 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Multimodal Learning with Dual Adapters and Selective Pruning for Communication and Computational Efficiency
Mar 10, 2025Federated Learning (FL) enables collaborative learning across distributed clients while preserving data privacy. However, FL faces significant challenges when dealing with heterogeneous data distributions, which can lead to suboptimal global models that fail to generalize across diverse clients. In this work, we propose a novel framework designed to tackle these challenges by introducing a dual-adapter approach. The method utilizes a larger local adapter for client-specific personalization and a smaller global adapter to facilitate efficient knowledge sharing across clients. Additionally, we incorporate a pruning mechanism to reduce communication overhead by selectively removing less impactful parameters from the local adapter. Through extensive experiments on a range of vision and language tasks, our method demonstrates superior performance compared to existing approaches. It achieves higher test accuracy, lower performance variance among clients, and improved worst-case performance, all while significantly reducing communication and computation costs. Overall, the proposed method addresses the critical trade-off between model personalization and generalization, offering a scalable solution for real-world FL applications.
FLoRA: Enhancing Vision-Language Models with Parameter-Efficient Federated Learning
Apr 12, 2024



In the rapidly evolving field of artificial intelligence, multimodal models, e.g., integrating vision and language into visual-language models (VLMs), have become pivotal for many applications, ranging from image captioning to multimodal search engines. Among these models, the Contrastive Language-Image Pre-training (CLIP) model has demonstrated remarkable performance in understanding and generating nuanced relationships between text and images. However, the conventional training of such models often requires centralized aggregation of vast datasets, posing significant privacy and data governance challenges. To address these concerns, this paper proposes a novel approach that leverages Federated Learning and parameter-efficient adapters, i.e., Low-Rank Adaptation (LoRA), to train VLMs. This methodology preserves data privacy by training models across decentralized data sources and ensures model adaptability and efficiency through LoRA's parameter-efficient fine-tuning. Our approach accelerates training time by up to 34.72 times and requires 2.47 times less memory usage than full fine-tuning.
Evolving Zero Cost Proxies For Neural Architecture Scoring
Sep 15, 2022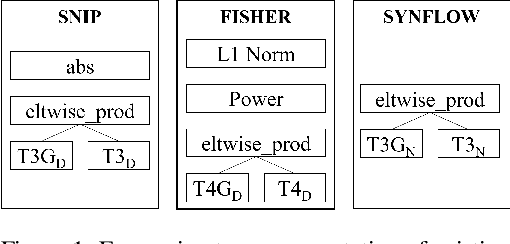
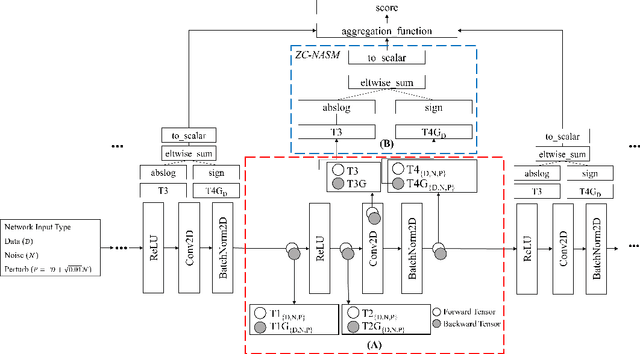
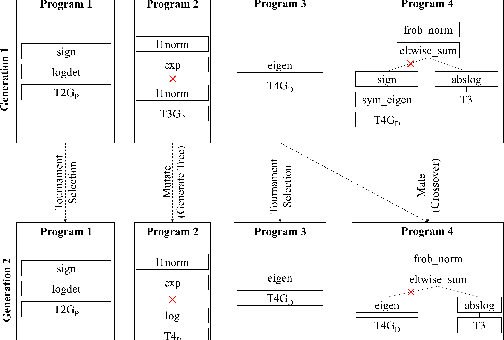
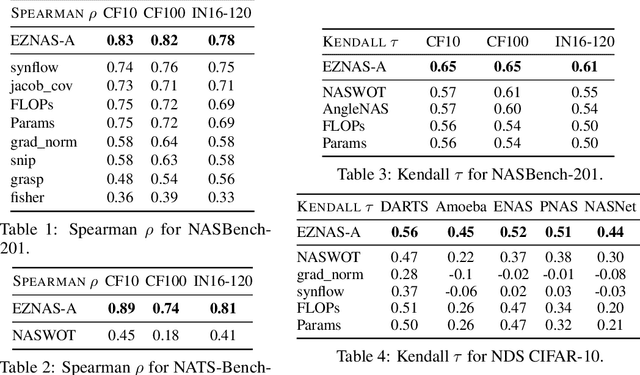
Neural Architecture Search (NAS) has significantly improved productivity in the design and deployment of neural networks (NN). As NAS typically evaluates multiple models by training them partially or completely, the improved productivity comes at the cost of significant carbon footprint. To alleviate this expensive training routine, zero-shot/cost proxies analyze an NN at initialization to generate a score, which correlates highly with its true accuracy. Zero-cost proxies are currently designed by experts conducting multiple cycles of empirical testing on possible algorithms, data-sets, and neural architecture design spaces. This lowers productivity and is an unsustainable approach towards zero-cost proxy design as deep learning use-cases diversify in nature. Additionally, existing zero-cost proxies fail to generalize across neural architecture design spaces. In this paper, we propose a genetic programming framework to automate the discovery of zero-cost proxies for neural architecture scoring. Our methodology efficiently discovers an interpretable and generalizable zero-cost proxy that gives state of the art score-accuracy correlation on all data-sets and search spaces of NASBench-201 and Network Design Spaces (NDS). We believe that this research indicates a promising direction towards automatically discovering zero-cost proxies that can work across network architecture design spaces, data-sets, and tasks.
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022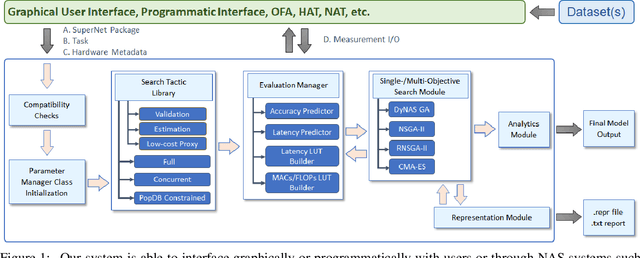
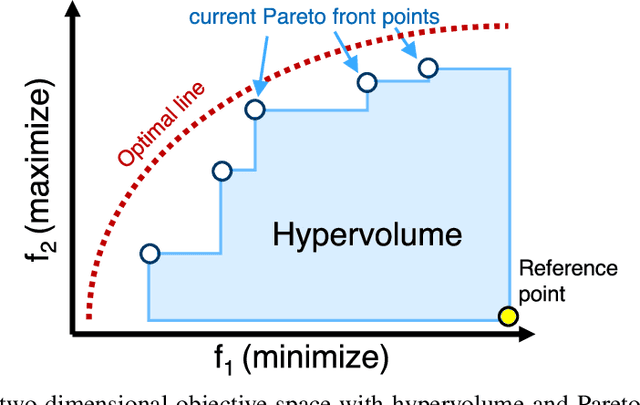
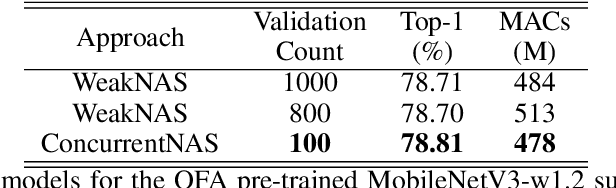
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.