 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Diffusion Solver for Combinatorial Optimization via Combinatorial Adjoint Matching
May 29, 2026Diffusion-based neural solvers have shown strong promise for combinatorial optimization (CO), but existing methods typically rely on supervised training with large collections of near-optimal solutions. In this work, we extend adjoint-based trajectory optimization methods to discrete combinatorial domains. We formulate diffusion-based CO as a stochastic control problem over Continuous-Time Markov Chains and introduce discrete adjoint dynamics for propagating optimization signals through discrete generative trajectories. Building on this formulation, we propose Combinatorial Adjoint Matching (CAM), an unsupervised training framework for discrete diffusion solvers with structured and low-variance trajectory-level optimization signals. Empirically, CAM consistently outperforms existing unsupervised diffusion baselines and achieves performance competitive with strong supervised diffusion solvers and even traditional solvers across diverse combinatorial optimization problems. Our code is available at https://github.com/Shengyu-Feng/CAM.
Agentic Separation Logic Specification Synthesis
May 26, 2026Specification synthesis, the task of automatically inferring formal specifications from program implementations and natural language, is important for refactoring, transpilation, optimization, and verification, yet remains an open challenge for large C++ repositories. Existing LLM-based approaches fail to simultaneously scale to such repositories, produce specifications expressive enough to capture systems-code features such as dynamic memory and heap-allocated data structures, and systematically validate those specifications to rule out incorrect candidates. We present Spec-Agent, an agentic system for synthesizing expressive, well-validated specifications across large C++ codebases. Spec-Agent targets a ladder of specification languages: propositional logic, first-order logic, propositional separation logic, and first-order separation logic. For each function, Spec-Agent uses static analysis and runtime heap tracing to select the appropriate target specification language, generalizes existing functional tests into fuzz harnesses, and iteratively refines LLM-generated candidates via counterexample-guided feedback. We evaluate Spec-Agent on open source C++ codebases comprising millions of lines of code. Spec-Agent synthesizes valid specifications for 85% of target functions, with no false positives observed under fuzzing and expert validation, outperforming Claude Code Opus 4.6 at 10x lower token cost.
TRACE: Capability-Targeted Agentic Training
Apr 07, 2026Large Language Models (LLMs) deployed in agentic environments must exercise multiple capabilities across different task instances, where a capability is performing one or more actions in a trajectory that are necessary for successfully solving a subset of tasks in the environment. Many existing approaches either rely on synthetic training data that is not targeted to the model's actual capability deficits in the target environment or train directly on the target environment, where the model needs to implicitly learn the capabilities across tasks. We introduce TRACE (Turning Recurrent Agent failures into Capability-targeted training Environments), an end-to-end system for environment-specific agent self-improvement. TRACE contrasts successful and failed trajectories to automatically identify lacking capabilities, synthesizes a targeted training environment for each that rewards whether the capability was exercised, and trains a LoRA adapter via RL on each synthetic environment, routing to the relevant adapter at inference. Empirically, TRACE generalizes across different environments, improving over the base agent by +14.1 points on $τ^2$-bench (customer service) and +7 perfect scores on ToolSandbox (tool use), outperforming the strongest baseline by +7.4 points and +4 perfect scores, respectively. Given the same number of rollouts, TRACE scales more efficiently than baselines, outperforming GRPO and GEPA by +9.2 and +7.4 points on $τ^2$-bench.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
DINGO: Constrained Inference for Diffusion LLMs
May 29, 2025Diffusion LLMs have emerged as a promising alternative to conventional autoregressive LLMs, offering significant potential for improved runtime efficiency. However, existing diffusion models lack the ability to provably enforce user-specified formal constraints, such as regular expressions, which makes them unreliable for tasks that require structured outputs, such as fixed-schema JSON generation. Unlike autoregressive models that generate tokens sequentially, diffusion LLMs predict a block of tokens in parallel. This parallelism makes traditional constrained decoding algorithms, which are designed for sequential token prediction, ineffective at preserving the true output distribution. To address this limitation, we propose DINGO, a dynamic programming-based constrained decoding strategy that is both efficient and provably distribution-preserving. DINGO enables sampling of output strings with the highest probability under the model's predicted distribution, while strictly satisfying any user-specified regular expression. On standard symbolic math and JSON generation benchmarks, DINGO achieves up to a 68 percentage point improvement over unconstrained inference
Learning a Pessimistic Reward Model in RLHF
May 26, 2025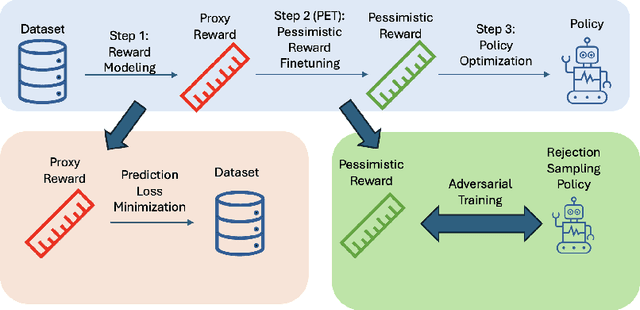


This work proposes `PET', a novel pessimistic reward fine-tuning method, to learn a pessimistic reward model robust against reward hacking in offline reinforcement learning from human feedback (RLHF). Traditional reward modeling techniques in RLHF train an imperfect reward model, on which a KL regularization plays a pivotal role in mitigating reward hacking when optimizing a policy. Such an intuition-based method still suffers from reward hacking, and the policies with large KL divergence from the dataset distribution are excluded during learning. In contrast, we show that when optimizing a policy on a pessimistic reward model fine-tuned through PET, reward hacking can be prevented without relying on any regularization. We test our methods on the standard TL;DR summarization dataset. We find that one can learn a high-quality policy on our pessimistic reward without using any regularization. Such a policy has a high KL divergence from the dataset distribution while having high performance in practice. In summary, our work shows the feasibility of learning a pessimistic reward model against reward hacking. The agent can greedily search for the policy with a high pessimistic reward without suffering from reward hacking.
SATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
May 20, 2025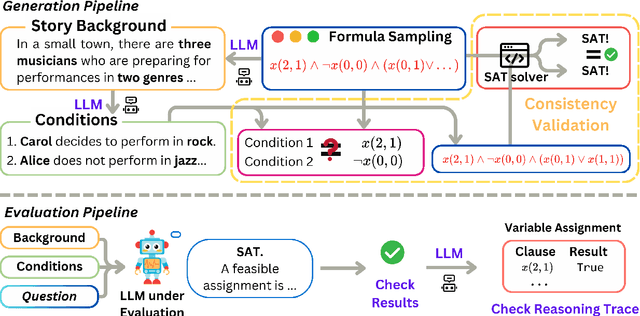



We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
May 16, 2025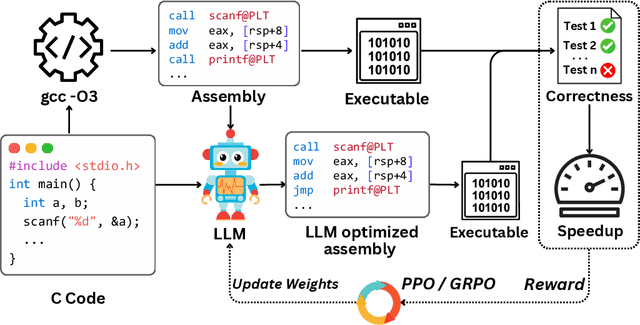
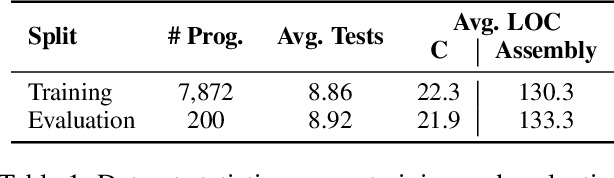


Large language models (LLMs) have demonstrated strong performance across a wide range of programming tasks, yet their potential for code optimization remains underexplored. This work investigates whether LLMs can optimize the performance of assembly code, where fine-grained control over execution enables improvements that are difficult to express in high-level languages. We present a reinforcement learning framework that trains LLMs using Proximal Policy Optimization (PPO), guided by a reward function that considers both functional correctness, validated through test cases, and execution performance relative to the industry-standard compiler gcc -O3. To support this study, we introduce a benchmark of 8,072 real-world programs. Our model, Qwen2.5-Coder-7B-PPO, achieves 96.0% test pass rates and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all 20 other models evaluated, including Claude-3.7-sonnet. These results indicate that reinforcement learning can unlock the potential of LLMs to serve as effective optimizers for assembly code performance.
SweRank: Software Issue Localization with Code Ranking
May 07, 2025Software issue localization, the task of identifying the precise code locations (files, classes, or functions) relevant to a natural language issue description (e.g., bug report, feature request), is a critical yet time-consuming aspect of software development. While recent LLM-based agentic approaches demonstrate promise, they often incur significant latency and cost due to complex multi-step reasoning and relying on closed-source LLMs. Alternatively, traditional code ranking models, typically optimized for query-to-code or code-to-code retrieval, struggle with the verbose and failure-descriptive nature of issue localization queries. To bridge this gap, we introduce SweRank, an efficient and effective retrieve-and-rerank framework for software issue localization. To facilitate training, we construct SweLoc, a large-scale dataset curated from public GitHub repositories, featuring real-world issue descriptions paired with corresponding code modifications. Empirical results on SWE-Bench-Lite and LocBench show that SweRank achieves state-of-the-art performance, outperforming both prior ranking models and costly agent-based systems using closed-source LLMs like Claude-3.5. Further, we demonstrate SweLoc's utility in enhancing various existing retriever and reranker models for issue localization, establishing the dataset as a valuable resource for the community.
VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Apr 22, 2025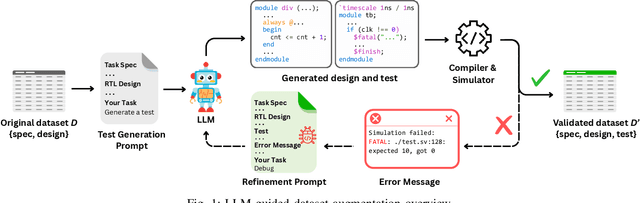

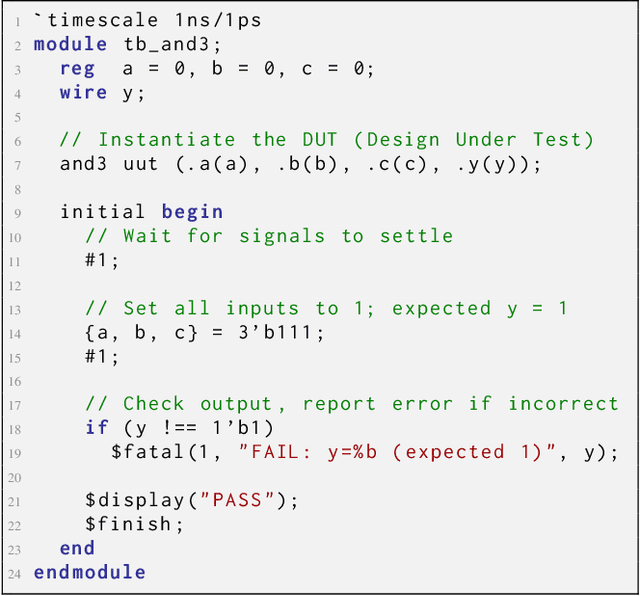
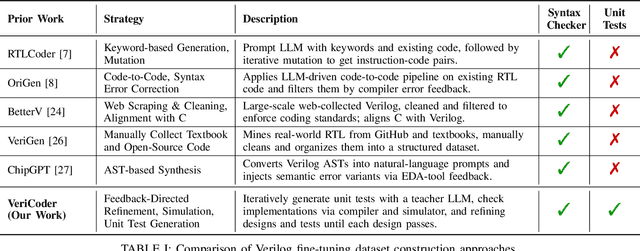
Recent advances in Large Language Models (LLMs) have sparked growing interest in applying them to Electronic Design Automation (EDA) tasks, particularly Register Transfer Level (RTL) code generation. While several RTL datasets have been introduced, most focus on syntactic validity rather than functional validation with tests, leading to training examples that compile but may not implement the intended behavior. We present VERICODER, a model for RTL code generation fine-tuned on a dataset validated for functional correctness. This fine-tuning dataset is constructed using a novel methodology that combines unit test generation with feedback-directed refinement. Given a natural language specification and an initial RTL design, we prompt a teacher model (GPT-4o-mini) to generate unit tests and iteratively revise the RTL design based on its simulation results using the generated tests. If necessary, the teacher model also updates the tests to ensure they comply with the natural language specification. As a result of this process, every example in our dataset is functionally validated, consisting of a natural language description, an RTL implementation, and passing tests. Fine-tuned on this dataset of over 125,000 examples, VERICODER achieves state-of-the-art metrics in functional correctness on VerilogEval and RTLLM, with relative gains of up to 71.7% and 27.4% respectively. An ablation study further shows that models trained on our functionally validated dataset outperform those trained on functionally non-validated datasets, underscoring the importance of high-quality datasets in RTL code generation.