 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Generator Barrier: Disentangled Representation for Generalizable AI-Text Detection
Apr 15, 2026As large language models (LLMs) generate text that increasingly resembles human writing, the subtle cues that distinguish AI-generated content from human-written content become increasingly challenging to capture. Reliance on generator-specific artifacts is inherently unstable, since new models emerge rapidly and reduce the robustness of such shortcuts. This generalizes unseen generators as a central and challenging problem for AI-text detection. To tackle this challenge, we propose a progressively structured framework that disentangles AI-detection semantics from generator-aware artifacts. This is achieved through a compact latent encoding that encourages semantic minimality, followed by perturbation-based regularization to reduce residual entanglement, and finally a discriminative adaptation stage that aligns representations with task objectives. Experiments on MAGE benchmark, covering 20 representative LLMs across 7 categories, demonstrate consistent improvements over state-of-the-art methods, achieving up to 24.2% accuracy gain and 26.2% F1 improvement. Notably, performance continues to improve as the diversity of training generators increases, confirming strong scalability and generalization in open-set scenarios. Our source code will be publicly available at https://github.com/PuXiao06/DRGD.
Combating Pattern and Content Bias: Adversarial Feature Learning for Generalized AI-Generated Image Detection
Apr 14, 2026In recent years, the rapid development of generative artificial intelligence technology has significantly lowered the barrier to creating high-quality fake images, posing a serious challenge to information authenticity and credibility. Existing generated image detection methods typically enhance generalization through model architecture or network design. However, their generalization performance remains susceptible to data bias, as the training data may drive models to fit specific generative patterns and content rather than the common features shared by images from different generative models (asymmetric bias learning). To address this issue, we propose a Multi-dimensional Adversarial Feature Learning (MAFL) framework. The framework adopts a pretrained multimodal image encoder as the feature extraction backbone, constructs a real-fake feature learning network, and designs an adversarial bias-learning branch equipped with a multi-dimensional adversarial loss, forming an adversarial training mechanism between authenticity-discriminative feature learning and bias feature learning. By suppressing generation-pattern and content biases, MAFL guides the model to focus on the generative features shared across different generative models, thereby effectively capturing the fundamental differences between real and generated images, enhancing cross-model generalization, and substantially reducing the reliance on large-scale training data. Through extensive experimental validation, our method outperforms existing state-of-the-art approaches by 10.89% in accuracy and 8.57% in Average Precision (AP). Notably, even when trained with only 320 images, it can still achieve over 80% detection accuracy on public datasets.
Select, Hypothesize and Verify: Towards Verified Neuron Concept Interpretation
Mar 26, 2026It is essential for understanding neural network decisions to interpret the functionality (also known as concepts) of neurons. Existing approaches describe neuron concepts by generating natural language descriptions, thereby advancing the understanding of the neural network's decision-making mechanism. However, these approaches assume that each neuron has well-defined functions and provides discriminative features for neural network decision-making. In fact, some neurons may be redundant or may offer misleading concepts. Thus, the descriptions for such neurons may cause misinterpretations of the factors driving the neural network's decisions. To address the issue, we introduce a verification of neuron functions, which checks whether the generated concept highly activates the corresponding neuron. Furthermore, we propose a Select-Hypothesize-Verify framework for interpreting neuron functionality. This framework consists of: 1) selecting activation samples that best capture a neuron's well-defined functional behavior through activation-distribution analysis; 2) forming hypotheses about concepts for the selected neurons; and 3) verifying whether the generated concepts accurately reflect the functionality of the neuron. Extensive experiments show that our method produces more accurate neuron concepts. Our generated concepts activate the corresponding neurons with a probability approximately 1.5 times that of the current state-of-the-art method.
When Detectors Forget Forensics: Blocking Semantic Shortcuts for Generalizable AI-Generated Image Detection
Mar 10, 2026AI-generated image detection has become increasingly important with the rapid advancement of generative AI. However, detectors built on Vision Foundation Models (VFMs, \emph{e.g.}, CLIP) often struggle to generalize to images created using unseen generation pipelines. We identify, for the first time, a key failure mechanism, termed \emph{semantic fallback}, where VFM-based detectors rely on dominant pre-trained semantic priors (such as identity) rather than forgery-specific traces under distribution shifts. To address this issue, we propose \textbf{Geometric Semantic Decoupling (GSD)}, a parameter-free module that explicitly removes semantic components from learned representations by leveraging a frozen VFM as a semantic guide with a trainable VFM as an artifact detector. GSD estimates semantic directions from batch-wise statistics and projects them out via a geometric constraint, forcing the artifact detector to rely on semantic-invariant forensic evidence. Extensive experiments demonstrate that our method consistently outperforms state-of-the-art approaches, achieving 94.4\% video-level AUC (+\textbf{1.2\%}) in cross-dataset evaluation, improving robustness to unseen manipulations (+\textbf{3.0\%} on DF40), and generalizing beyond faces to the detection of synthetic images of general scenes, including UniversalFakeDetect (+\textbf{0.9\%}) and GenImage (+\textbf{1.7\%}).
Diversity over Uniformity: Rethinking Representation in Generated Image Detection
Feb 28, 2026With the rapid advancement of generative models, generated image detection has become an important task in visual forensics. Although existing methods have achieved remarkable progress, they often rely, after training, on only a small subset of highly salient forgery cues, which limits their ability to generalize to unseen generative mechanisms. We argue that reliably generated image detection should not depend on a single decision path but should preserve multiple judgment perspectives, enabling the model to understand the differences between real and generated images from diverse viewpoints. Based on this idea, we propose an anti-feature-collapse learning framework that filters task-irrelevant components and suppresses excessive overlap among different forgery cues in the representation space, preventing discriminative information from collapsing into a few dominant feature directions. This design maintains diverse and complementary evidence within the model, reduces reliance on a small set of salient cues, and enhances robustness under unseen generative settings. Extensive experiments on multiple public benchmarks demonstrate that the proposed method significantly outperforms the state-of-the-art approaches in cross-model scenarios, achieving an accuracy improvement of 5.02% and exhibiting superior generalization and detection reliability. The source code is available at https://github.com/Yanmou-Hui/DoU.
Clear Nights Ahead: Towards Multi-Weather Nighttime Image Restoration
May 22, 2025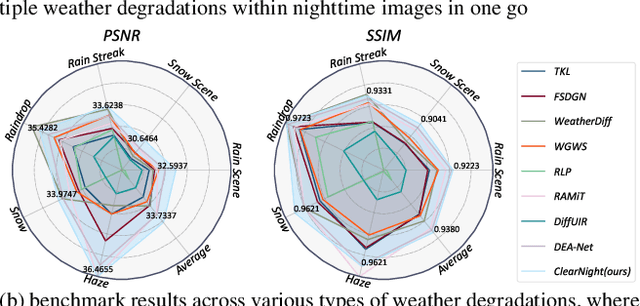
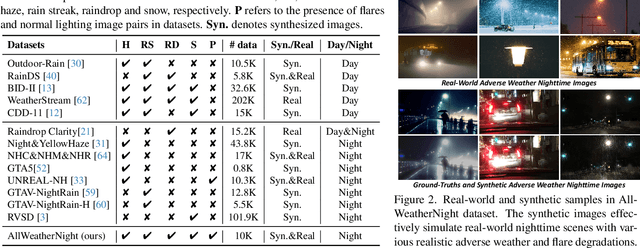

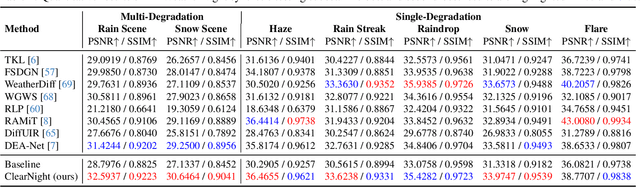
Restoring nighttime images affected by multiple adverse weather conditions is a practical yet under-explored research problem, as multiple weather conditions often coexist in the real world alongside various lighting effects at night. This paper first explores the challenging multi-weather nighttime image restoration task, where various types of weather degradations are intertwined with flare effects. To support the research, we contribute the AllWeatherNight dataset, featuring large-scale high-quality nighttime images with diverse compositional degradations, synthesized using our introduced illumination-aware degradation generation. Moreover, we present ClearNight, a unified nighttime image restoration framework, which effectively removes complex degradations in one go. Specifically, ClearNight extracts Retinex-based dual priors and explicitly guides the network to focus on uneven illumination regions and intrinsic texture contents respectively, thereby enhancing restoration effectiveness in nighttime scenarios. In order to better represent the common and unique characters of multiple weather degradations, we introduce a weather-aware dynamic specific-commonality collaboration method, which identifies weather degradations and adaptively selects optimal candidate units associated with specific weather types. Our ClearNight achieves state-of-the-art performance on both synthetic and real-world images. Comprehensive ablation experiments validate the necessity of AllWeatherNight dataset as well as the effectiveness of ClearNight. Project page: https://henlyta.github.io/ClearNight/mainpage.html
Mobius: Text to Seamless Looping Video Generation via Latent Shift
Feb 27, 2025We present Mobius, a novel method to generate seamlessly looping videos from text descriptions directly without any user annotations, thereby creating new visual materials for the multi-media presentation. Our method repurposes the pre-trained video latent diffusion model for generating looping videos from text prompts without any training. During inference, we first construct a latent cycle by connecting the starting and ending noise of the videos. Given that the temporal consistency can be maintained by the context of the video diffusion model, we perform multi-frame latent denoising by gradually shifting the first-frame latent to the end in each step. As a result, the denoising context varies in each step while maintaining consistency throughout the inference process. Moreover, the latent cycle in our method can be of any length. This extends our latent-shifting approach to generate seamless looping videos beyond the scope of the video diffusion model's context. Unlike previous cinemagraphs, the proposed method does not require an image as appearance, which will restrict the motions of the generated results. Instead, our method can produce more dynamic motion and better visual quality. We conduct multiple experiments and comparisons to verify the effectiveness of the proposed method, demonstrating its efficacy in different scenarios. All the code will be made available.
CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training
Dec 23, 2024Benefiting from large-scale pre-training of text-video pairs, current text-to-video (T2V) diffusion models can generate high-quality videos from the text description. Besides, given some reference images or videos, the parameter-efficient fine-tuning method, i.e. LoRA, can generate high-quality customized concepts, e.g., the specific subject or the motions from a reference video. However, combining the trained multiple concepts from different references into a single network shows obvious artifacts. To this end, we propose CustomTTT, where we can joint custom the appearance and the motion of the given video easily. In detail, we first analyze the prompt influence in the current video diffusion model and find the LoRAs are only needed for the specific layers for appearance and motion customization. Besides, since each LoRA is trained individually, we propose a novel test-time training technique to update parameters after combination utilizing the trained customized models. We conduct detailed experiments to verify the effectiveness of the proposed methods. Our method outperforms several state-of-the-art works in both qualitative and quantitative evaluations.
ZeroPur: Succinct Training-Free Adversarial Purification
Jun 05, 2024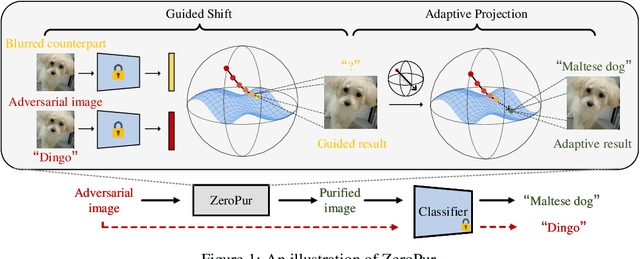

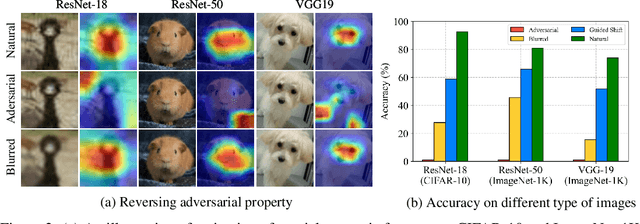

Adversarial purification is a kind of defense technique that can defend various unseen adversarial attacks without modifying the victim classifier. Existing methods often depend on external generative models or cooperation between auxiliary functions and victim classifiers. However, retraining generative models, auxiliary functions, or victim classifiers relies on the domain of the fine-tuned dataset and is computation-consuming. In this work, we suppose that adversarial images are outliers of the natural image manifold and the purification process can be considered as returning them to this manifold. Following this assumption, we present a simple adversarial purification method without further training to purify adversarial images, called ZeroPur. ZeroPur contains two steps: given an adversarial example, Guided Shift obtains the shifted embedding of the adversarial example by the guidance of its blurred counterparts; after that, Adaptive Projection constructs a directional vector by this shifted embedding to provide momentum, projecting adversarial images onto the manifold adaptively. ZeroPur is independent of external models and requires no retraining of victim classifiers or auxiliary functions, relying solely on victim classifiers themselves to achieve purification. Extensive experiments on three datasets (CIFAR-10, CIFAR-100, and ImageNet-1K) using various classifier architectures (ResNet, WideResNet) demonstrate that our method achieves state-of-the-art robust performance. The code will be publicly available.
Depth-aware Test-Time Training for Zero-shot Video Object Segmentation
Mar 07, 2024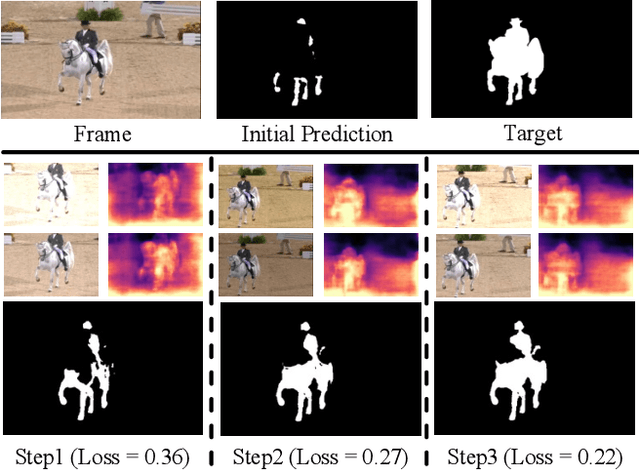
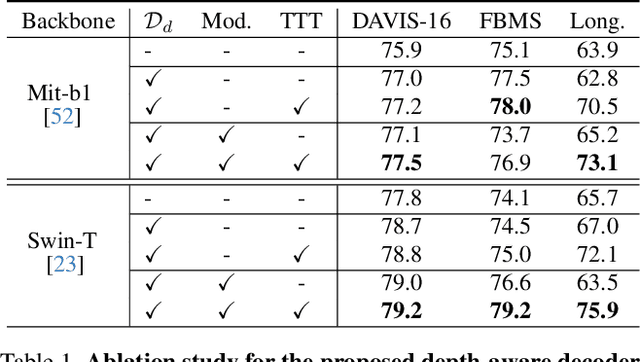
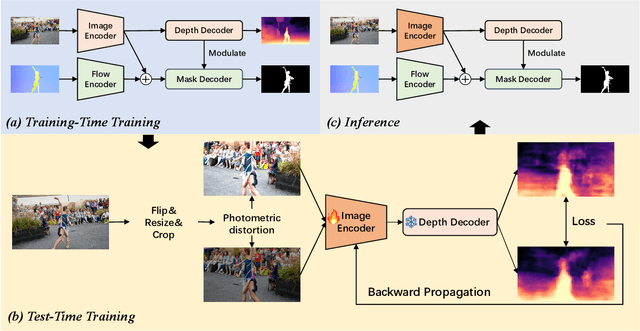
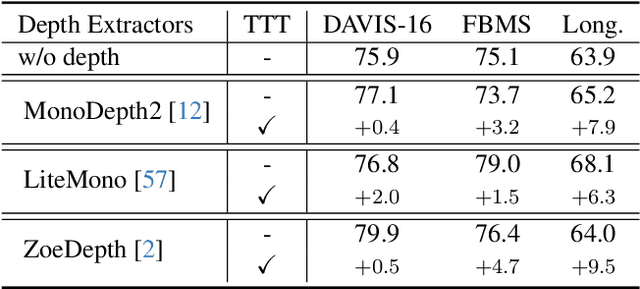
Zero-shot Video Object Segmentation (ZSVOS) aims at segmenting the primary moving object without any human annotations. Mainstream solutions mainly focus on learning a single model on large-scale video datasets, which struggle to generalize to unseen videos. In this work, we introduce a test-time training (TTT) strategy to address the problem. Our key insight is to enforce the model to predict consistent depth during the TTT process. In detail, we first train a single network to perform both segmentation and depth prediction tasks. This can be effectively learned with our specifically designed depth modulation layer. Then, for the TTT process, the model is updated by predicting consistent depth maps for the same frame under different data augmentations. In addition, we explore different TTT weight updating strategies. Our empirical results suggest that the momentum-based weight initialization and looping-based training scheme lead to more stable improvements. Experiments show that the proposed method achieves clear improvements on ZSVOS. Our proposed video TTT strategy provides significant superiority over state-of-the-art TTT methods. Our code is available at: https://nifangbaage.github.io/DATTT.