 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDM-FNet: Unified multimodal medical image fusion via diffusion process-trained encoder-decoder
Jun 18, 2025Multimodal medical image fusion (MMIF) extracts the most meaningful information from multiple source images, enabling a more comprehensive and accurate diagnosis. Achieving high-quality fusion results requires a careful balance of brightness, color, contrast, and detail; this ensures that the fused images effectively display relevant anatomical structures and reflect the functional status of the tissues. However, existing MMIF methods have limited capacity to capture detailed features during conventional training and suffer from insufficient cross-modal feature interaction, leading to suboptimal fused image quality. To address these issues, this study proposes a two-stage diffusion model-based fusion network (DM-FNet) to achieve unified MMIF. In Stage I, a diffusion process trains UNet for image reconstruction. UNet captures detailed information through progressive denoising and represents multilevel data, providing a rich set of feature representations for the subsequent fusion network. In Stage II, noisy images at various steps are input into the fusion network to enhance the model's feature recognition capability. Three key fusion modules are also integrated to process medical images from different modalities adaptively. Ultimately, the robust network structure and a hybrid loss function are integrated to harmonize the fused image's brightness, color, contrast, and detail, enhancing its quality and information density. The experimental results across various medical image types demonstrate that the proposed method performs exceptionally well regarding objective evaluation metrics. The fused image preserves appropriate brightness, a comprehensive distribution of radioactive tracers, rich textures, and clear edges. The code is available at https://github.com/HeDan-11/DM-FNet.
Rethinking Normalization Strategies and Convolutional Kernels for Multimodal Image Fusion
Nov 15, 2024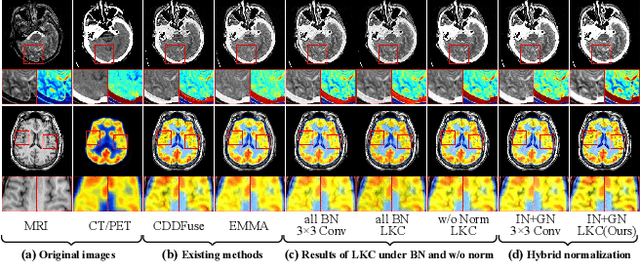

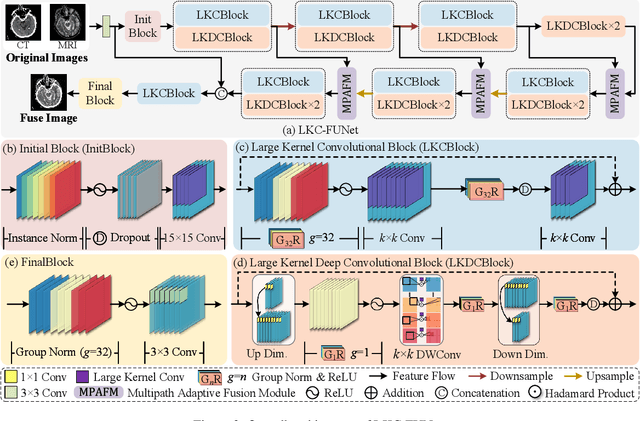
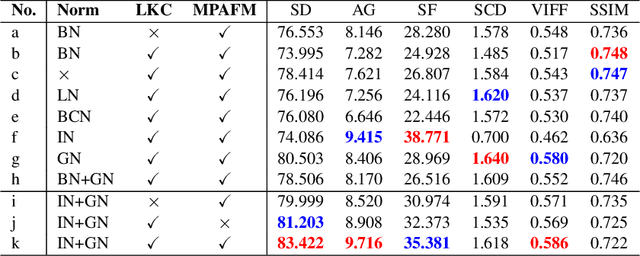
Multimodal image fusion (MMIF) aims to integrate information from different modalities to obtain a comprehensive image, aiding downstream tasks. However, existing methods tend to prioritize natural image fusion and focus on information complementary and network training strategies. They ignore the essential distinction between natural and medical image fusion and the influence of underlying components. This paper dissects the significant differences between the two tasks regarding fusion goals, statistical properties, and data distribution. Based on this, we rethink the suitability of the normalization strategy and convolutional kernels for end-to-end MMIF.Specifically, this paper proposes a mixture of instance normalization and group normalization to preserve sample independence and reinforce intrinsic feature correlation.This strategy promotes the potential of enriching feature maps, thus boosting fusion performance. To this end, we further introduce the large kernel convolution, effectively expanding receptive fields and enhancing the preservation of image detail. Moreover, the proposed multipath adaptive fusion module recalibrates the decoder input with features of various scales and receptive fields, ensuring the transmission of crucial information. Extensive experiments demonstrate that our method exhibits state-of-the-art performance in multiple fusion tasks and significantly improves downstream applications. The code is available at https://github.com/HeDan-11/LKC-FUNet.
Enhancing Multistep Prediction of Multivariate Market Indices Using Weighted Optical Reservoir Computing
Aug 01, 2024



We propose and experimentally demonstrate an innovative stock index prediction method using a weighted optical reservoir computing system. We construct fundamental market data combined with macroeconomic data and technical indicators to capture the broader behavior of the stock market. Our approach shows significant higher performance than state-of-the-art methods such as linear regression, decision trees, and neural network architectures including long short-term memory. It captures well the market's high volatility and nonlinear behaviors despite limited data, demonstrating great potential for real-time, parallel, multi-dimensional data processing and predictions.
Score-based Generative Priors Guided Model-driven Network for MRI Reconstruction
May 05, 2024



Score matching with Langevin dynamics (SMLD) method has been successfully applied to accelerated MRI. However, the hyperparameters in the sampling process require subtle tuning, otherwise the results can be severely corrupted by hallucination artifacts, particularly with out-of-distribution test data. In this study, we propose a novel workflow in which SMLD results are regarded as additional priors to guide model-driven network training. First, we adopted a pretrained score network to obtain samples as preliminary guidance images (PGI) without the need for network retraining, parameter tuning and in-distribution test data. Although PGIs are corrupted by hallucination artifacts, we believe that they can provide extra information through effective denoising steps to facilitate reconstruction. Therefore, we designed a denoising module (DM) in the second step to improve the quality of PGIs. The features are extracted from the components of Langevin dynamics and the same score network with fine-tuning; hence, we can directly learn the artifact patterns. Third, we designed a model-driven network whose training is guided by denoised PGIs (DGIs). DGIs are densely connected with intermediate reconstructions in each cascade to enrich the features and are periodically updated to provide more accurate guidance. Our experiments on different sequences revealed that despite the low average quality of PGIs, the proposed workflow can effectively extract valuable information to guide the network training, even with severely reduced training data and sampling steps. Our method outperforms other cutting-edge techniques by effectively mitigating hallucination artifacts, yielding robust and high-quality reconstruction results.
A Collaborative Model-driven Network for MRI Reconstruction
Feb 04, 2024



Magnetic resonance imaging (MRI) is a vital medical imaging modality, but its development has been limited by prolonged scanning time. Deep learning (DL)-based methods, which build neural networks to reconstruct MR images from undersampled raw data, can reliably address this problem. Among these methods, model-driven DL methods incorporate different prior knowledge into deep networks, thereby narrowing the solution space and achieving better results. However, the complementarity among different prior knowledge has not been thoroughly explored. Most of the existing model-driven networks simply stack unrolled cascades to mimic iterative solution steps, which are inefficient and their performances are suboptimal. To optimize the conventional network structure, we propose a collaborative model-driven network. In the network, each unrolled cascade comprised three parts: model-driven subnetworks, attention modules, and correction modules. The attention modules can learn to enhance the areas of expertise for each subnetwork, and the correction modules can compensate for new errors caused by the attention modules. The optimized intermediate results are fed into the next cascade for better convergence. Experimental results on multiple sequences showed significant improvements in the final results without additional computational complexity. Moreover, the proposed model-driven network design strategy can be easily applied to other model-driven methods to improve their performances.
Robust and Efficient Single-Pixel Image Classificationwith Nonlinear Optics
Jan 27, 2021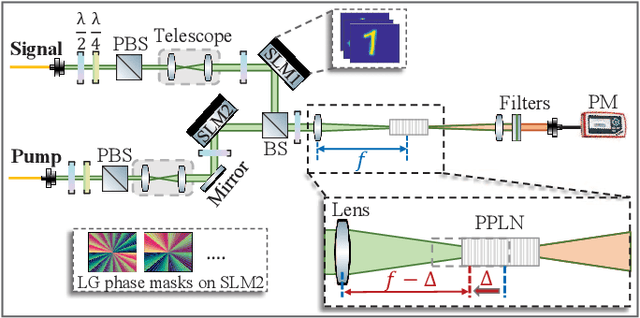
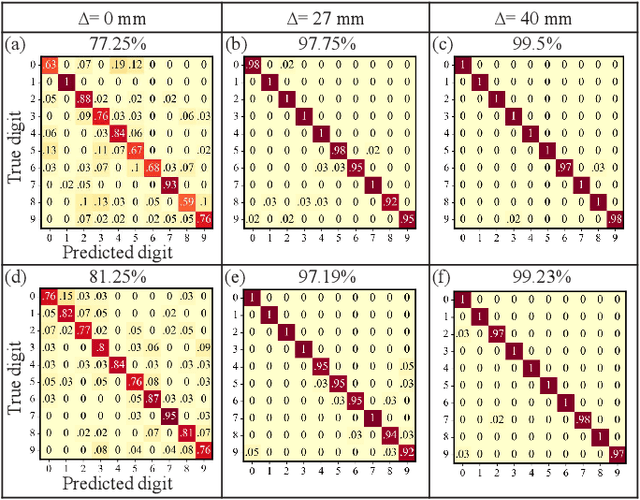
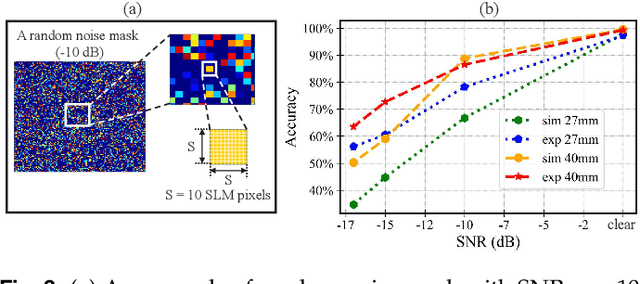
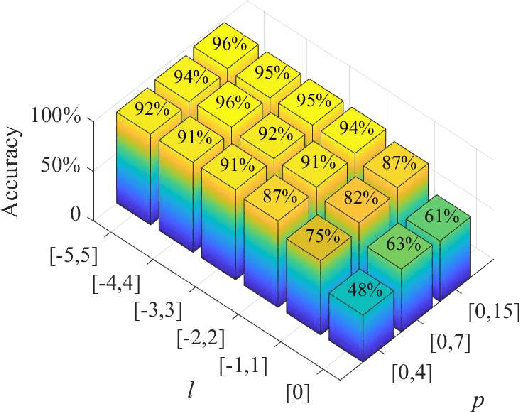
We present a hybrid image classifier by mode-selective image upconversion, single pixel photodetection, and deep learning, aiming at fast processing a large number of pixels. It utilizes partial Fourier transform to extract the signature features of images in both the original and Fourier domains, thereby significantly increasing the classification accuracy and robustness. Tested on the MNIST handwritten digit images, it boosts the accuracy from 81.25% to 99.23%, and achieves an 83% accuracy for highly contaminated images whose signal-to-noise ratio is only -17 dB. Our approach could prove useful for fast lidar data processing, high resolution image recognition, occluded target identification, atmosphere monitoring, and so on.