 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Multimodal Learning with Dual Adapters and Selective Pruning for Communication and Computational Efficiency
Mar 10, 2025Federated Learning (FL) enables collaborative learning across distributed clients while preserving data privacy. However, FL faces significant challenges when dealing with heterogeneous data distributions, which can lead to suboptimal global models that fail to generalize across diverse clients. In this work, we propose a novel framework designed to tackle these challenges by introducing a dual-adapter approach. The method utilizes a larger local adapter for client-specific personalization and a smaller global adapter to facilitate efficient knowledge sharing across clients. Additionally, we incorporate a pruning mechanism to reduce communication overhead by selectively removing less impactful parameters from the local adapter. Through extensive experiments on a range of vision and language tasks, our method demonstrates superior performance compared to existing approaches. It achieves higher test accuracy, lower performance variance among clients, and improved worst-case performance, all while significantly reducing communication and computation costs. Overall, the proposed method addresses the critical trade-off between model personalization and generalization, offering a scalable solution for real-world FL applications.
MAGICS: Adversarial RL with Minimax Actors Guided by Implicit Critic Stackelberg for Convergent Neural Synthesis of Robot Safety
Sep 20, 2024While robust optimal control theory provides a rigorous framework to compute robot control policies that are provably safe, it struggles to scale to high-dimensional problems, leading to increased use of deep learning for tractable synthesis of robot safety. Unfortunately, existing neural safety synthesis methods often lack convergence guarantees and solution interpretability. In this paper, we present Minimax Actors Guided by Implicit Critic Stackelberg (MAGICS), a novel adversarial reinforcement learning (RL) algorithm that guarantees local convergence to a minimax equilibrium solution. We then build on this approach to provide local convergence guarantees for a general deep RL-based robot safety synthesis algorithm. Through both simulation studies on OpenAI Gym environments and hardware experiments with a 36-dimensional quadruped robot, we show that MAGICS can yield robust control policies outperforming the state-of-the-art neural safety synthesis methods.
FLoRA: Enhancing Vision-Language Models with Parameter-Efficient Federated Learning
Apr 12, 2024



In the rapidly evolving field of artificial intelligence, multimodal models, e.g., integrating vision and language into visual-language models (VLMs), have become pivotal for many applications, ranging from image captioning to multimodal search engines. Among these models, the Contrastive Language-Image Pre-training (CLIP) model has demonstrated remarkable performance in understanding and generating nuanced relationships between text and images. However, the conventional training of such models often requires centralized aggregation of vast datasets, posing significant privacy and data governance challenges. To address these concerns, this paper proposes a novel approach that leverages Federated Learning and parameter-efficient adapters, i.e., Low-Rank Adaptation (LoRA), to train VLMs. This methodology preserves data privacy by training models across decentralized data sources and ensures model adaptability and efficiency through LoRA's parameter-efficient fine-tuning. Our approach accelerates training time by up to 34.72 times and requires 2.47 times less memory usage than full fine-tuning.
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Dec 06, 2022

The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable "deep" methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial "disturbance" agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees
Feb 10, 2022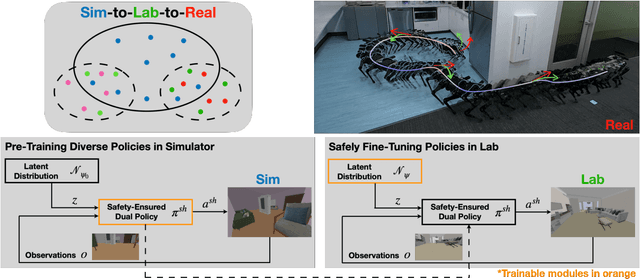

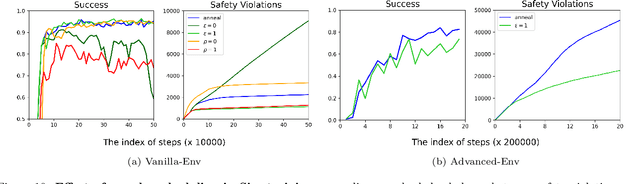

Safety is a critical component of autonomous systems and remains a challenge for learning-based policies to be utilized in the real world. In particular, policies learned using reinforcement learning often fail to generalize to novel environments due to unsafe behavior. In this paper, we propose Sim-to-Lab-to-Real to safely close the reality gap. To improve safety, we apply a dual policy setup where a performance policy is trained using the cumulative task reward and a backup (safety) policy is trained by solving the reach-avoid Bellman Equation based on Hamilton-Jacobi reachability analysis. In Sim-to-Lab transfer, we apply a supervisory control scheme to shield unsafe actions during exploration; in Lab-to-Real transfer, we leverage the Probably Approximately Correct (PAC)-Bayes framework to provide lower bounds on the expected performance and safety of policies in unseen environments. We empirically study the proposed framework for ego-vision navigation in two types of indoor environments including a photo-realistic one. We also demonstrate strong generalization performance through hardware experiments in real indoor spaces with a quadrupedal robot. See https://sites.google.com/princeton.edu/sim-to-lab-to-real for supplementary material.