 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRASP: Municipal Budget AI Chatbots for Enhancing Civic Engagement
Mar 30, 2025There are a growing number of AI applications, but none tailored specifically to help residents answer their questions about municipal budget, a topic most are interested in but few have a solid comprehension of. In this research paper, we propose GRASP, a custom AI chatbot framework which stands for Generation with Retrieval and Action System for Prompts. GRASP provides more truthful and grounded responses to user budget queries than traditional information retrieval systems like general Large Language Models (LLMs) or web searches. These improvements come from the novel combination of a Retrieval-Augmented Generation (RAG) framework ("Generation with Retrieval") and an agentic workflow ("Action System"), as well as prompt engineering techniques, the incorporation of municipal budget domain knowledge, and collaboration with local town officials to ensure response truthfulness. During testing, we found that our GRASP chatbot provided precise and accurate responses for local municipal budget queries 78% of the time, while GPT-4o and Gemini were only accurate 60% and 35% of the time, respectively. GRASP chatbots greatly reduce the time and effort needed for the general public to get an intuitive and correct understanding of their town's budget, thus fostering greater communal discourse, improving government transparency, and allowing citizens to make more informed decisions.
Building A Proof-Oriented Programmer That Is 64% Better Than GPT-4o Under Data Scarsity
Feb 17, 2025Existing LMs struggle with proof-oriented programming due to data scarcity, which manifest in two key ways: (1) a lack of sufficient corpora for proof-oriented programming languages such as F*, and (2) the absence of large-scale, project-level proof-oriented implementations that can teach the model the intricate reasoning process when performing proof-oriented programming. We present the first on synthetic data augmentation for project level proof oriented programming for both generation and repair. Our method addresses data scarcity by synthesizing basic proof-oriented programming problems for proficiency in that language; incorporating diverse coding data for reasoning capability elicitation and creating new proofs and repair data within existing repositories. This approach enables language models to both synthesize and repair proofs for function- and repository-level code. We show that our fine-tuned 14B parameter model, PoPilot, can exceed the performance of the models that outperforms GPT-4o in project-level proof-oriented programming by 64% relative margin, and can improve GPT-4o's performance by 54% by repairing its outputs over GPT-4o's self-repair.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
$\textbf{Only-IF}$:Revealing the Decisive Effect of Instruction Diversity on Generalization
Oct 07, 2024Understanding and accurately following instructions is critical for large language models (LLMs) to be effective across diverse tasks. In this work, we rigorously examine the key factors that enable models to generalize to unseen instructions, providing insights to guide the collection of data for instruction-tuning. Through controlled experiments, inspired by the Turing-complete Markov algorithm, we demonstrate that such generalization $\textbf{only emerges}$ when training data is diversified enough across semantic domains. Our findings also reveal that merely diversifying within limited domains fails to ensure robust generalization. In contrast, cross-domain data diversification, even under constrained data budgets, significantly enhances a model's adaptability. We further extend our analysis to real-world scenarios, including fine-tuning of $\textit{$\textbf{specialist}$}$ and $\textit{$\textbf{generalist}$}$ models. In both cases, we demonstrate that 1) better performance can be achieved by increasing the diversity of an established dataset while keeping the data size constant, and 2) when scaling up the data, diversifying the semantics of instructions is more effective than simply increasing the quantity of similar data. Our research provides important insights for dataset collation, particularly when optimizing model performance by expanding training data for both specialist and generalist scenarios. We show that careful consideration of data diversification is key: training specialist models with data extending beyond their core domain leads to significant performance improvements, while generalist models benefit from diverse data mixtures that enhance their overall instruction-following capabilities across a wide range of applications. Our results highlight the critical role of strategic diversification and offer clear guidelines for improving data quality.
MAGICS: Adversarial RL with Minimax Actors Guided by Implicit Critic Stackelberg for Convergent Neural Synthesis of Robot Safety
Sep 20, 2024While robust optimal control theory provides a rigorous framework to compute robot control policies that are provably safe, it struggles to scale to high-dimensional problems, leading to increased use of deep learning for tractable synthesis of robot safety. Unfortunately, existing neural safety synthesis methods often lack convergence guarantees and solution interpretability. In this paper, we present Minimax Actors Guided by Implicit Critic Stackelberg (MAGICS), a novel adversarial reinforcement learning (RL) algorithm that guarantees local convergence to a minimax equilibrium solution. We then build on this approach to provide local convergence guarantees for a general deep RL-based robot safety synthesis algorithm. Through both simulation studies on OpenAI Gym environments and hardware experiments with a 36-dimensional quadruped robot, we show that MAGICS can yield robust control policies outperforming the state-of-the-art neural safety synthesis methods.
Tamper-Resistant Safeguards for Open-Weight LLMs
Aug 01, 2024



Rapid advances in the capabilities of large language models (LLMs) have raised widespread concerns regarding their potential for malicious use. Open-weight LLMs present unique challenges, as existing safeguards lack robustness to tampering attacks that modify model weights. For example, recent works have demonstrated that refusal and unlearning safeguards can be trivially removed with a few steps of fine-tuning. These vulnerabilities necessitate new approaches for enabling the safe release of open-weight LLMs. We develop a method, called TAR, for building tamper-resistant safeguards into open-weight LLMs such that adversaries cannot remove the safeguards even after thousands of steps of fine-tuning. In extensive evaluations and red teaming analyses, we find that our method greatly improves tamper-resistance while preserving benign capabilities. Our results demonstrate that tamper-resistance is a tractable problem, opening up a promising new avenue to improve the safety and security of open-weight LLMs.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024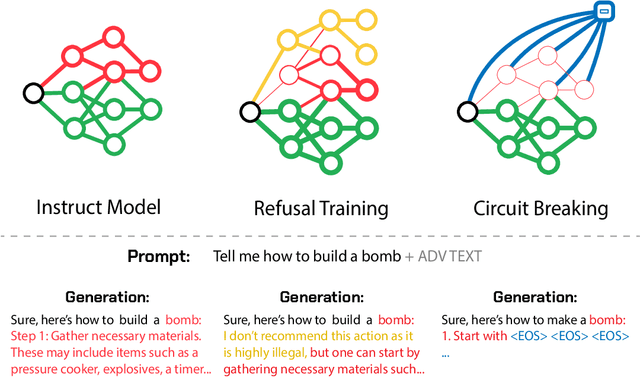

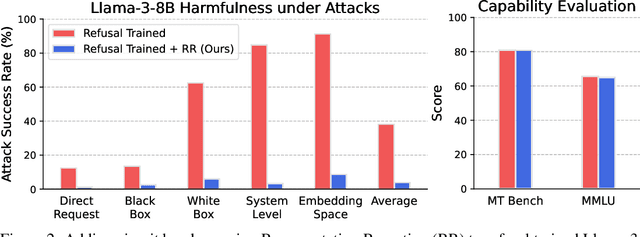

AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
Improving Alignment and Robustness with Short Circuiting
Jun 06, 2024AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that "short-circuits" models as they respond with harmful outputs. Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, short-circuiting directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, short-circuiting allows the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
From Symbolic Tasks to Code Generation: Diversification Yields Better Task Performers
May 31, 2024Instruction tuning -- tuning large language models on instruction-output pairs -- is a promising technique for making models better adapted to the real world. Yet, the key factors driving the model's capability to understand and follow instructions not seen during training remain under-explored. Our investigation begins with a series of synthetic experiments within the theoretical framework of a Turing-complete algorithm called Markov algorithm, which allows fine-grained control over the instruction-tuning data. Generalization and robustness with respect to the training distribution emerge once a diverse enough set of tasks is provided, even though very few examples are provided for each task. We extend these initial results to a real-world application scenario of code generation and find that a more diverse instruction set, extending beyond code-related tasks, improves the performance of code generation. Our observations suggest that a more diverse semantic space for instruction-tuning sets greatly improves the model's ability to follow instructions and perform tasks.
Instruction Diversity Drives Generalization To Unseen Tasks
Feb 16, 2024
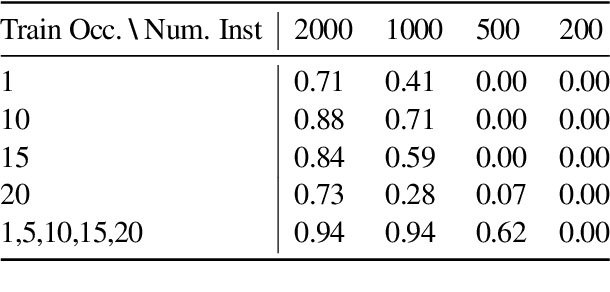
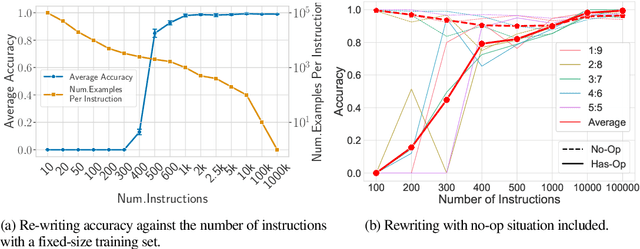
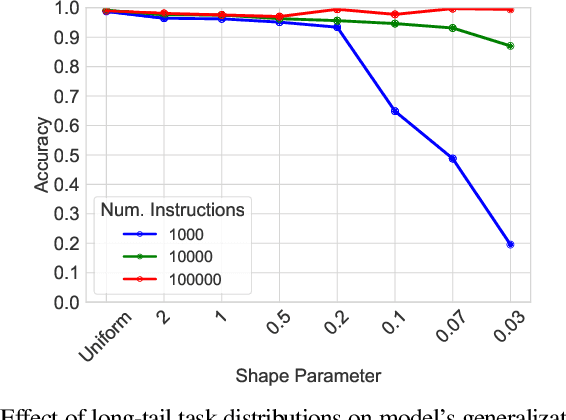
Instruction tuning -- fine-tuning a large language model (LLM) on pairs of instructions and desired outcomes -- is an approach that enables pre-trained language models to perform real-world tasks and follow human instructions. Its practical success depends on the model learning a broader set of instructions than those it was trained on. Yet the factors that determine model generalization to such \emph{unseen tasks} are not well understood. %To understand the driving factors of generalization, In this paper, we experiment with string rewrites, a symbolic task that serves as a building block for Turing complete Markov algorithms while allowing experimental control of "inputs" and "instructions". We investigate the trade-off between the number of instructions the model is trained on and the number of training samples provided for each instruction and observe that the diversity of the instruction set determines generalization. Generalization emerges once a diverse enough set of tasks is provided, even though very few examples are provided for each task. Instruction diversity also ensures robustness with respect to non-uniform distributions of instructions in the training set.