 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intuition: Efficient Classification of Scientific Abstracts
Jul 08, 2024



It is desirable to coarsely classify short scientific texts, such as grant or publication abstracts, for strategic insight or research portfolio management. These texts efficiently transmit dense information to experts possessing a rich body of knowledge to aid interpretation. Yet this task is remarkably difficult to automate because of brevity and the absence of context. To address this gap, we have developed a novel approach to generate and appropriately assign coarse domain-specific labels. We show that a Large Language Model (LLM) can provide metadata essential to the task, in a process akin to the augmentation of supplemental knowledge representing human intuition, and propose a workflow. As a pilot study, we use a corpus of award abstracts from the National Aeronautics and Space Administration (NASA). We develop new assessment tools in concert with established performance metrics.
GNOME: Generating Negotiations through Open-Domain Mapping of Exchanges
Jun 16, 2024
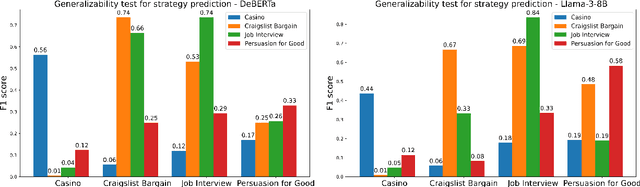

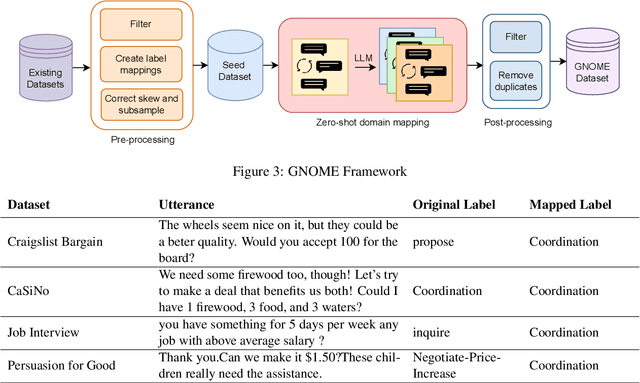
Language Models have previously shown strong negotiation capabilities in closed domains where the negotiation strategy prediction scope is constrained to a specific setup. In this paper, we first show that these models are not generalizable beyond their original training domain despite their wide-scale pretraining. Following this, we propose an automated framework called GNOME, which processes existing human-annotated, closed-domain datasets using Large Language Models and produces synthetic open-domain dialogues for negotiation. GNOME improves the generalizability of negotiation systems while reducing the expensive and subjective task of manual data curation. Through our experimental setup, we create a benchmark comparing encoder and decoder models trained on existing datasets against datasets created through GNOME. Our results show that models trained on our dataset not only perform better than previous state of the art models on domain specific strategy prediction, but also generalize better to previously unseen domains.