 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoMamba: Topology-Aware Scanning and Fusion for Segmenting Heterogeneous Medical Visual Media
Apr 28, 2026Visual state-space models (SSMs) have shown strong potential for medical image segmentation, yet their effectiveness is often limited by two practical issues: axis-biased scan ordering weakens the modeling of oblique and curved structures, and naive multi-branch fusion tends to amplify redundant responses. We present TopoMamba, a topology-aware scan-and-fuse framework for segmenting heterogeneous medical visual media. The method combines a diagonal/anti-diagonal TopoA-Scan branch with the standard Cross-Scan branch to provide complementary structural priors, and introduces ScanCache, a device-aware caching mechanism that amortizes explicit scan-index construction across recurring resolutions. To fuse heterogeneous scan features efficiently, we further propose a lightweight HSIC Gate that regulates branch interaction using a dependence-aware scalar gating rule. We also instantiate a volumetric TopoMamba-3D for practical 3D clinical segmentation. Experiments on Synapse CT, ISIC 2017 dermoscopy, and CVC-ClinicDB endoscopy show that TopoMamba consistently improves segmentation quality over strong CNN, Transformer, and SSM baselines, with particularly clear gains on thin or curved targets such as the pancreas and gallbladder, while maintaining favorable deployment efficiency under dynamic input resolutions. These results suggest that topology-aware scan ordering and lightweight dependence-aware fusion form an effective and practical design for medical multimedia segmentation. The code will be made publicly available.
Effective Gaussian Management for High-fidelity Object Reconstruction
Sep 16, 2025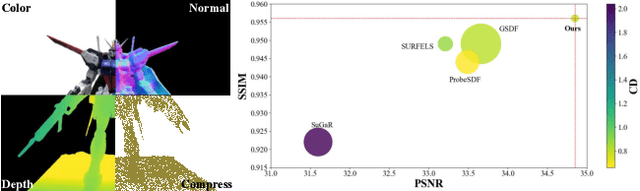
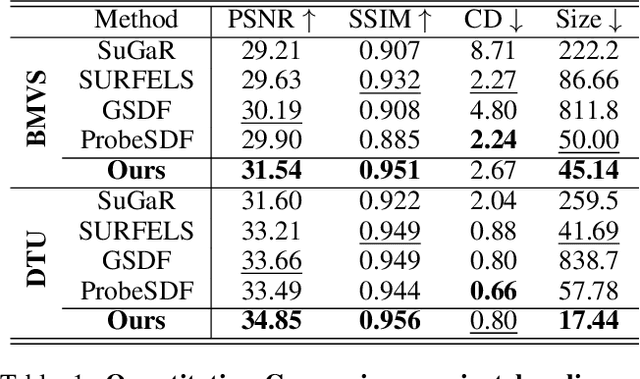
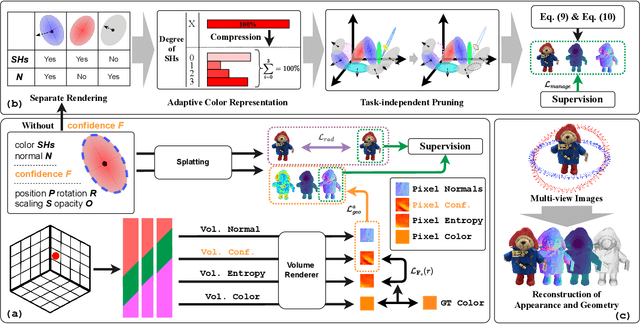
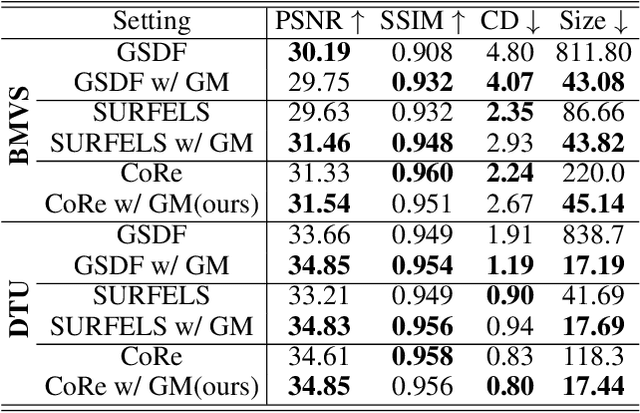
This paper proposes an effective Gaussian management approach for high-fidelity object reconstruction. Departing from recent Gaussian Splatting (GS) methods that employ indiscriminate attribute assignment, our approach introduces a novel densification strategy that dynamically activates spherical harmonics (SHs) or normals under the supervision of a surface reconstruction module, which effectively mitigates the gradient conflicts caused by dual supervision and achieves superior reconstruction results. To further improve representation efficiency, we develop a lightweight Gaussian representation that adaptively adjusts the SH orders of each Gaussian based on gradient magnitudes and performs task-decoupled pruning to remove Gaussian with minimal impact on a reconstruction task without sacrificing others, which balances the representational capacity with parameter quantity. Notably, our management approach is model-agnostic and can be seamlessly integrated into other frameworks, enhancing performance while reducing model size. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art approaches in both reconstruction quality and efficiency, achieving superior performance with significantly fewer parameters.
Learning to Generate Structured Output with Schema Reinforcement Learning
Feb 26, 2025This study investigates the structured generation capabilities of large language models (LLMs), focusing on producing valid JSON outputs against a given schema. Despite the widespread use of JSON in integrating language models with programs, there is a lack of comprehensive analysis and benchmarking of these capabilities. We explore various aspects of JSON generation, such as structure understanding, escaping, and natural language description, to determine how to assess and enable LLMs to generate valid responses. Building upon this, we propose SchemaBench features around 40K different JSON schemas to obtain and assess models' abilities in generating valid JSON. We find that the latest LLMs are still struggling to generate a valid JSON string. Moreover, we demonstrate that incorporating reinforcement learning with a Fine-grained Schema Validator can further enhance models' understanding of JSON schema, leading to improved performance. Our models demonstrate significant improvement in both generating JSON outputs and downstream tasks.
ASSNet: Adaptive Semantic Segmentation Network for Microtumors and Multi-Organ Segmentation
Sep 12, 2024



Medical image segmentation, a crucial task in computer vision, facilitates the automated delineation of anatomical structures and pathologies, supporting clinicians in diagnosis, treatment planning, and disease monitoring. Notably, transformers employing shifted window-based self-attention have demonstrated exceptional performance. However, their reliance on local window attention limits the fusion of local and global contextual information, crucial for segmenting microtumors and miniature organs. To address this limitation, we propose the Adaptive Semantic Segmentation Network (ASSNet), a transformer architecture that effectively integrates local and global features for precise medical image segmentation. ASSNet comprises a transformer-based U-shaped encoder-decoder network. The encoder utilizes shifted window self-attention across five resolutions to extract multi-scale features, which are then propagated to the decoder through skip connections. We introduce an augmented multi-layer perceptron within the encoder to explicitly model long-range dependencies during feature extraction. Recognizing the constraints of conventional symmetrical encoder-decoder designs, we propose an Adaptive Feature Fusion (AFF) decoder to complement our encoder. This decoder incorporates three key components: the Long Range Dependencies (LRD) block, the Multi-Scale Feature Fusion (MFF) block, and the Adaptive Semantic Center (ASC) block. These components synergistically facilitate the effective fusion of multi-scale features extracted by the decoder while capturing long-range dependencies and refining object boundaries. Comprehensive experiments on diverse medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, demonstrate that ASSNet achieves state-of-the-art results. Code and models are available at: \url{https://github.com/lzeeorno/ASSNet}.
SMAFormer: Synergistic Multi-Attention Transformer for Medical Image Segmentation
Aug 31, 2024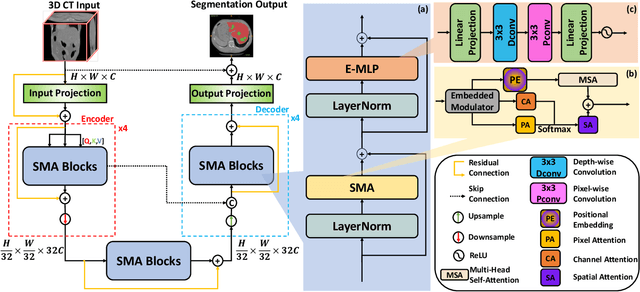
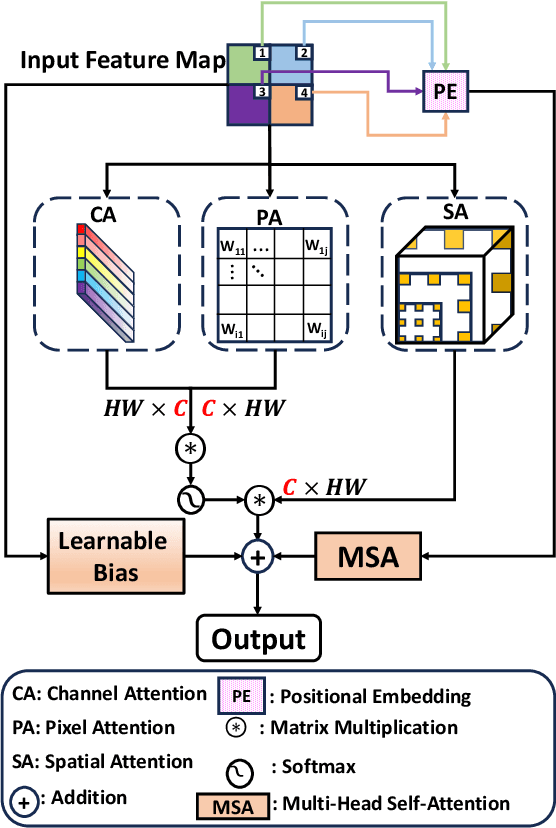
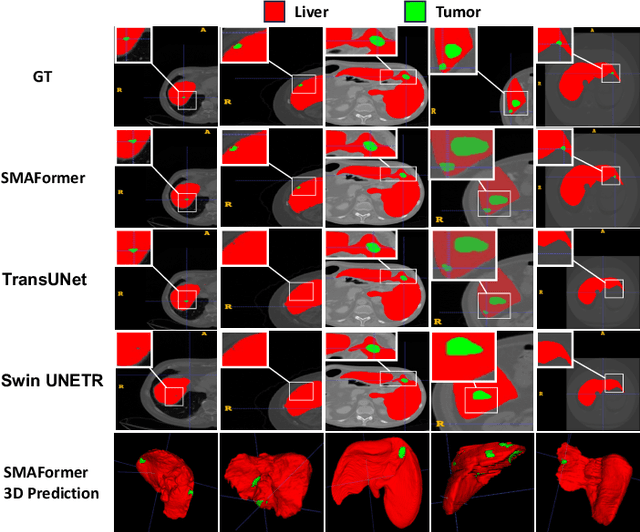
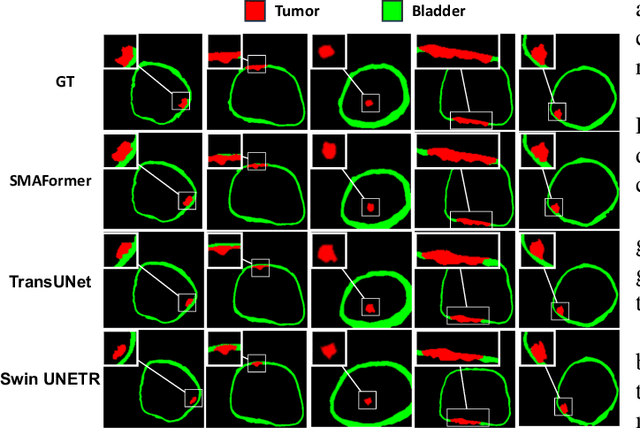
In medical image segmentation, specialized computer vision techniques, notably transformers grounded in attention mechanisms and residual networks employing skip connections, have been instrumental in advancing performance. Nonetheless, previous models often falter when segmenting small, irregularly shaped tumors. To this end, we introduce SMAFormer, an efficient, Transformer-based architecture that fuses multiple attention mechanisms for enhanced segmentation of small tumors and organs. SMAFormer can capture both local and global features for medical image segmentation. The architecture comprises two pivotal components. First, a Synergistic Multi-Attention (SMA) Transformer block is proposed, which has the benefits of Pixel Attention, Channel Attention, and Spatial Attention for feature enrichment. Second, addressing the challenge of information loss incurred during attention mechanism transitions and feature fusion, we design a Feature Fusion Modulator. This module bolsters the integration between the channel and spatial attention by mitigating reshaping-induced information attrition. To evaluate our method, we conduct extensive experiments on various medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, achieving state-of-the-art results. Code and models are available at: \url{https://github.com/CXH-Research/SMAFormer}.
Depth-aware Test-Time Training for Zero-shot Video Object Segmentation
Mar 07, 2024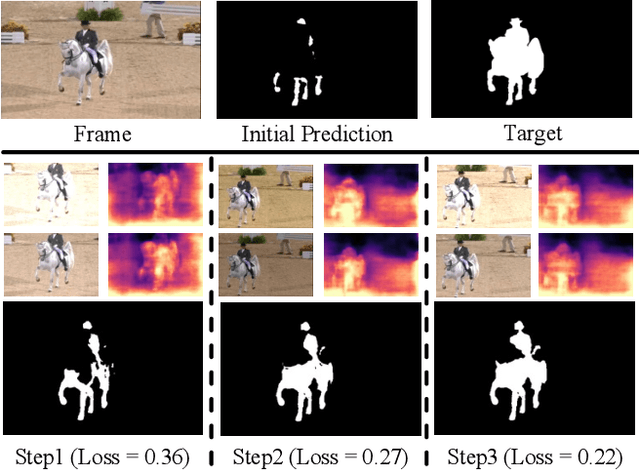
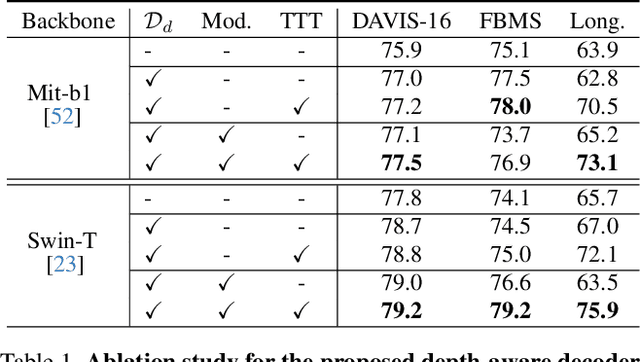
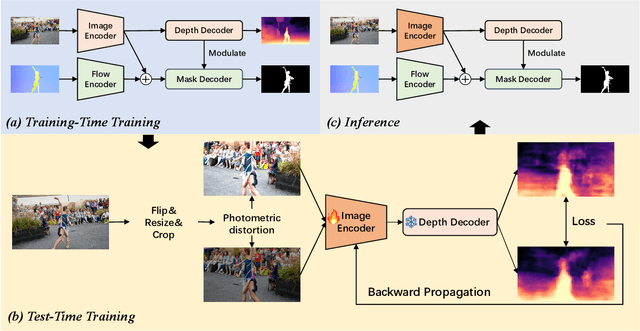
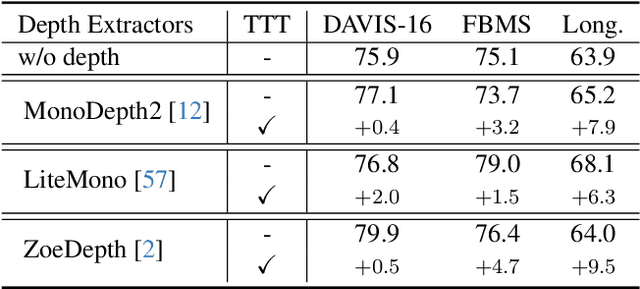
Zero-shot Video Object Segmentation (ZSVOS) aims at segmenting the primary moving object without any human annotations. Mainstream solutions mainly focus on learning a single model on large-scale video datasets, which struggle to generalize to unseen videos. In this work, we introduce a test-time training (TTT) strategy to address the problem. Our key insight is to enforce the model to predict consistent depth during the TTT process. In detail, we first train a single network to perform both segmentation and depth prediction tasks. This can be effectively learned with our specifically designed depth modulation layer. Then, for the TTT process, the model is updated by predicting consistent depth maps for the same frame under different data augmentations. In addition, we explore different TTT weight updating strategies. Our empirical results suggest that the momentum-based weight initialization and looping-based training scheme lead to more stable improvements. Experiments show that the proposed method achieves clear improvements on ZSVOS. Our proposed video TTT strategy provides significant superiority over state-of-the-art TTT methods. Our code is available at: https://nifangbaage.github.io/DATTT.
UniMem: Towards a Unified View of Long-Context Large Language Models
Feb 05, 2024



Long-context processing is a critical ability that constrains the applicability of large language models. Although there exist various methods devoted to enhancing the long-context processing ability of large language models (LLMs), they are developed in an isolated manner and lack systematic analysis and integration of their strengths, hindering further developments. In this paper, we introduce UniMem, a unified framework that reformulates existing long-context methods from the view of memory augmentation of LLMs. UniMem is characterized by four key dimensions: Memory Management, Memory Writing, Memory Reading, and Memory Injection, providing a systematic theory for understanding various long-context methods. We reformulate 16 existing methods based on UniMem and analyze four representative methods: Transformer-XL, Memorizing Transformer, RMT, and Longformer into equivalent UniMem forms to reveal their design principles and strengths. Based on these analyses, we propose UniMix, an innovative approach that integrates the strengths of these algorithms. Experimental results show that UniMix achieves superior performance in handling long contexts with significantly lower perplexity than baselines.