 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Intelligent Metasurface Assisted Multiuser Communications: From a Rate Fairness Perspective
Jul 23, 2025Stacked intelligent metasurface (SIM) extends the concept of single-layer reconfigurable holographic surfaces (RHS) by incorporating a multi-layered structure, thereby providing enhanced control over electromagnetic wave propagation and improved signal processing capabilities. This study investigates the potential of SIM in enhancing the rate fairness in multiuser downlink systems by addressing two key optimization problems: maximizing the minimum rate (MR) and maximizing the geometric mean of rates (GMR). {The former strives to enhance the minimum user rate, thereby ensuring fairness among users, while the latter relaxes fairness requirements to strike a better trade-off between user fairness and system sum-rate (SR).} For the MR maximization, we adopt a consensus alternating direction method of multipliers (ADMM)-based approach, which decomposes the approximated problem into sub-problems with closed-form solutions. {For GMR maximization, we develop an alternating optimization (AO)-based algorithm that also yields closed-form solutions and can be seamlessly adapted for SR maximization. Numerical results validate the effectiveness and convergence of the proposed algorithms.} Comparative evaluations show that MR maximization ensures near-perfect fairness, while GMR maximization balances fairness and system SR. Furthermore, the two proposed algorithms respectively outperform existing related works in terms of MR and SR performance. Lastly, SIM with lower power consumption achieves performance comparable to that of multi-antenna digital beamforming.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
RAID: An In-Training Defense against Attribute Inference Attacks in Recommender Systems
Apr 15, 2025In various networks and mobile applications, users are highly susceptible to attribute inference attacks, with particularly prevalent occurrences in recommender systems. Attackers exploit partially exposed user profiles in recommendation models, such as user embeddings, to infer private attributes of target users, such as gender and political views. The goal of defenders is to mitigate the effectiveness of these attacks while maintaining recommendation performance. Most existing defense methods, such as differential privacy and attribute unlearning, focus on post-training settings, which limits their capability of utilizing training data to preserve recommendation performance. Although adversarial training extends defenses to in-training settings, it often struggles with convergence due to unstable training processes. In this paper, we propose RAID, an in-training defense method against attribute inference attacks in recommender systems. In addition to the recommendation objective, we define a defensive objective to ensure that the distribution of protected attributes becomes independent of class labels, making users indistinguishable from attribute inference attacks. Specifically, this defensive objective aims to solve a constrained Wasserstein barycenter problem to identify the centroid distribution that makes the attribute indistinguishable while complying with recommendation performance constraints. To optimize our proposed objective, we use optimal transport to align users with the centroid distribution. We conduct extensive experiments on four real-world datasets to evaluate RAID. The experimental results validate the effectiveness of RAID and demonstrate its significant superiority over existing methods in multiple aspects.
Reproducibility Companion Paper: Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems
Mar 29, 2025In this paper, we reproduce the experimental results presented in our previous work titled "Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems," which was published in the proceedings of the 31st ACM International Conference on Multimedia. This paper aims to validate the effectiveness of our proposed method and help others reproduce our experimental results. We provide detailed descriptions of our preprocessed datasets, source code structure, configuration file settings, experimental environment, and reproduced experimental results.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
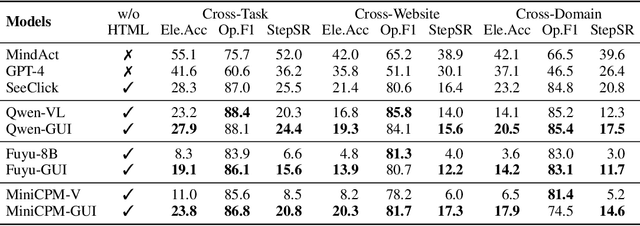
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
FocusLLM: Scaling LLM's Context by Parallel Decoding
Aug 21, 2024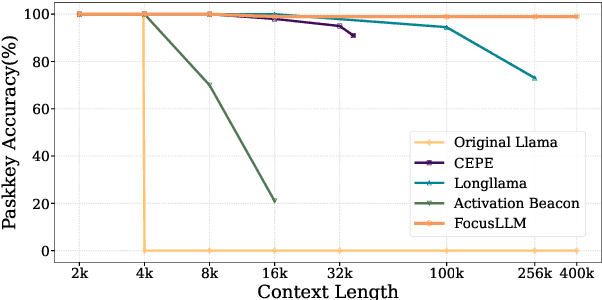

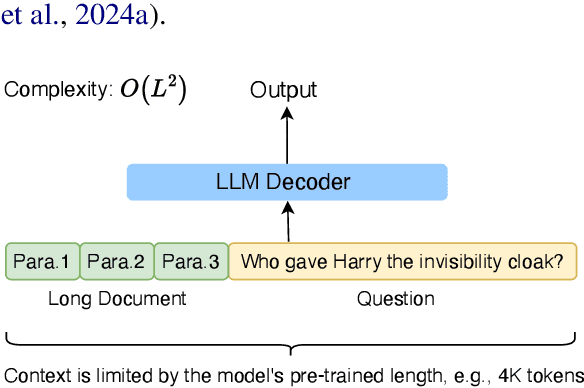

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.
GUICourse: From General Vision Language Models to Versatile GUI Agents
Jun 17, 2024
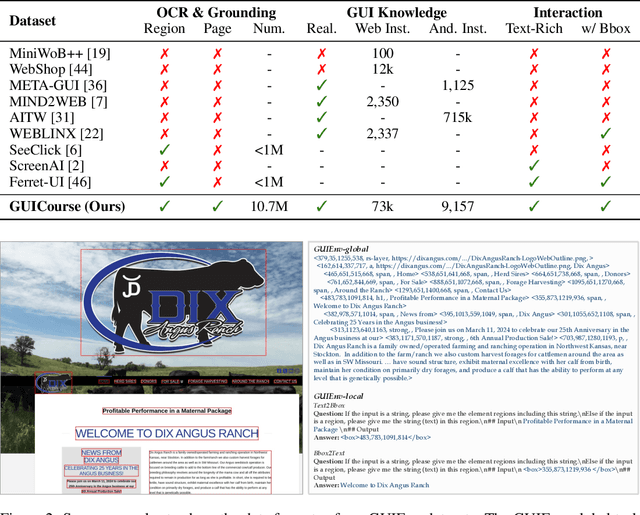
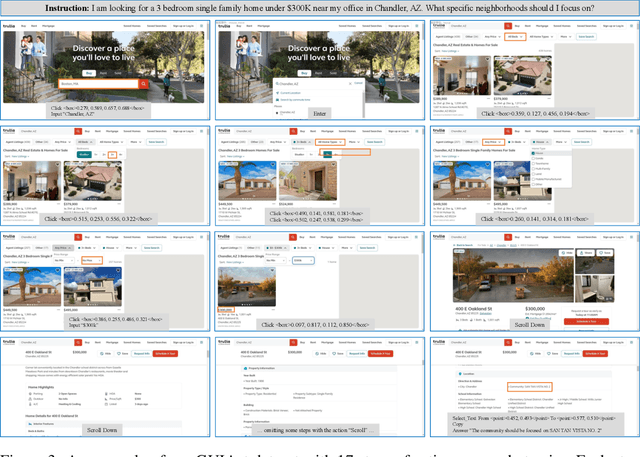
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
UniMem: Towards a Unified View of Long-Context Large Language Models
Feb 05, 2024



Long-context processing is a critical ability that constrains the applicability of large language models. Although there exist various methods devoted to enhancing the long-context processing ability of large language models (LLMs), they are developed in an isolated manner and lack systematic analysis and integration of their strengths, hindering further developments. In this paper, we introduce UniMem, a unified framework that reformulates existing long-context methods from the view of memory augmentation of LLMs. UniMem is characterized by four key dimensions: Memory Management, Memory Writing, Memory Reading, and Memory Injection, providing a systematic theory for understanding various long-context methods. We reformulate 16 existing methods based on UniMem and analyze four representative methods: Transformer-XL, Memorizing Transformer, RMT, and Longformer into equivalent UniMem forms to reveal their design principles and strengths. Based on these analyses, we propose UniMix, an innovative approach that integrates the strengths of these algorithms. Experimental results show that UniMix achieves superior performance in handling long contexts with significantly lower perplexity than baselines.
Computer-aided Tuberculosis Diagnosis with Attribute Reasoning Assistance
Jul 01, 2022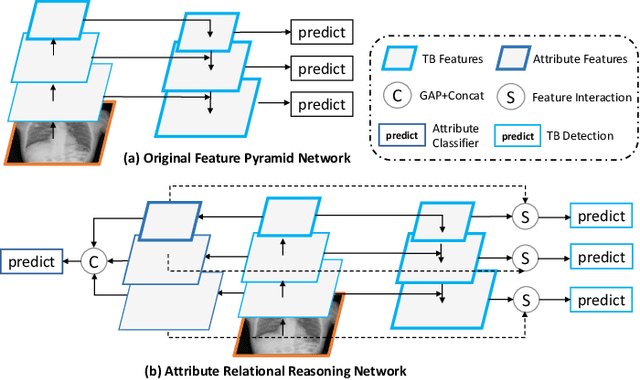

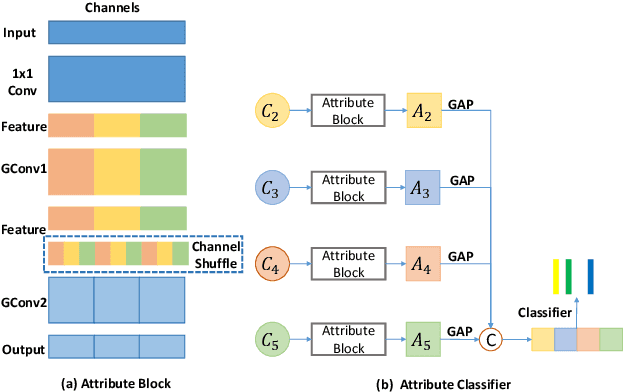

Although deep learning algorithms have been intensively developed for computer-aided tuberculosis diagnosis (CTD), they mainly depend on carefully annotated datasets, leading to much time and resource consumption. Weakly supervised learning (WSL), which leverages coarse-grained labels to accomplish fine-grained tasks, has the potential to solve this problem. In this paper, we first propose a new large-scale tuberculosis (TB) chest X-ray dataset, namely the tuberculosis chest X-ray attribute dataset (TBX-Att), and then establish an attribute-assisted weakly-supervised framework to classify and localize TB by leveraging the attribute information to overcome the insufficiency of supervision in WSL scenarios. Specifically, first, the TBX-Att dataset contains 2000 X-ray images with seven kinds of attributes for TB relational reasoning, which are annotated by experienced radiologists. It also includes the public TBX11K dataset with 11200 X-ray images to facilitate weakly supervised detection. Second, we exploit a multi-scale feature interaction model for TB area classification and detection with attribute relational reasoning. The proposed model is evaluated on the TBX-Att dataset and will serve as a solid baseline for future research. The code and data will be available at https://github.com/GangmingZhao/tb-attribute-weak-localization.