 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation
Feb 26, 2024
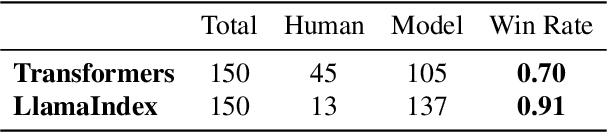
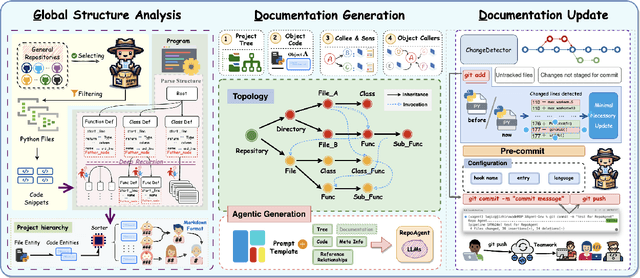
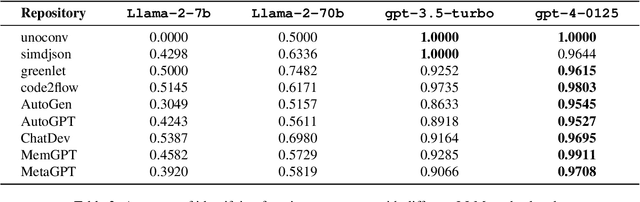
Generative models have demonstrated considerable potential in software engineering, particularly in tasks such as code generation and debugging. However, their utilization in the domain of code documentation generation remains underexplored. To this end, we introduce RepoAgent, a large language model powered open-source framework aimed at proactively generating, maintaining, and updating code documentation. Through both qualitative and quantitative evaluations, we have validated the effectiveness of our approach, showing that RepoAgent excels in generating high-quality repository-level documentation. The code and results are publicly accessible at https://github.com/OpenBMB/RepoAgent.
Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution
Jan 25, 2024This paper introduces Investigate-Consolidate-Exploit (ICE), a novel strategy for enhancing the adaptability and flexibility of AI agents through inter-task self-evolution. Unlike existing methods focused on intra-task learning, ICE promotes the transfer of knowledge between tasks for genuine self-evolution, similar to human experience learning. The strategy dynamically investigates planning and execution trajectories, consolidates them into simplified workflows and pipelines, and exploits them for improved task execution. Our experiments on the XAgent framework demonstrate ICE's effectiveness, reducing API calls by as much as 80% and significantly decreasing the demand for the model's capability. Specifically, when combined with GPT-3.5, ICE's performance matches that of raw GPT-4 across various agent tasks. We argue that this self-evolution approach represents a paradigm shift in agent design, contributing to a more robust AI community and ecosystem, and moving a step closer to full autonomy.
DebugBench: Evaluating Debugging Capability of Large Language Models
Jan 11, 2024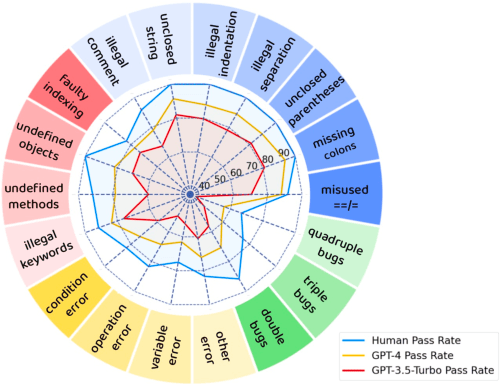

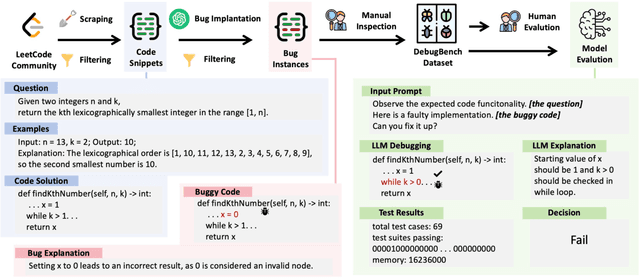

Large Language Models (LLMs) have demonstrated exceptional coding capability. However, as another critical component of programming proficiency, the debugging capability of LLMs remains relatively unexplored. Previous evaluations of LLMs' debugging ability are significantly limited by the risk of data leakage, the scale of the dataset, and the variety of tested bugs. To overcome these deficiencies, we introduce `DebugBench', an LLM debugging benchmark consisting of 4,253 instances. It covers four major bug categories and 18 minor types in C++, Java, and Python. To construct DebugBench, we collect code snippets from the LeetCode community, implant bugs into source data with GPT-4, and assure rigorous quality checks. We evaluate two commercial and three open-source models in a zero-shot scenario. We find that (1) while closed-source models like GPT-4 exhibit inferior debugging performance compared to humans, open-source models such as Code Llama fail to attain any pass rate scores; (2) the complexity of debugging notably fluctuates depending on the bug category; (3) incorporating runtime feedback has a clear impact on debugging performance which is not always helpful. As an extension, we also compare LLM debugging and code generation, revealing a strong correlation between them for closed-source models. These findings will benefit the development of LLMs in debugging.
GitAgent: Facilitating Autonomous Agent with GitHub by Tool Extension
Dec 28, 2023While Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated exceptional proficiency in natural language processing, their efficacy in addressing complex, multifaceted tasks remains limited. A growing area of research focuses on LLM-based agents equipped with external tools capable of performing diverse tasks. However, existing LLM-based agents only support a limited set of tools which is unable to cover a diverse range of user queries, especially for those involving expertise domains. It remains a challenge for LLM-based agents to extend their tools autonomously when confronted with various user queries. As GitHub has hosted a multitude of repositories which can be seen as a good resource for tools, a promising solution is that LLM-based agents can autonomously integrate the repositories in GitHub according to the user queries to extend their tool set. In this paper, we introduce GitAgent, an agent capable of achieving the autonomous tool extension from GitHub. GitAgent follows a four-phase procedure to incorporate repositories and it can learn human experience by resorting to GitHub Issues/PRs to solve problems encountered during the procedure. Experimental evaluation involving 30 user queries demonstrates GitAgent's effectiveness, achieving a 69.4% success rate on average.
ProAgent: From Robotic Process Automation to Agentic Process Automation
Nov 02, 2023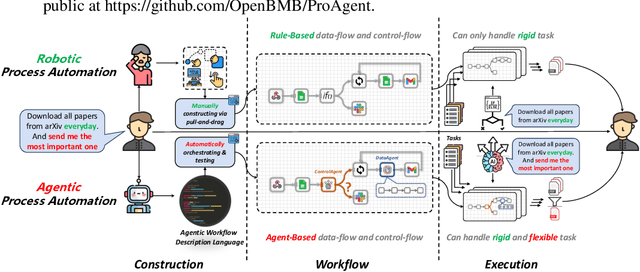
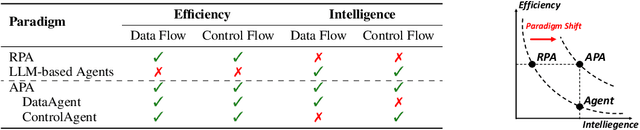
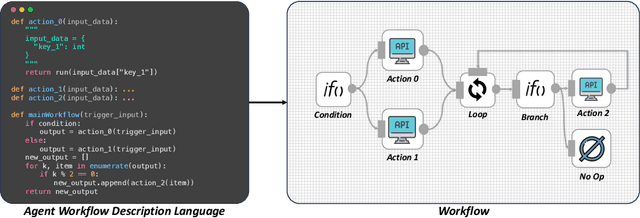
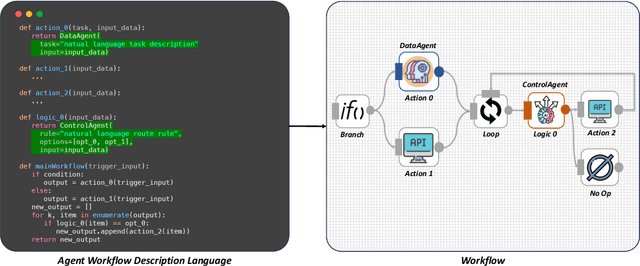
From ancient water wheels to robotic process automation (RPA), automation technology has evolved throughout history to liberate human beings from arduous tasks. Yet, RPA struggles with tasks needing human-like intelligence, especially in elaborate design of workflow construction and dynamic decision-making in workflow execution. As Large Language Models (LLMs) have emerged human-like intelligence, this paper introduces Agentic Process Automation (APA), a groundbreaking automation paradigm using LLM-based agents for advanced automation by offloading the human labor to agents associated with construction and execution. We then instantiate ProAgent, an LLM-based agent designed to craft workflows from human instructions and make intricate decisions by coordinating specialized agents. Empirical experiments are conducted to detail its construction and execution procedure of workflow, showcasing the feasibility of APA, unveiling the possibility of a new paradigm of automation driven by agents. Our code is public at https://github.com/OpenBMB/ProAgent.
Large Language Model as Autonomous Decision Maker
Aug 24, 2023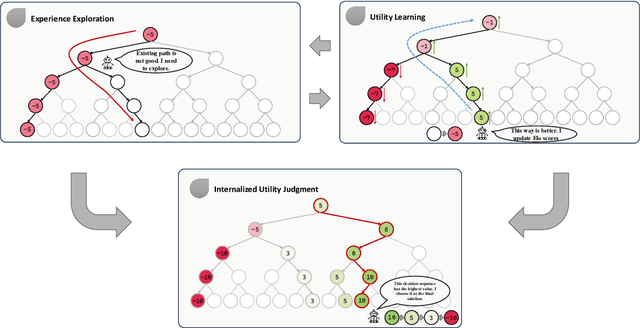
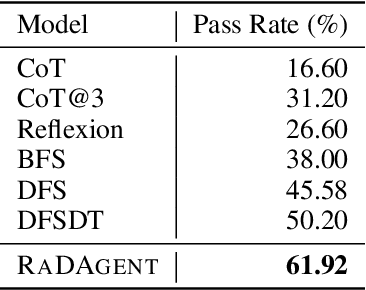
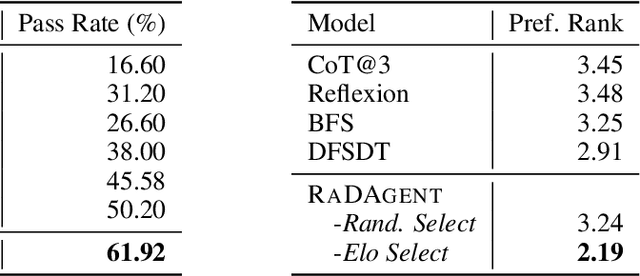
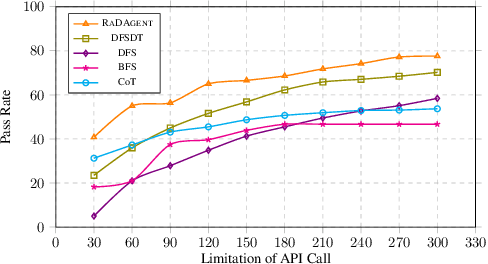
While large language models (LLMs) exhibit impressive language understanding and in-context learning abilities, their decision-making ability still heavily relies on the guidance of task-specific expert knowledge when solving real-world tasks. To unleash the potential of LLMs as autonomous decision makers, this paper presents an approach JuDec to endow LLMs with the self-judgment ability, enabling LLMs to achieve autonomous judgment and exploration for decision making. Specifically, in JuDec, Elo-based Self-Judgment Mechanism is designed to assign Elo scores to decision steps to judge their values and utilities via pairwise comparisons between two solutions and then guide the decision-searching process toward the optimal solution accordingly. Experimental results on the ToolBench dataset demonstrate JuDec's superiority over baselines, achieving over 10% improvement in Pass Rate on diverse tasks. It offers higher-quality solutions and reduces costs (ChatGPT API calls), highlighting its effectiveness and efficiency.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Jul 31, 2023Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is because current instruction tuning largely focuses on basic language tasks instead of the tool-use domain. This is in contrast to state-of-the-art (SOTA) LLMs, e.g., ChatGPT, which have demonstrated excellent tool-use capabilities but are unfortunately closed source. To facilitate tool-use capabilities within open-source LLMs, we introduce ToolLLM, a general tool-use framework of data construction, model training and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is created automatically using ChatGPT. Specifically, we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub, then prompt ChatGPT to generate diverse human instructions involving these APIs, covering both single-tool and multi-tool scenarios. Finally, we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To make the searching process more efficient, we develop a novel depth-first search-based decision tree (DFSDT), enabling LLMs to evaluate multiple reasoning traces and expand the search space. We show that DFSDT significantly enhances the planning and reasoning capabilities of LLMs. For efficient tool-use assessment, we develop an automatic evaluator: ToolEval. We fine-tune LLaMA on ToolBench and obtain ToolLLaMA. Our ToolEval reveals that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. To make the pipeline more practical, we devise a neural API retriever to recommend appropriate APIs for each instruction, negating the need for manual API selection.
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.