 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory
Jan 26, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly when augmented with search mechanisms that enable systematic exploration of external knowledge bases. The field has evolved from traditional retrieval-augmented generation (RAG) frameworks to more sophisticated search-based frameworks that orchestrate multi-step reasoning through explicit search strategies. However, existing search frameworks still rely heavily on implicit natural language reasoning to determine search strategies and how to leverage retrieved information across reasoning steps. This reliance on implicit reasoning creates fundamental challenges for managing dependencies between sub-questions, efficiently reusing previously retrieved knowledge, and learning optimal search strategies through reinforcement learning. To address these limitations, we propose Dep-Search, a dependency-aware search framework that advances beyond existing search frameworks by integrating structured reasoning, retrieval, and persistent memory through GRPO. Dep-Search introduces explicit control mechanisms that enable the model to decompose questions with dependency relationships, retrieve information when needed, access previously stored knowledge from memory, and summarize long reasoning contexts into reusable memory entries. Through extensive experiments on seven diverse question answering datasets, we demonstrate that Dep-Search significantly enhances LLMs' ability to tackle complex multi-hop reasoning tasks, achieving substantial improvements over strong baselines across different model scales.
NC2C: Automated Convexification of Generic Non-Convex Optimization Problems
Jan 08, 2026Non-convex optimization problems are pervasive across mathematical programming, engineering design, and scientific computing, often posing intractable challenges for traditional solvers due to their complex objective functions and constrained landscapes. To address the inefficiency of manual convexification and the over-reliance on expert knowledge, we propose NC2C, an LLM-based end-to-end automated framework designed to transform generic non-convex optimization problems into solvable convex forms using large language models. NC2C leverages LLMs' mathematical reasoning capabilities to autonomously detect non-convex components, select optimal convexification strategies, and generate rigorous convex equivalents. The framework integrates symbolic reasoning, adaptive transformation techniques, and iterative validation, equipped with error correction loops and feasibility domain correction mechanisms to ensure the robustness and validity of transformed problems. Experimental results on a diverse dataset of 100 generic non-convex problems demonstrate that NC2C achieves an 89.3\% execution rate and a 76\% success rate in producing feasible, high-quality convex transformations. This outperforms baseline methods by a significant margin, highlighting NC2C's ability to leverage LLMs for automated non-convex to convex transformation, reduce expert dependency, and enable efficient deployment of convex solvers for previously intractable optimization tasks.
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs
Jan 08, 2026Large Language Models (LLMs) augmented with external tools have demonstrated remarkable capabilities in complex reasoning tasks. However, existing frameworks rely heavily on natural language reasoning to determine when tools can be invoked and whether their results should be committed, lacking formal guarantees for logical safety and verifiability. We present \textbf{ToolGate}, a forward execution framework that provides logical safety guarantees and verifiable state evolution for LLM tool calling. ToolGate maintains an explicit symbolic state space as a typed key-value mapping representing trusted world information throughout the reasoning process. Each tool is formalized as a Hoare-style contract consisting of a precondition and a postcondition, where the precondition gates tool invocation by checking whether the current state satisfies the required conditions, and the postcondition determines whether the tool's result can be committed to update the state through runtime verification. Our approach guarantees that the symbolic state evolves only through verified tool executions, preventing invalid or hallucinated results from corrupting the world representation. Experimental validation demonstrates that ToolGate significantly improves the reliability and verifiability of tool-augmented LLM systems while maintaining competitive performance on complex multi-step reasoning tasks. This work establishes a foundation for building more trustworthy and debuggable AI systems that integrate language models with external tools.
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis
Mar 29, 2025Inductive program synthesis, or programming by example, requires synthesizing functions from input-output examples that generalize to unseen inputs. While large language model agents have shown promise in programming tasks guided by natural language, their ability to perform inductive program synthesis is underexplored. Existing evaluation protocols rely on static sets of examples and held-out tests, offering no feedback when synthesized functions are incorrect and failing to reflect real-world scenarios such as reverse engineering. We propose CodeARC, the Code Abstraction and Reasoning Challenge, a new evaluation framework where agents interact with a hidden target function by querying it with new inputs, synthesizing candidate functions, and iteratively refining their solutions using a differential testing oracle. This interactive setting encourages agents to perform function calls and self-correction based on feedback. We construct the first large-scale benchmark for general-purpose inductive program synthesis, featuring 1114 functions. Among 18 models evaluated, o3-mini performs best with a success rate of 52.7%, highlighting the difficulty of this task. Fine-tuning LLaMA-3.1-8B-Instruct on curated synthesis traces yields up to a 31% relative performance gain. CodeARC provides a more realistic and challenging testbed for evaluating LLM-based program synthesis and inductive reasoning.
EquiBench: Benchmarking Code Reasoning Capabilities of Large Language Models via Equivalence Checking
Feb 18, 2025



Equivalence checking, i.e., determining whether two programs produce identical outputs for all possible inputs, underpins a broad range of applications, including software refactoring, testing, and optimization. We present the task of equivalence checking as a new way to evaluate the code reasoning abilities of large language models (LLMs). We introduce EquiBench, a dataset of 2400 program pairs spanning four programming languages and six equivalence categories. These pairs are systematically generated through program analysis, compiler scheduling, and superoptimization, covering nontrivial structural transformations that demand deep semantic reasoning beyond simple syntactic variations. Our evaluation of 17 state-of-the-art LLMs shows that OpenAI o3-mini achieves the highest overall accuracy of 78.0%. In the most challenging categories, the best accuracies are 62.3% and 68.8%, only modestly above the 50% random baseline for binary classification, indicating significant room for improvement in current models' code reasoning capabilities.
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
Oct 02, 2024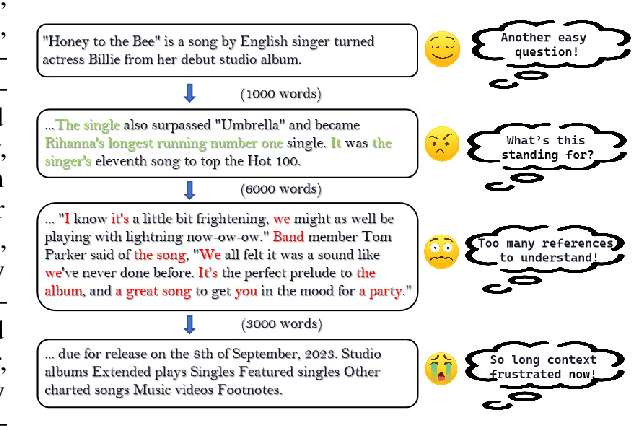
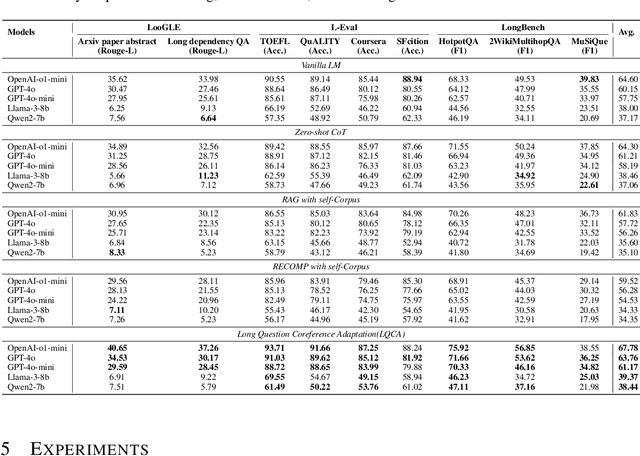
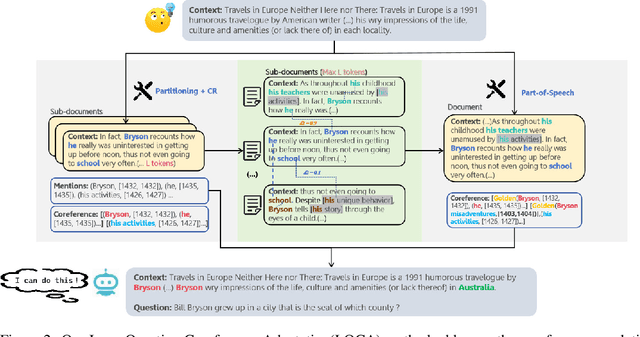
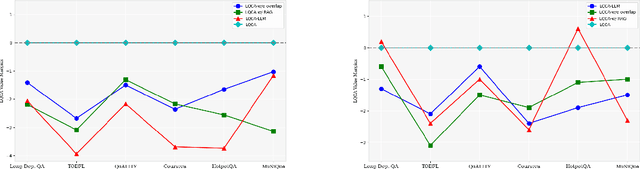
Large language models (LLMs) have shown remarkable capabilities in natural language processing; however, they still face difficulties when tasked with understanding lengthy contexts and executing effective question answering. These challenges often arise due to the complexity and ambiguity present in longer texts. To enhance the performance of LLMs in such scenarios, we introduce the Long Question Coreference Adaptation (LQCA) method. This innovative framework focuses on coreference resolution tailored to long contexts, allowing the model to identify and manage references effectively. The LQCA method encompasses four key steps: resolving coreferences within sub-documents, computing the distances between mentions, defining a representative mention for coreference, and answering questions through mention replacement. By processing information systematically, the framework provides easier-to-handle partitions for LLMs, promoting better understanding. Experimental evaluations on a range of LLMs and datasets have yielded positive results, with a notable improvements on OpenAI-o1-mini and GPT-4o models, highlighting the effectiveness of leveraging coreference resolution to bridge context gaps in question answering.
Unveiling the Spectrum of Data Contamination in Language Models: A Survey from Detection to Remediation
Jun 20, 2024

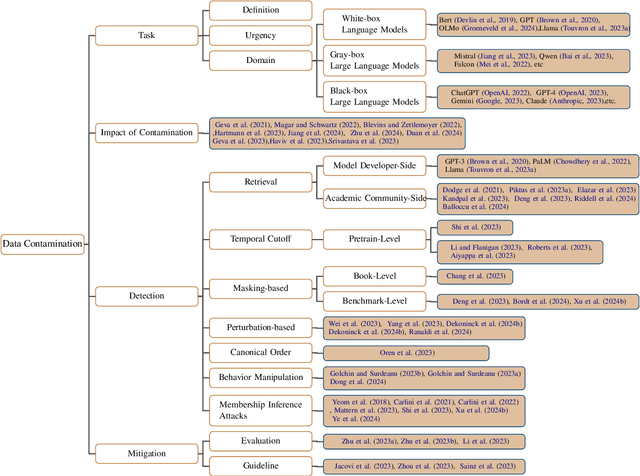
Data contamination has garnered increased attention in the era of large language models (LLMs) due to the reliance on extensive internet-derived training corpora. The issue of training corpus overlap with evaluation benchmarks--referred to as contamination--has been the focus of significant recent research. This body of work aims to identify contamination, understand its impacts, and explore mitigation strategies from diverse perspectives. However, comprehensive studies that provide a clear pathway from foundational concepts to advanced insights are lacking in this nascent field. Therefore, we present a comprehensive survey in the field of data contamination, laying out the key issues, methodologies, and findings to date, and highlighting areas in need of further research and development. In particular, we begin by examining the effects of data contamination across various stages and forms. We then provide a detailed analysis of current contamination detection methods, categorizing them to highlight their focus, assumptions, strengths, and limitations. We also discuss mitigation strategies, offering a clear guide for future research. This survey serves as a succinct overview of the most recent advancements in data contamination research, providing a straightforward guide for the benefit of future research endeavors.
MemDPT: Differential Privacy for Memory Efficient Language Models
Jun 16, 2024
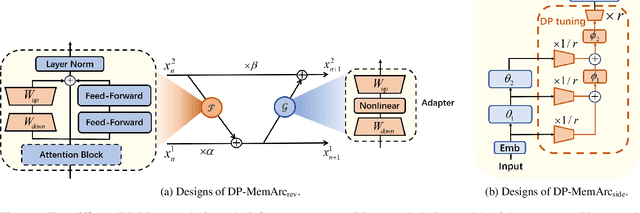
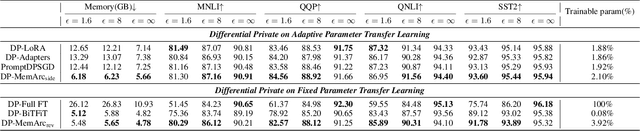
Large language models have consistently demonstrated remarkable performance across a wide spectrum of applications. Nonetheless, the deployment of these models can inadvertently expose user privacy to potential risks. The substantial memory demands of these models during training represent a significant resource consumption challenge. The sheer size of these models imposes a considerable burden on memory resources, which is a matter of significant concern in practice. In this paper, we present an innovative training framework MemDPT that not only reduces the memory cost of large language models but also places a strong emphasis on safeguarding user data privacy. MemDPT provides edge network and reverse network designs to accommodate various differential privacy memory-efficient fine-tuning schemes. Our approach not only achieves $2 \sim 3 \times$ memory optimization but also provides robust privacy protection, ensuring that user data remains secure and confidential. Extensive experiments have demonstrated that MemDPT can effectively provide differential privacy efficient fine-tuning across various task scenarios.
Tool-Planner: Dynamic Solution Tree Planning for Large Language Model with Tool Clustering
Jun 06, 2024



Large language models (LLMs) have demonstrated exceptional reasoning capabilities, enabling them to solve various complex problems. Recently, this ability has been applied to the paradigm of tool learning. Tool learning involves providing examples of tool usage and their corresponding functions, allowing LLMs to formulate plans and demonstrate the process of invoking and executing each tool. LLMs can address tasks that they cannot complete independently, thereby enhancing their potential across different tasks. However, this approach faces two key challenges. First, redundant error correction leads to unstable planning and long execution time. Additionally, designing a correct plan among multiple tools is also a challenge in tool learning. To address these issues, we propose Tool-Planner, a task-processing framework based on toolkits. Tool-Planner groups tools based on the API functions with the same function into a toolkit and allows LLMs to implement planning across the various toolkits. When a tool error occurs, the language model can reselect and adjust tools based on the toolkit. Experiments show that our approach demonstrates a high pass and win rate across different datasets and optimizes the planning scheme for tool learning in models such as GPT-4 and Claude 3, showcasing the potential of our method.
SPA: Towards A Computational Friendly Cloud-Base and On-Devices Collaboration Seq2seq Personalized Generation
Mar 11, 2024Large language models(LLMs) have shown its outperforming ability on various tasks and question answering. However, LLMs require high computation cost and large memory cost. At the same time, LLMs may cause privacy leakage when training or prediction procedure contains sensitive information. In this paper, we propose SPA(Side Plugin Adaption), a lightweight architecture for fast on-devices inference and privacy retaining on the constraints of strict on-devices computation and memory constraints. Compared with other on-devices seq2seq generation, SPA could make a fast and stable inference on low-resource constraints, allowing it to obtain cost effiency. Our method establish an interaction between a pretrained LLMs on-cloud and additive parameters on-devices, which could provide the knowledge on both pretrained LLMs and private personal feature.Further more, SPA provides a framework to keep feature-base parameters on private guaranteed but low computational devices while leave the parameters containing general information on the high computational devices.