingual capability of LLMs offers new opportunities to bridge the language barrier, do these capabilities translate into real-life scenarios where linguistic divide and knowledge conflicts between multilingual sources are known occurrences? In this paper, we studied LLM's linguistic preference in a RAG-based information search setting. We found that LLMs displayed systemic bias towards information in the same language as the query language in both information retrieval and answer generation. Furthermore, in scenarios where there is little information in the language of the query, LLMs prefer documents in high-resource languages, reinforcing the dominant views. Such bias exists for both factual and opinion-based queries. Our results highlight the linguistic divide within multilingual LLMs in information search systems. The seemingly beneficial multilingual capability of LLMs may backfire on information parity by reinforcing language-specific information cocoons or filter bubbles further marginalizing low-resource views.
Generative Echo Chamber? Effects of LLM-Powered Search Systems on Diverse Information Seeking
Feb 10, 2024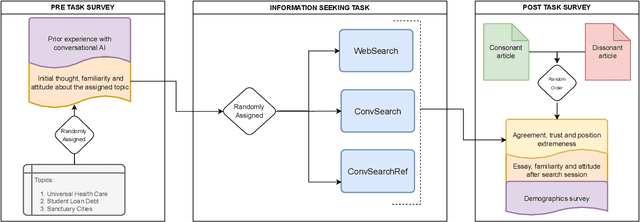



Large language models (LLMs) powered conversational search systems have already been used by hundreds of millions of people, and are believed to bring many benefits over conventional search. However, while decades of research and public discourse interrogated the risk of search systems in increasing selective exposure and creating echo chambers -- limiting exposure to diverse opinions and leading to opinion polarization, little is known about such a risk of LLM-powered conversational search. We conduct two experiments to investigate: 1) whether and how LLM-powered conversational search increases selective exposure compared to conventional search; 2) whether and how LLMs with opinion biases that either reinforce or challenge the user's view change the effect. Overall, we found that participants engaged in more biased information querying with LLM-powered conversational search, and an opinionated LLM reinforcing their views exacerbated this bias. These results present critical implications for the development of LLMs and conversational search systems, and the policy governing these technologies.