 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Apr 22, 2025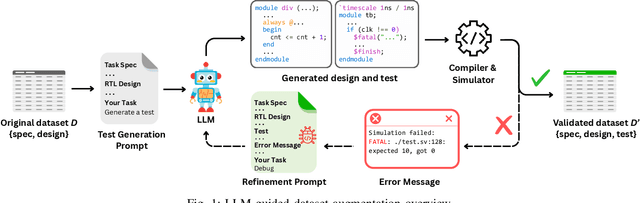

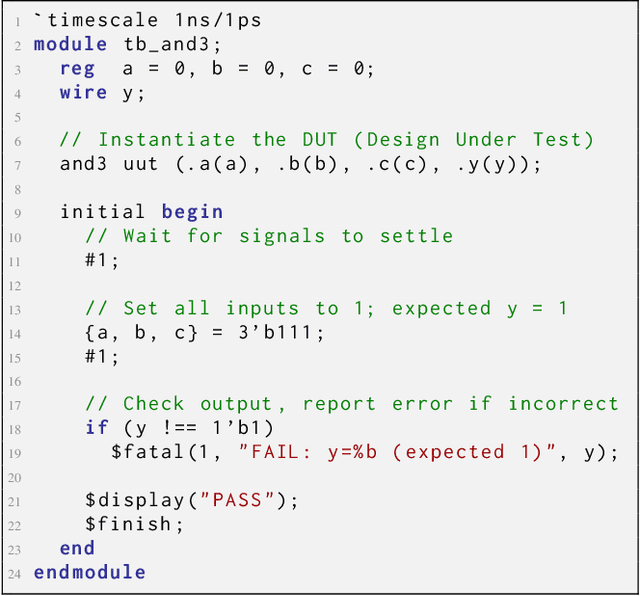
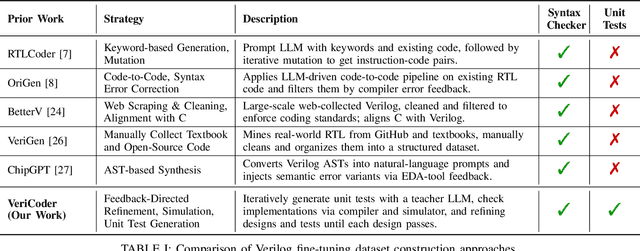
Recent advances in Large Language Models (LLMs) have sparked growing interest in applying them to Electronic Design Automation (EDA) tasks, particularly Register Transfer Level (RTL) code generation. While several RTL datasets have been introduced, most focus on syntactic validity rather than functional validation with tests, leading to training examples that compile but may not implement the intended behavior. We present VERICODER, a model for RTL code generation fine-tuned on a dataset validated for functional correctness. This fine-tuning dataset is constructed using a novel methodology that combines unit test generation with feedback-directed refinement. Given a natural language specification and an initial RTL design, we prompt a teacher model (GPT-4o-mini) to generate unit tests and iteratively revise the RTL design based on its simulation results using the generated tests. If necessary, the teacher model also updates the tests to ensure they comply with the natural language specification. As a result of this process, every example in our dataset is functionally validated, consisting of a natural language description, an RTL implementation, and passing tests. Fine-tuned on this dataset of over 125,000 examples, VERICODER achieves state-of-the-art metrics in functional correctness on VerilogEval and RTLLM, with relative gains of up to 71.7% and 27.4% respectively. An ablation study further shows that models trained on our functionally validated dataset outperform those trained on functionally non-validated datasets, underscoring the importance of high-quality datasets in RTL code generation.
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis
Mar 29, 2025Inductive program synthesis, or programming by example, requires synthesizing functions from input-output examples that generalize to unseen inputs. While large language model agents have shown promise in programming tasks guided by natural language, their ability to perform inductive program synthesis is underexplored. Existing evaluation protocols rely on static sets of examples and held-out tests, offering no feedback when synthesized functions are incorrect and failing to reflect real-world scenarios such as reverse engineering. We propose CodeARC, the Code Abstraction and Reasoning Challenge, a new evaluation framework where agents interact with a hidden target function by querying it with new inputs, synthesizing candidate functions, and iteratively refining their solutions using a differential testing oracle. This interactive setting encourages agents to perform function calls and self-correction based on feedback. We construct the first large-scale benchmark for general-purpose inductive program synthesis, featuring 1114 functions. Among 18 models evaluated, o3-mini performs best with a success rate of 52.7%, highlighting the difficulty of this task. Fine-tuning LLaMA-3.1-8B-Instruct on curated synthesis traces yields up to a 31% relative performance gain. CodeARC provides a more realistic and challenging testbed for evaluating LLM-based program synthesis and inductive reasoning.
EquiBench: Benchmarking Code Reasoning Capabilities of Large Language Models via Equivalence Checking
Feb 18, 2025



Equivalence checking, i.e., determining whether two programs produce identical outputs for all possible inputs, underpins a broad range of applications, including software refactoring, testing, and optimization. We present the task of equivalence checking as a new way to evaluate the code reasoning abilities of large language models (LLMs). We introduce EquiBench, a dataset of 2400 program pairs spanning four programming languages and six equivalence categories. These pairs are systematically generated through program analysis, compiler scheduling, and superoptimization, covering nontrivial structural transformations that demand deep semantic reasoning beyond simple syntactic variations. Our evaluation of 17 state-of-the-art LLMs shows that OpenAI o3-mini achieves the highest overall accuracy of 78.0%. In the most challenging categories, the best accuracies are 62.3% and 68.8%, only modestly above the 50% random baseline for binary classification, indicating significant room for improvement in current models' code reasoning capabilities.
Improving Parallel Program Performance Through DSL-Driven Code Generation with LLM Optimizers
Oct 21, 2024Mapping computations to processors and assigning data to memory are critical for maximizing performance in parallel programming. These mapping decisions are managed through the development of specialized low-level system code, called mappers, crafted by performance engineers. Each mapper is tailored to a specific application and optimized for the underlying machine architecture, a process that requires days of refinement and tuning from an expert. Despite advances in system research, automating mapper generation remains a challenge due to the complexity of making millions of decisions to find the optimal solution and generate the solution as code. We introduce an approach that leverages recent advances in LLM-based optimizers for mapper design. In under ten minutes, our method automatically discovers mappers that surpass human expert designs in scientific applications by up to 1.34X speedup. For parallel matrix multiplication algorithms, our mapper achieves up to 1.31X of the expert-designed solution. To achieve this, we simplify the complexity of low-level code generation by introducing a domain-specific language (DSL) that abstracts the low-level system programming details and defines a structured search space for LLMs to explore. To maximize the application performance, we use an LLM optimizer to improve an agentic system that generates the mapper code. As a result, this approach significantly reduces the workload for performance engineers while achieving substantial performance gains across diverse applications. Finally, our results demonstrate the effectiveness of LLM-based optimization in system design and suggest its potential for addressing other complex system challenges.