 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimber-Pilot: A Non-Myopic Generative Recommendation Model Towards Better Instruction-Following
Feb 14, 2026Generative retrieval has emerged as a promising paradigm in recommender systems, offering superior sequence modeling capabilities over traditional dual-tower architectures. However, in large-scale industrial scenarios, such models often suffer from inherent myopia: due to single-step inference and strict latency constraints, they tend to collapse diverse user intents into locally optimal predictions, failing to capture long-horizon and multi-item consumption patterns. Moreover, real-world retrieval systems must follow explicit retrieval instructions, such as category-level control and policy constraints. Incorporating such instruction-following behavior into generative retrieval remains challenging, as existing conditioning or post-hoc filtering approaches often compromise relevance or efficiency. In this work, we present Climber-Pilot, a unified generative retrieval framework to address both limitations. First, we introduce Time-Aware Multi-Item Prediction (TAMIP), a novel training paradigm designed to mitigate inherent myopia in generative retrieval. By distilling long-horizon, multi-item foresight into model parameters through time-aware masking, TAMIP alleviates locally optimal predictions while preserving efficient single-step inference. Second, to support flexible instruction-following retrieval, we propose Condition-Guided Sparse Attention (CGSA), which incorporates business constraints directly into the generative process via sparse attention, without introducing additional inference steps. Extensive offline experiments and online A/B testing at NetEase Cloud Music, one of the largest music streaming platforms, demonstrate that Climber-Pilot significantly outperforms state-of-the-art baselines, achieving a 4.24\% lift of the core business metric.
YOLO-DS: Fine-Grained Feature Decoupling via Dual-Statistic Synergy Operator for Object Detection
Jan 26, 2026One-stage object detection, particularly the YOLO series, strikes a favorable balance between accuracy and efficiency. However, existing YOLO detectors lack explicit modeling of heterogeneous object responses within shared feature channels, which limits further performance gains. To address this, we propose YOLO-DS, a framework built around a novel Dual-Statistic Synergy Operator (DSO). The DSO decouples object features by jointly modeling the channel-wise mean and the peak-to-mean difference. Building upon the DSO, we design two lightweight gating modules: the Dual-Statistic Synergy Gating (DSG) module for adaptive channel-wise feature selection, and the Multi-Path Segmented Gating (MSG) module for depth-wise feature weighting. On the MS-COCO benchmark, YOLO-DS consistently outperforms YOLOv8 across five model scales (N, S, M, L, X), achieving AP gains of 1.1% to 1.7% with only a minimal increase in inference latency. Extensive visualization, ablation, and comparative studies validate the effectiveness of our approach, demonstrating its superior capability in discriminating heterogeneous objects with high efficiency.
DM-FNet: Unified multimodal medical image fusion via diffusion process-trained encoder-decoder
Jun 18, 2025Multimodal medical image fusion (MMIF) extracts the most meaningful information from multiple source images, enabling a more comprehensive and accurate diagnosis. Achieving high-quality fusion results requires a careful balance of brightness, color, contrast, and detail; this ensures that the fused images effectively display relevant anatomical structures and reflect the functional status of the tissues. However, existing MMIF methods have limited capacity to capture detailed features during conventional training and suffer from insufficient cross-modal feature interaction, leading to suboptimal fused image quality. To address these issues, this study proposes a two-stage diffusion model-based fusion network (DM-FNet) to achieve unified MMIF. In Stage I, a diffusion process trains UNet for image reconstruction. UNet captures detailed information through progressive denoising and represents multilevel data, providing a rich set of feature representations for the subsequent fusion network. In Stage II, noisy images at various steps are input into the fusion network to enhance the model's feature recognition capability. Three key fusion modules are also integrated to process medical images from different modalities adaptively. Ultimately, the robust network structure and a hybrid loss function are integrated to harmonize the fused image's brightness, color, contrast, and detail, enhancing its quality and information density. The experimental results across various medical image types demonstrate that the proposed method performs exceptionally well regarding objective evaluation metrics. The fused image preserves appropriate brightness, a comprehensive distribution of radioactive tracers, rich textures, and clear edges. The code is available at https://github.com/HeDan-11/DM-FNet.
A2Seek: Towards Reasoning-Centric Benchmark for Aerial Anomaly Understanding
May 28, 2025While unmanned aerial vehicles (UAVs) offer wide-area, high-altitude coverage for anomaly detection, they face challenges such as dynamic viewpoints, scale variations, and complex scenes. Existing datasets and methods, mainly designed for fixed ground-level views, struggle to adapt to these conditions, leading to significant performance drops in drone-view scenarios. To bridge this gap, we introduce A2Seek (Aerial Anomaly Seek), a large-scale, reasoning-centric benchmark dataset for aerial anomaly understanding. This dataset covers various scenarios and environmental conditions, providing high-resolution real-world aerial videos with detailed annotations, including anomaly categories, frame-level timestamps, region-level bounding boxes, and natural language explanations for causal reasoning. Building on this dataset, we propose A2Seek-R1, a novel reasoning framework that generalizes R1-style strategies to aerial anomaly understanding, enabling a deeper understanding of "Where" anomalies occur and "Why" they happen in aerial frames. To this end, A2Seek-R1 first employs a graph-of-thought (GoT)-guided supervised fine-tuning approach to activate the model's latent reasoning capabilities on A2Seek. Then, we introduce Aerial Group Relative Policy Optimization (A-GRPO) to design rule-based reward functions tailored to aerial scenarios. Furthermore, we propose a novel "seeking" mechanism that simulates UAV flight behavior by directing the model's attention to informative regions. Extensive experiments demonstrate that A2Seek-R1 achieves up to a 22.04% improvement in AP for prediction accuracy and a 13.9% gain in mIoU for anomaly localization, exhibiting strong generalization across complex environments and out-of-distribution scenarios. Our dataset and code will be released at https://hayneyday.github.io/A2Seek/.
YOLO-PRO: Enhancing Instance-Specific Object Detection with Full-Channel Global Self-Attention
Mar 04, 2025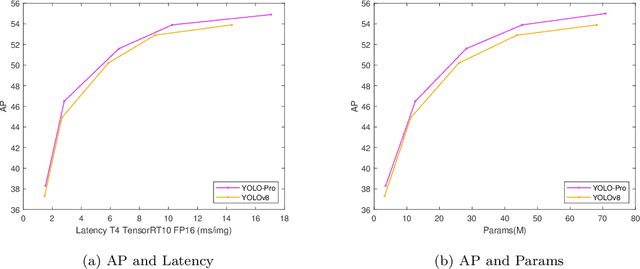
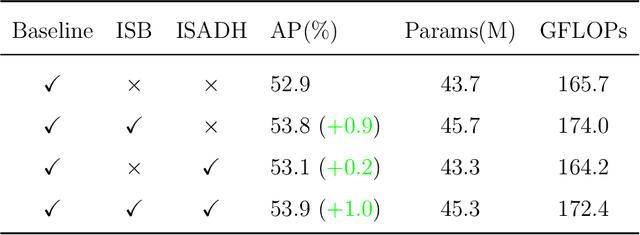
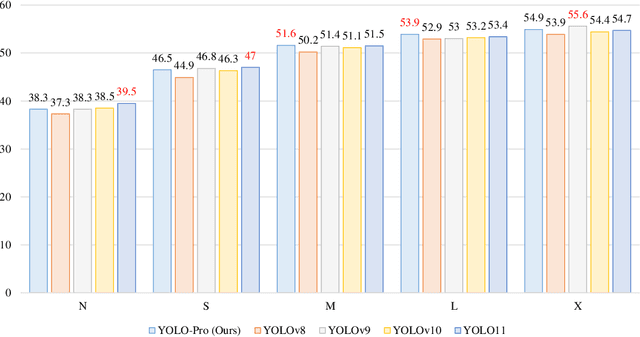
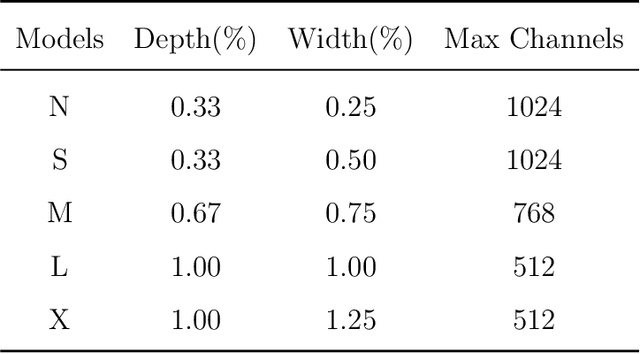
This paper addresses the inherent limitations of conventional bottleneck structures (diminished instance discriminability due to overemphasis on batch statistics) and decoupled heads (computational redundancy) in object detection frameworks by proposing two novel modules: the Instance-Specific Bottleneck with full-channel global self-attention (ISB) and the Instance-Specific Asymmetric Decoupled Head (ISADH). The ISB module innovatively reconstructs feature maps to establish an efficient full-channel global attention mechanism through synergistic fusion of batch-statistical and instance-specific features. Complementing this, the ISADH module pioneers an asymmetric decoupled architecture enabling hierarchical multi-dimensional feature integration via dual-stream batch-instance representation fusion. Extensive experiments on the MS-COCO benchmark demonstrate that the coordinated deployment of ISB and ISADH in the YOLO-PRO framework achieves state-of-the-art performance across all computational scales. Specifically, YOLO-PRO surpasses YOLOv8 by 1.0-1.6% AP (N/S/M/L/X scales) and outperforms YOLO11 by 0.1-0.5% AP in critical M/L/X groups, while maintaining competitive computational efficiency. This work provides practical insights for developing high-precision detectors deployable on edge devices.
CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training
Dec 23, 2024Benefiting from large-scale pre-training of text-video pairs, current text-to-video (T2V) diffusion models can generate high-quality videos from the text description. Besides, given some reference images or videos, the parameter-efficient fine-tuning method, i.e. LoRA, can generate high-quality customized concepts, e.g., the specific subject or the motions from a reference video. However, combining the trained multiple concepts from different references into a single network shows obvious artifacts. To this end, we propose CustomTTT, where we can joint custom the appearance and the motion of the given video easily. In detail, we first analyze the prompt influence in the current video diffusion model and find the LoRAs are only needed for the specific layers for appearance and motion customization. Besides, since each LoRA is trained individually, we propose a novel test-time training technique to update parameters after combination utilizing the trained customized models. We conduct detailed experiments to verify the effectiveness of the proposed methods. Our method outperforms several state-of-the-art works in both qualitative and quantitative evaluations.
Rethinking Normalization Strategies and Convolutional Kernels for Multimodal Image Fusion
Nov 15, 2024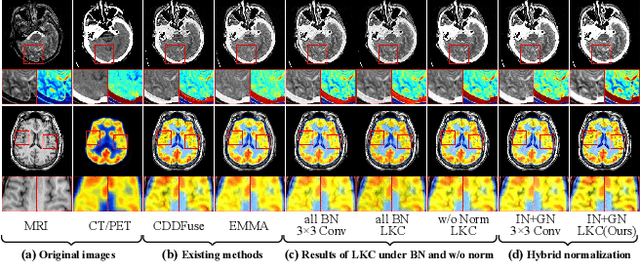

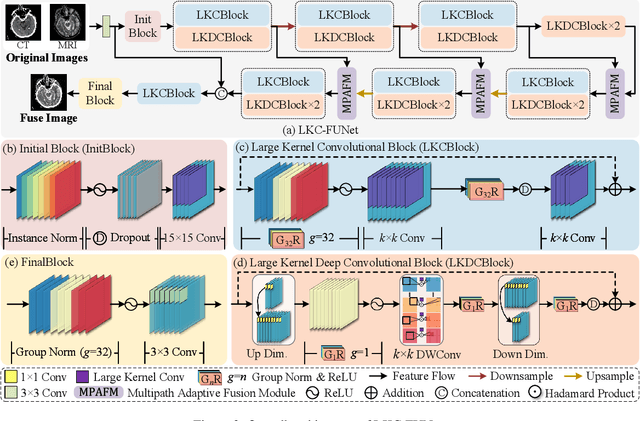
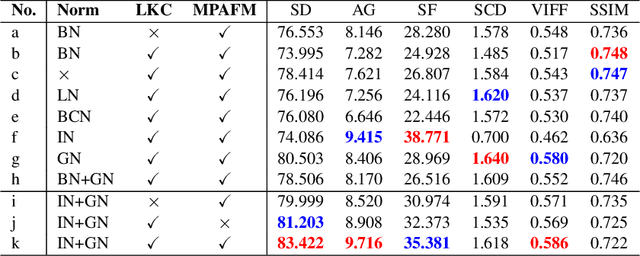
Multimodal image fusion (MMIF) aims to integrate information from different modalities to obtain a comprehensive image, aiding downstream tasks. However, existing methods tend to prioritize natural image fusion and focus on information complementary and network training strategies. They ignore the essential distinction between natural and medical image fusion and the influence of underlying components. This paper dissects the significant differences between the two tasks regarding fusion goals, statistical properties, and data distribution. Based on this, we rethink the suitability of the normalization strategy and convolutional kernels for end-to-end MMIF.Specifically, this paper proposes a mixture of instance normalization and group normalization to preserve sample independence and reinforce intrinsic feature correlation.This strategy promotes the potential of enriching feature maps, thus boosting fusion performance. To this end, we further introduce the large kernel convolution, effectively expanding receptive fields and enhancing the preservation of image detail. Moreover, the proposed multipath adaptive fusion module recalibrates the decoder input with features of various scales and receptive fields, ensuring the transmission of crucial information. Extensive experiments demonstrate that our method exhibits state-of-the-art performance in multiple fusion tasks and significantly improves downstream applications. The code is available at https://github.com/HeDan-11/LKC-FUNet.
Score-based Generative Priors Guided Model-driven Network for MRI Reconstruction
May 05, 2024



Score matching with Langevin dynamics (SMLD) method has been successfully applied to accelerated MRI. However, the hyperparameters in the sampling process require subtle tuning, otherwise the results can be severely corrupted by hallucination artifacts, particularly with out-of-distribution test data. In this study, we propose a novel workflow in which SMLD results are regarded as additional priors to guide model-driven network training. First, we adopted a pretrained score network to obtain samples as preliminary guidance images (PGI) without the need for network retraining, parameter tuning and in-distribution test data. Although PGIs are corrupted by hallucination artifacts, we believe that they can provide extra information through effective denoising steps to facilitate reconstruction. Therefore, we designed a denoising module (DM) in the second step to improve the quality of PGIs. The features are extracted from the components of Langevin dynamics and the same score network with fine-tuning; hence, we can directly learn the artifact patterns. Third, we designed a model-driven network whose training is guided by denoised PGIs (DGIs). DGIs are densely connected with intermediate reconstructions in each cascade to enrich the features and are periodically updated to provide more accurate guidance. Our experiments on different sequences revealed that despite the low average quality of PGIs, the proposed workflow can effectively extract valuable information to guide the network training, even with severely reduced training data and sampling steps. Our method outperforms other cutting-edge techniques by effectively mitigating hallucination artifacts, yielding robust and high-quality reconstruction results.
A Collaborative Model-driven Network for MRI Reconstruction
Feb 04, 2024



Magnetic resonance imaging (MRI) is a vital medical imaging modality, but its development has been limited by prolonged scanning time. Deep learning (DL)-based methods, which build neural networks to reconstruct MR images from undersampled raw data, can reliably address this problem. Among these methods, model-driven DL methods incorporate different prior knowledge into deep networks, thereby narrowing the solution space and achieving better results. However, the complementarity among different prior knowledge has not been thoroughly explored. Most of the existing model-driven networks simply stack unrolled cascades to mimic iterative solution steps, which are inefficient and their performances are suboptimal. To optimize the conventional network structure, we propose a collaborative model-driven network. In the network, each unrolled cascade comprised three parts: model-driven subnetworks, attention modules, and correction modules. The attention modules can learn to enhance the areas of expertise for each subnetwork, and the correction modules can compensate for new errors caused by the attention modules. The optimized intermediate results are fed into the next cascade for better convergence. Experimental results on multiple sequences showed significant improvements in the final results without additional computational complexity. Moreover, the proposed model-driven network design strategy can be easily applied to other model-driven methods to improve their performances.
Detecting Generated Images by Real Images Only
Nov 02, 2023



As deep learning technology continues to evolve, the images yielded by generative models are becoming more and more realistic, triggering people to question the authenticity of images. Existing generated image detection methods detect visual artifacts in generated images or learn discriminative features from both real and generated images by massive training. This learning paradigm will result in efficiency and generalization issues, making detection methods always lag behind generation methods. This paper approaches the generated image detection problem from a new perspective: Start from real images. By finding the commonality of real images and mapping them to a dense subspace in feature space, the goal is that generated images, regardless of their generative model, are then projected outside the subspace. As a result, images from different generative models can be detected, solving some long-existing problems in the field. Experimental results show that although our method was trained only by real images and uses 99.9\% less training data than other deep learning-based methods, it can compete with state-of-the-art methods and shows excellent performance in detecting emerging generative models with high inference efficiency. Moreover, the proposed method shows robustness against various post-processing. These advantages allow the method to be used in real-world scenarios.