 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
May 28, 2024The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
Towards Joint Optimization for DNN Architecture and Configuration for Compute-In-Memory Hardware
Feb 19, 2024With the recent growth in demand for large-scale deep neural networks, compute in-memory (CiM) has come up as a prominent solution to alleviate bandwidth and on-chip interconnect bottlenecks that constrain Von-Neuman architectures. However, the construction of CiM hardware poses a challenge as any specific memory hierarchy in terms of cache sizes and memory bandwidth at different interfaces may not be ideally matched to any neural network's attributes such as tensor dimension and arithmetic intensity, thus leading to suboptimal and under-performing systems. Despite the success of neural architecture search (NAS) techniques in yielding efficient sub-networks for a given hardware metric budget (e.g., DNN execution time or latency), it assumes the hardware configuration to be frozen, often yielding sub-optimal sub-networks for a given budget. In this paper, we present CiMNet, a framework that jointly searches for optimal sub-networks and hardware configurations for CiM architectures creating a Pareto optimal frontier of downstream task accuracy and execution metrics (e.g., latency). The proposed framework can comprehend the complex interplay between a sub-network's performance and the CiM hardware configuration choices including bandwidth, processing element size, and memory size. Exhaustive experiments on different model architectures from both CNN and Transformer families demonstrate the efficacy of the CiMNet in finding co-optimized sub-networks and CiM hardware configurations. Specifically, for similar ImageNet classification accuracy as baseline ViT-B, optimizing only the model architecture increases performance (or reduces workload execution time) by 1.7x while optimizing for both the model architecture and hardware configuration increases it by 3.1x.
SimQ-NAS: Simultaneous Quantization Policy and Neural Architecture Search
Dec 19, 2023Recent one-shot Neural Architecture Search algorithms rely on training a hardware-agnostic super-network tailored to a specific task and then extracting efficient sub-networks for different hardware platforms. Popular approaches separate the training of super-networks from the search for sub-networks, often employing predictors to alleviate the computational overhead associated with search. Additionally, certain methods also incorporate the quantization policy within the search space. However, while the quantization policy search for convolutional neural networks is well studied, the extension of these methods to transformers and especially foundation models remains under-explored. In this paper, we demonstrate that by using multi-objective search algorithms paired with lightly trained predictors, we can efficiently search for both the sub-network architecture and the corresponding quantization policy and outperform their respective baselines across different performance objectives such as accuracy, model size, and latency. Specifically, we demonstrate that our approach performs well across both uni-modal (ViT and BERT) and multi-modal (BEiT-3) transformer-based architectures as well as convolutional architectures (ResNet). For certain networks, we demonstrate an improvement of up to $4.80x$ and $3.44x$ for latency and model size respectively, without degradation in accuracy compared to the fully quantized INT8 baselines.
InstaTune: Instantaneous Neural Architecture Search During Fine-Tuning
Aug 29, 2023



One-Shot Neural Architecture Search (NAS) algorithms often rely on training a hardware agnostic super-network for a domain specific task. Optimal sub-networks are then extracted from the trained super-network for different hardware platforms. However, training super-networks from scratch can be extremely time consuming and compute intensive especially for large models that rely on a two-stage training process of pre-training and fine-tuning. State of the art pre-trained models are available for a wide range of tasks, but their large sizes significantly limits their applicability on various hardware platforms. We propose InstaTune, a method that leverages off-the-shelf pre-trained weights for large models and generates a super-network during the fine-tuning stage. InstaTune has multiple benefits. Firstly, since the process happens during fine-tuning, it minimizes the overall time and compute resources required for NAS. Secondly, the sub-networks extracted are optimized for the target task, unlike prior work that optimizes on the pre-training objective. Finally, InstaTune is easy to "plug and play" in existing frameworks. By using multi-objective evolutionary search algorithms along with lightly trained predictors, we find Pareto-optimal sub-networks that outperform their respective baselines across different performance objectives such as accuracy and MACs. Specifically, we demonstrate that our approach performs well across both unimodal (ViT and BERT) and multi-modal (BEiT-3) transformer based architectures.
A Hardware-Aware Framework for Accelerating Neural Architecture Search Across Modalities
May 19, 2022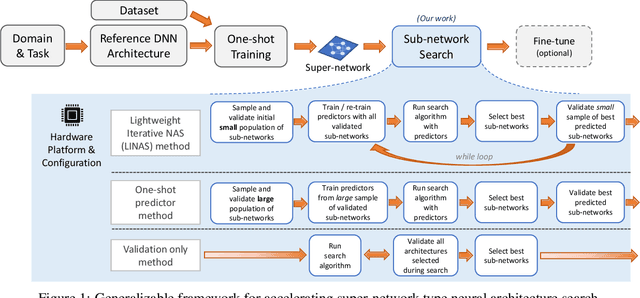
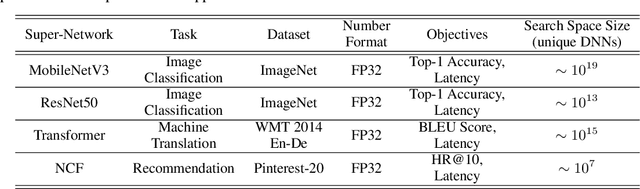
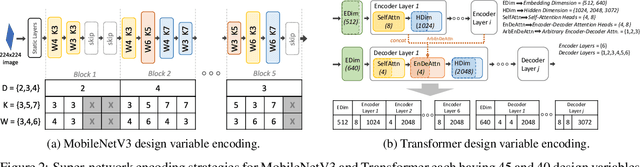
Recent advances in Neural Architecture Search (NAS) such as one-shot NAS offer the ability to extract specialized hardware-aware sub-network configurations from a task-specific super-network. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still under-explored. Popular methods decouple the super-network training from the sub-network search and use performance predictors to reduce the computational burden of searching on different hardware platforms. We propose a flexible search framework that automatically and efficiently finds optimal sub-networks that are optimized for different performance metrics and hardware configurations. Specifically, we show how evolutionary algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate architecture search in a multi-objective setting for various modalities including machine translation and image classification.
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022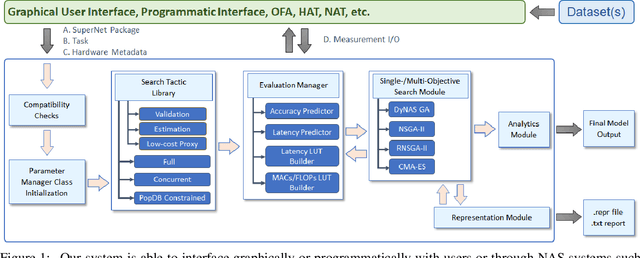
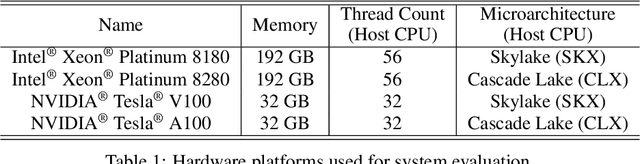
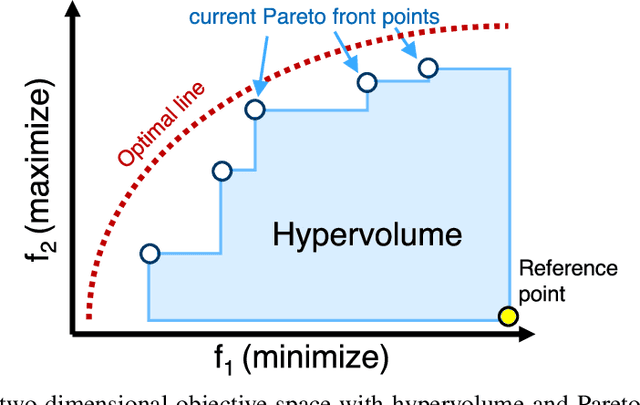
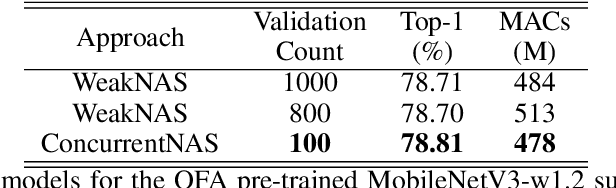
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.
Accelerating Neural Architecture Exploration Across Modalities Using Genetic Algorithms
Feb 25, 2022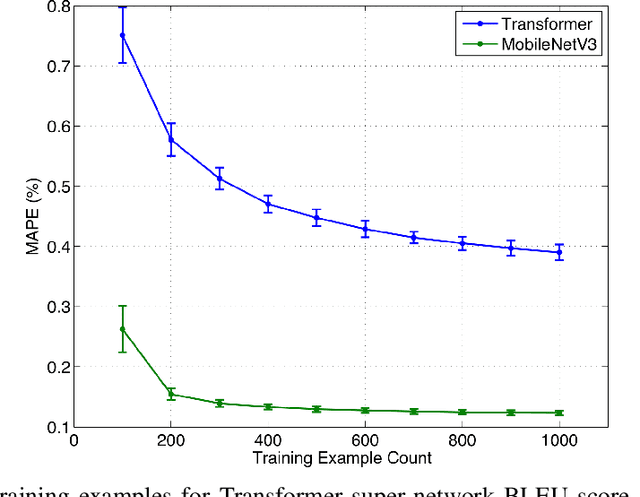
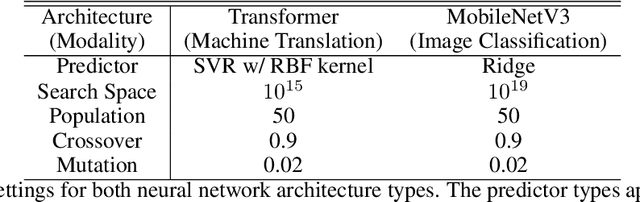
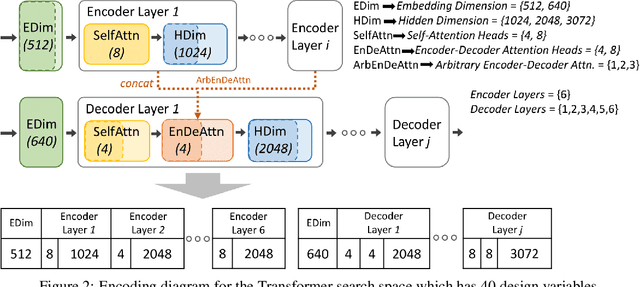
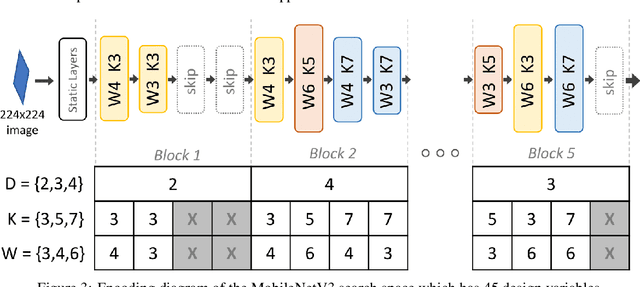
Neural architecture search (NAS), the study of automating the discovery of optimal deep neural network architectures for tasks in domains such as computer vision and natural language processing, has seen rapid growth in the machine learning research community. While there have been many recent advancements in NAS, there is still a significant focus on reducing the computational cost incurred when validating discovered architectures by making search more efficient. Evolutionary algorithms, specifically genetic algorithms, have a history of usage in NAS and continue to gain popularity versus other optimization approaches as a highly efficient way to explore the architecture objective space. Most NAS research efforts have centered around computer vision tasks and only recently have other modalities, such as the rapidly growing field of natural language processing, been investigated in depth. In this work, we show how genetic algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate multi-objective architectural exploration in a way that works in the modalities of both machine translation and image classification.
TrimBERT: Tailoring BERT for Trade-offs
Feb 24, 2022


Models based on BERT have been extremely successful in solving a variety of natural language processing (NLP) tasks. Unfortunately, many of these large models require a great deal of computational resources and/or time for pre-training and fine-tuning which limits wider adoptability. While self-attention layers have been well-studied, a strong justification for inclusion of the intermediate layers which follow them remains missing in the literature. In this work, we show that reducing the number of intermediate layers in BERT-Base results in minimal fine-tuning accuracy loss of downstream tasks while significantly decreasing model size and training time. We further mitigate two key bottlenecks, by replacing all softmax operations in the self-attention layers with a computationally simpler alternative and removing half of all layernorm operations. This further decreases the training time while maintaining a high level of fine-tuning accuracy.
Undivided Attention: Are Intermediate Layers Necessary for BERT?
Dec 22, 2020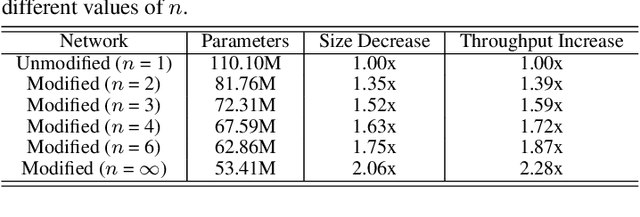
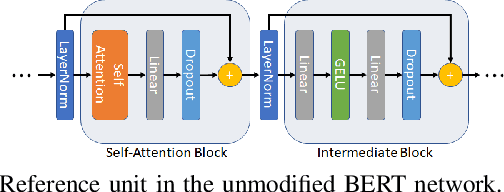
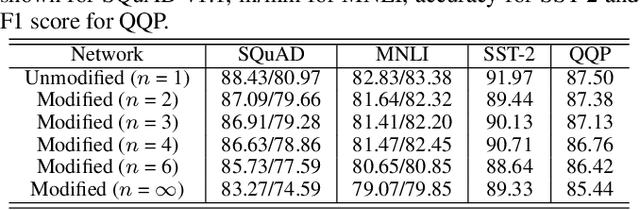

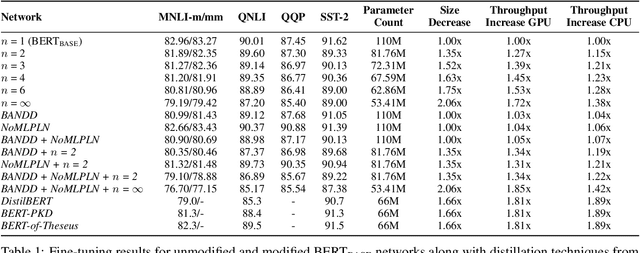
In recent times, BERT-based models have been extremely successful in solving a variety of natural language processing (NLP) tasks such as reading comprehension, natural language inference, sentiment analysis, etc. All BERT-based architectures have a self-attention block followed by a block of intermediate layers as the basic building component. However, a strong justification for the inclusion of these intermediate layers remains missing in the literature. In this work we investigate the importance of intermediate layers on the overall network performance of downstream tasks. We show that reducing the number of intermediate layers and modifying the architecture for BERT-Base results in minimal loss in fine-tuning accuracy for downstream tasks while decreasing the number of parameters and training time of the model. Additionally, we use the central kernel alignment (CKA) similarity metric and probing classifiers to demonstrate that removing intermediate layers has little impact on the learned self-attention representations.