 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Perceptual Quality: Evaluating the Impact of Severe Lossy Compression on Audio and Image Models
Jan 15, 2024



In the field of neural data compression, the prevailing focus has been on optimizing algorithms for either classical distortion metrics, such as PSNR or SSIM, or human perceptual quality. With increasing amounts of data consumed by machines rather than humans, a new paradigm of machine-oriented compression$\unicode{x2013}$which prioritizes the retention of features salient for machine perception over traditional human-centric criteria$\unicode{x2013}$has emerged, creating several new challenges to the development, evaluation, and deployment of systems utilizing lossy compression. In particular, it is unclear how different approaches to lossy compression will affect the performance of downstream machine perception tasks. To address this under-explored area, we evaluate various perception models$\unicode{x2013}$including image classification, image segmentation, speech recognition, and music source separation$\unicode{x2013}$under severe lossy compression. We utilize several popular codecs spanning conventional, neural, and generative compression architectures. Our results indicate three key findings: (1) using generative compression, it is feasible to leverage highly compressed data while incurring a negligible impact on machine perceptual quality; (2) machine perceptual quality correlates strongly with deep similarity metrics, indicating a crucial role of these metrics in the development of machine-oriented codecs; and (3) using lossy compressed datasets, (e.g. ImageNet) for pre-training can lead to counter-intuitive scenarios where lossy compression increases machine perceptual quality rather than degrading it. To encourage engagement on this growing area of research, our code and experiments are available at: https://github.com/danjacobellis/MPQ.
Neural Architecture Codesign for Fast Bragg Peak Analysis
Dec 12, 2023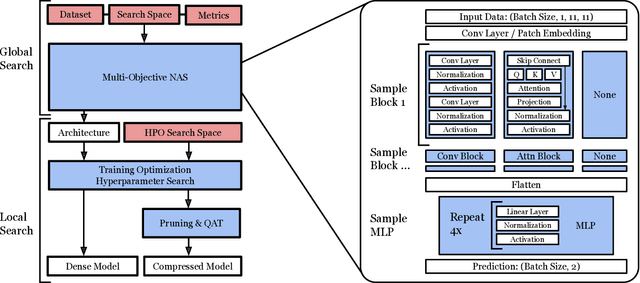
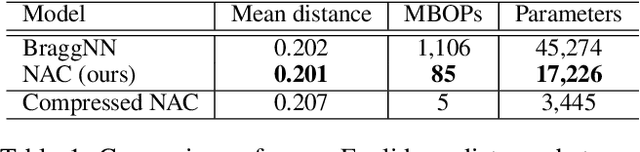
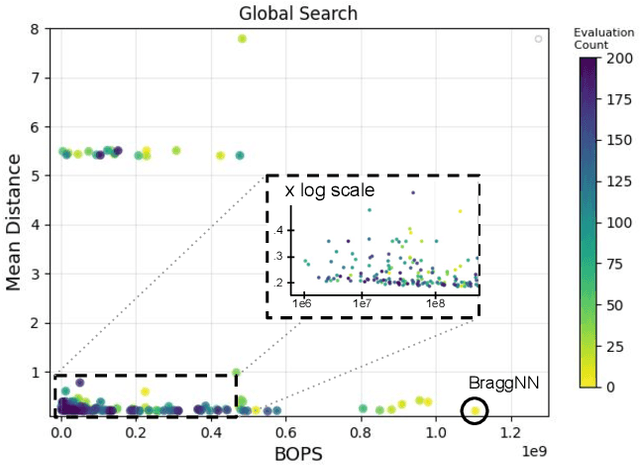

We develop an automated pipeline to streamline neural architecture codesign for fast, real-time Bragg peak analysis in high-energy diffraction microscopy. Traditional approaches, notably pseudo-Voigt fitting, demand significant computational resources, prompting interest in deep learning models for more efficient solutions. Our method employs neural architecture search and AutoML to enhance these models, including hardware costs, leading to the discovery of more hardware-efficient neural architectures. Our results match the performance, while achieving a 13$\times$ reduction in bit operations compared to the previous state-of-the-art. We show further speedup through model compression techniques such as quantization-aware-training and neural network pruning. Additionally, our hierarchical search space provides greater flexibility in optimization, which can easily extend to other tasks and domains.
UniCat: Crafting a Stronger Fusion Baseline for Multimodal Re-Identification
Oct 28, 2023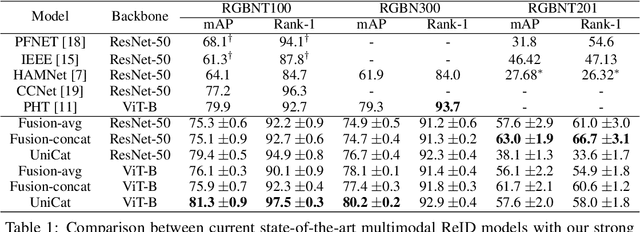

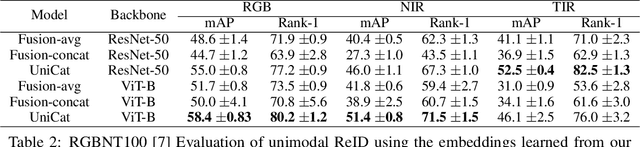
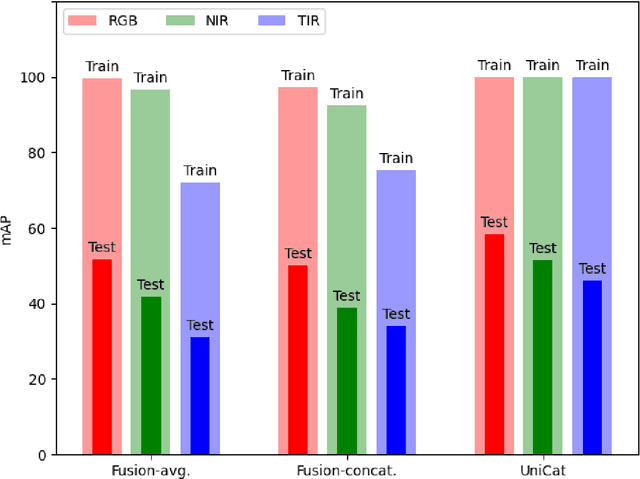
Multimodal Re-Identification (ReID) is a popular retrieval task that aims to re-identify objects across diverse data streams, prompting many researchers to integrate multiple modalities into a unified representation. While such fusion promises a holistic view, our investigations shed light on potential pitfalls. We uncover that prevailing late-fusion techniques often produce suboptimal latent representations when compared to methods that train modalities in isolation. We argue that this effect is largely due to the inadvertent relaxation of the training objectives on individual modalities when using fusion, what others have termed modality laziness. We present a nuanced point-of-view that this relaxation can lead to certain modalities failing to fully harness available task-relevant information, and yet, offers a protective veil to noisy modalities, preventing them from overfitting to task-irrelevant data. Our findings also show that unimodal concatenation (UniCat) and other late-fusion ensembling of unimodal backbones, when paired with best-known training techniques, exceed the current state-of-the-art performance across several multimodal ReID benchmarks. By unveiling the double-edged sword of "modality laziness", we motivate future research in balancing local modality strengths with global representations.
Linear Mode Connectivity in Sparse Neural Networks
Oct 28, 2023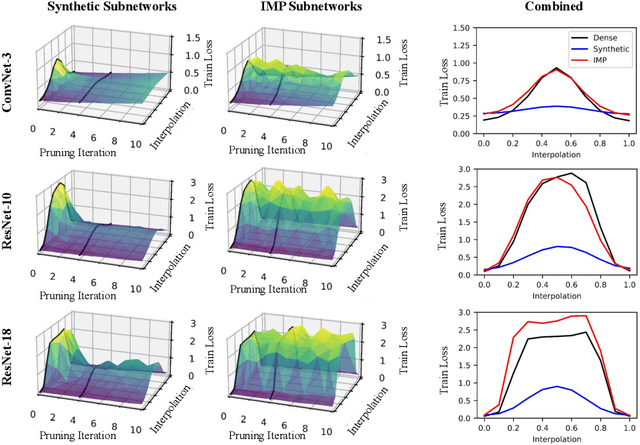
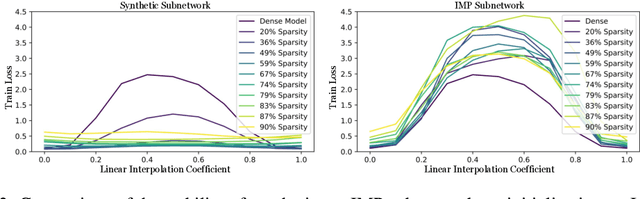
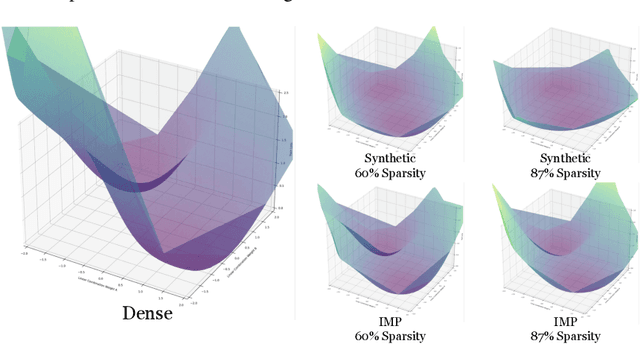
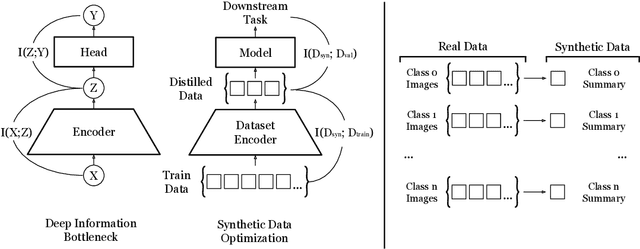
With the rise in interest of sparse neural networks, we study how neural network pruning with synthetic data leads to sparse networks with unique training properties. We find that distilled data, a synthetic summarization of the real data, paired with Iterative Magnitude Pruning (IMP) unveils a new class of sparse networks that are more stable to SGD noise on the real data, than either the dense model, or subnetworks found with real data in IMP. That is, synthetically chosen subnetworks often train to the same minima, or exhibit linear mode connectivity. We study this through linear interpolation, loss landscape visualizations, and measuring the diagonal of the hessian. While dataset distillation as a field is still young, we find that these properties lead to synthetic subnetworks matching the performance of traditional IMP with up to 150x less training points in settings where distilled data applies.
GraFT: Gradual Fusion Transformer for Multimodal Re-Identification
Oct 25, 2023



Object Re-Identification (ReID) is pivotal in computer vision, witnessing an escalating demand for adept multimodal representation learning. Current models, although promising, reveal scalability limitations with increasing modalities as they rely heavily on late fusion, which postpones the integration of specific modality insights. Addressing this, we introduce the \textbf{Gradual Fusion Transformer (GraFT)} for multimodal ReID. At its core, GraFT employs learnable fusion tokens that guide self-attention across encoders, adeptly capturing both modality-specific and object-specific features. Further bolstering its efficacy, we introduce a novel training paradigm combined with an augmented triplet loss, optimizing the ReID feature embedding space. We demonstrate these enhancements through extensive ablation studies and show that GraFT consistently surpasses established multimodal ReID benchmarks. Additionally, aiming for deployment versatility, we've integrated neural network pruning into GraFT, offering a balance between model size and performance.
Distilled Pruning: Using Synthetic Data to Win the Lottery
Jul 11, 2023This work introduces a novel approach to pruning deep learning models by using distilled data. Unlike conventional strategies which primarily focus on architectural or algorithmic optimization, our method reconsiders the role of data in these scenarios. Distilled datasets capture essential patterns from larger datasets, and we demonstrate how to leverage this capability to enable a computationally efficient pruning process. Our approach can find sparse, trainable subnetworks (a.k.a. Lottery Tickets) up to 5x faster than Iterative Magnitude Pruning at comparable sparsity on CIFAR-10. The experimental results highlight the potential of using distilled data for resource-efficient neural network pruning, model compression, and neural architecture search.
A Hardware-Aware Framework for Accelerating Neural Architecture Search Across Modalities
May 19, 2022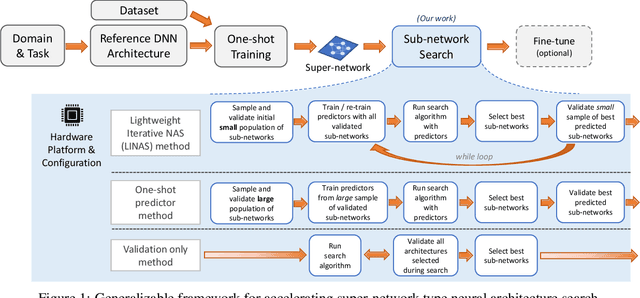
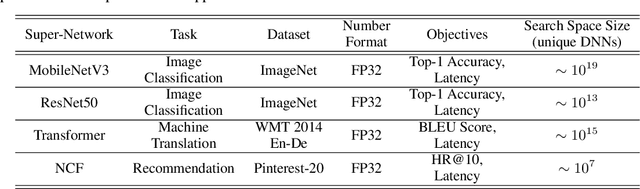
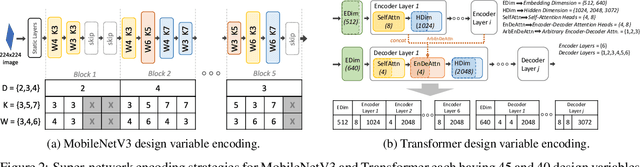
Recent advances in Neural Architecture Search (NAS) such as one-shot NAS offer the ability to extract specialized hardware-aware sub-network configurations from a task-specific super-network. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still under-explored. Popular methods decouple the super-network training from the sub-network search and use performance predictors to reduce the computational burden of searching on different hardware platforms. We propose a flexible search framework that automatically and efficiently finds optimal sub-networks that are optimized for different performance metrics and hardware configurations. Specifically, we show how evolutionary algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate architecture search in a multi-objective setting for various modalities including machine translation and image classification.
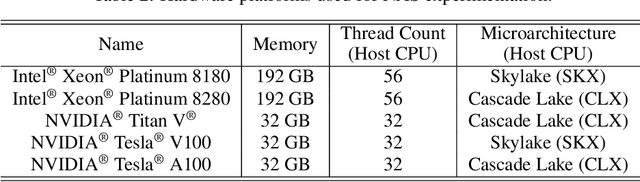
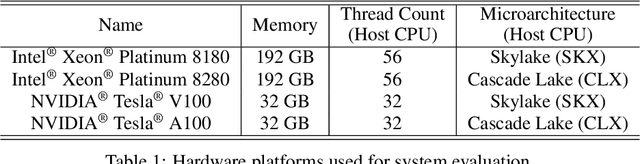
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022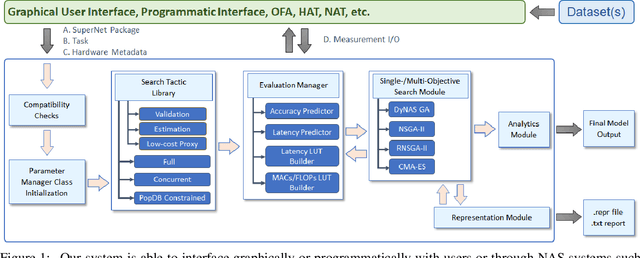
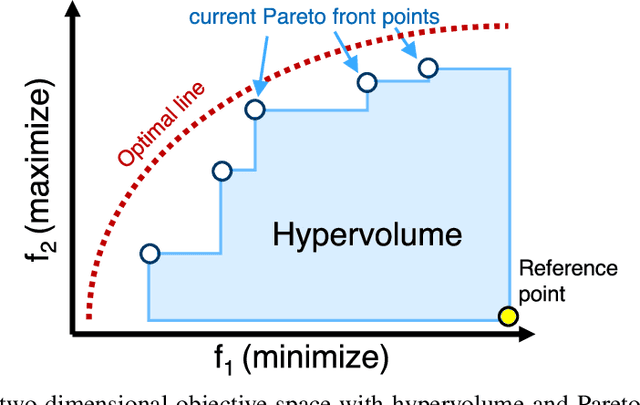
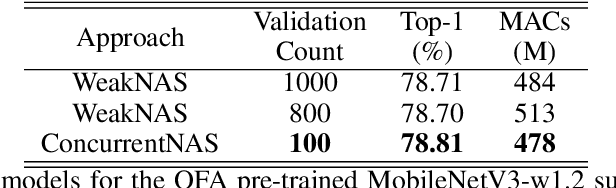
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.
Accelerating Neural Architecture Exploration Across Modalities Using Genetic Algorithms
Feb 25, 2022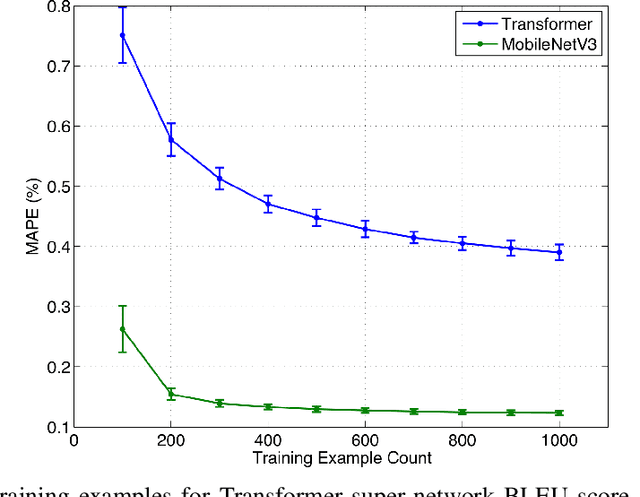
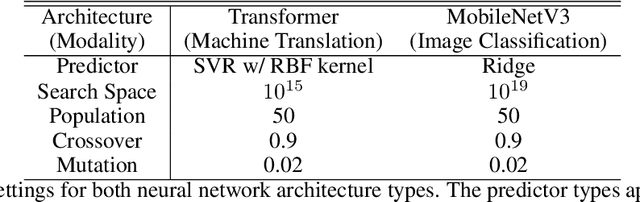
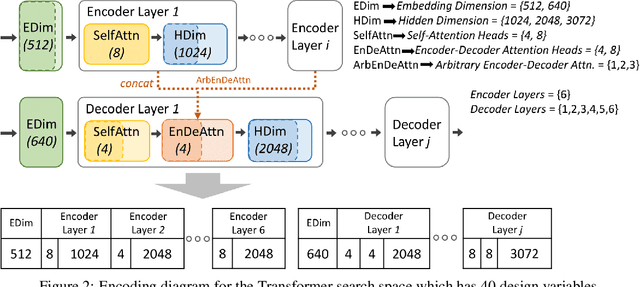
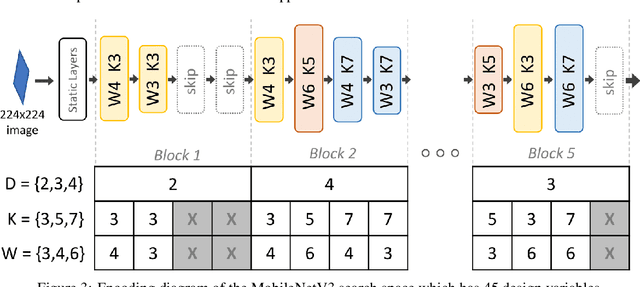
Neural architecture search (NAS), the study of automating the discovery of optimal deep neural network architectures for tasks in domains such as computer vision and natural language processing, has seen rapid growth in the machine learning research community. While there have been many recent advancements in NAS, there is still a significant focus on reducing the computational cost incurred when validating discovered architectures by making search more efficient. Evolutionary algorithms, specifically genetic algorithms, have a history of usage in NAS and continue to gain popularity versus other optimization approaches as a highly efficient way to explore the architecture objective space. Most NAS research efforts have centered around computer vision tasks and only recently have other modalities, such as the rapidly growing field of natural language processing, been investigated in depth. In this work, we show how genetic algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate multi-objective architectural exploration in a way that works in the modalities of both machine translation and image classification.
Structured Citation Trend Prediction Using Graph Neural Networks
Apr 06, 2021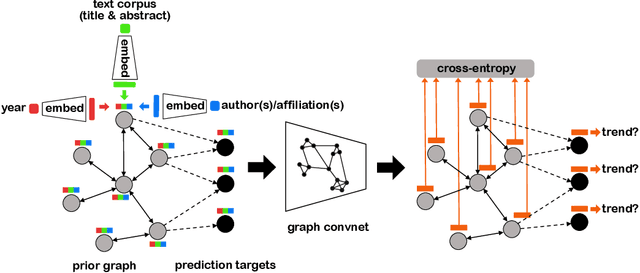
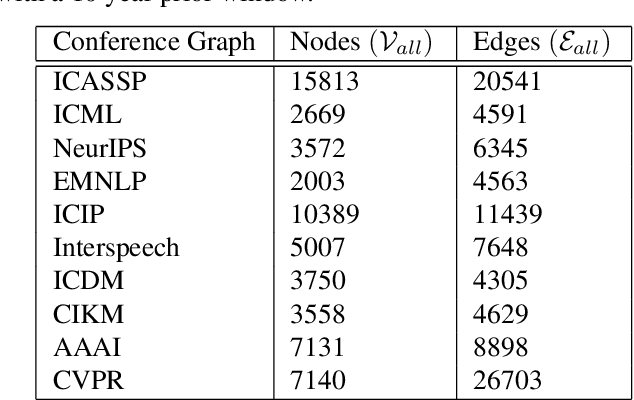
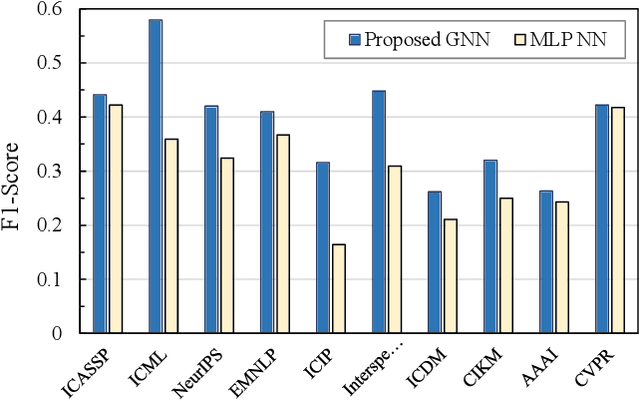

Academic citation graphs represent citation relationships between publications across the full range of academic fields. Top cited papers typically reveal future trends in their corresponding domains which is of importance to both researchers and practitioners. Prior citation prediction methods often require initial citation trends to be established and do not take advantage of the recent advancements in graph neural networks (GNNs). We present GNN-based architecture that predicts the top set of papers at the time of publication. For experiments, we curate a set of academic citation graphs for a variety of conferences and show that the proposed model outperforms other classic machine learning models in terms of the F1-score.