 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating an evidence-guided reinforcement learning framework in aligning light-parameter large language models with decision-making cognition in psychiatric clinical reasoning
Feb 06, 2026Large language models (LLMs) hold transformative potential for medical decision support yet their application in psychiatry remains constrained by hallucinations and superficial reasoning. This limitation is particularly acute in light-parameter LLMs which are essential for privacy-preserving and efficient clinical deployment. Existing training paradigms prioritize linguistic fluency over structured clinical logic and result in a fundamental misalignment with professional diagnostic cognition. Here we introduce ClinMPO, a reinforcement learning framework designed to align the internal reasoning of LLMs with professional psychiatric practice. The framework employs a specialized reward model trained independently on a dataset derived from 4,474 psychiatry journal articles and structured according to evidence-based medicine principles. We evaluated ClinMPO on a unseen subset of the benchmark designed to isolate reasoning capabilities from rote memorization. This test set comprises items where leading large-parameter LLMs consistently fail. We compared the ClinMPO-aligned light LLM performance against a cohort of 300 medical students. The ClinMPO-tuned Qwen3-8B model achieved a diagnostic accuracy of 31.4% and surpassed the human benchmark of 30.8% on these complex cases. These results demonstrate that medical evidence-guided optimization enables light-parameter LLMs to master complex reasoning tasks. Our findings suggest that explicit cognitive alignment offers a scalable pathway to reliable and safe psychiatric decision support.
GenePheno: Interpretable Gene Knockout-Induced Phenotype Abnormality Prediction from Gene Sequences
Nov 14, 2025
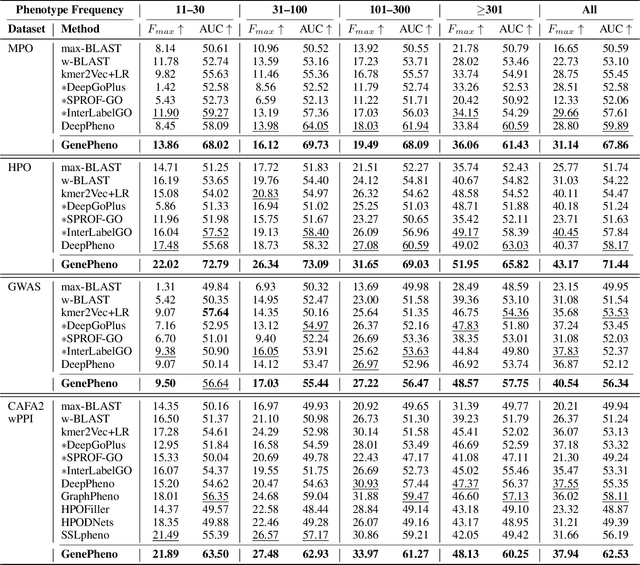
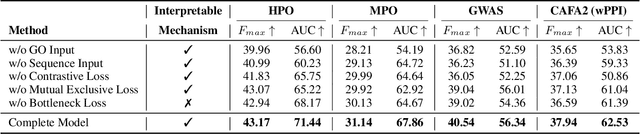
Exploring how genetic sequences shape phenotypes is a fundamental challenge in biology and a key step toward scalable, hypothesis-driven experimentation. The task is complicated by the large modality gap between sequences and phenotypes, as well as the pleiotropic nature of gene-phenotype relationships. Existing sequence-based efforts focus on the degree to which variants of specific genes alter a limited set of phenotypes, while general gene knockout induced phenotype abnormality prediction methods heavily rely on curated genetic information as inputs, which limits scalability and generalizability. As a result, the task of broadly predicting the presence of multiple phenotype abnormalities under gene knockout directly from gene sequences remains underexplored. We introduce GenePheno, the first interpretable multi-label prediction framework that predicts knockout induced phenotypic abnormalities from gene sequences. GenePheno employs a contrastive multi-label learning objective that captures inter-phenotype correlations, complemented by an exclusive regularization that enforces biological consistency. It further incorporates a gene function bottleneck layer, offering human interpretable concepts that reflect functional mechanisms behind phenotype formation. To support progress in this area, we curate four datasets with canonical gene sequences as input and multi-label phenotypic abnormalities induced by gene knockouts as targets. Across these datasets, GenePheno achieves state-of-the-art gene-centric $F_{\text{max}}$ and phenotype-centric AUC, and case studies demonstrate its ability to reveal gene functional mechanisms.
Learning Heterogeneous Mixture of Scene Experts for Large-scale Neural Radiance Fields
May 04, 2025Recent NeRF methods on large-scale scenes have underlined the importance of scene decomposition for scalable NeRFs. Although achieving reasonable scalability, there are several critical problems remaining unexplored, i.e., learnable decomposition, modeling scene heterogeneity, and modeling efficiency. In this paper, we introduce Switch-NeRF++, a Heterogeneous Mixture of Hash Experts (HMoHE) network that addresses these challenges within a unified framework. It is a highly scalable NeRF that learns heterogeneous decomposition and heterogeneous NeRFs efficiently for large-scale scenes in an end-to-end manner. In our framework, a gating network learns to decomposes scenes and allocates 3D points to specialized NeRF experts. This gating network is co-optimized with the experts, by our proposed Sparsely Gated Mixture of Experts (MoE) NeRF framework. We incorporate a hash-based gating network and distinct heterogeneous hash experts. The hash-based gating efficiently learns the decomposition of the large-scale scene. The distinct heterogeneous hash experts consist of hash grids of different resolution ranges, enabling effective learning of the heterogeneous representation of different scene parts. These design choices make our framework an end-to-end and highly scalable NeRF solution for real-world large-scale scene modeling to achieve both quality and efficiency. We evaluate our accuracy and scalability on existing large-scale NeRF datasets and a new dataset with very large-scale scenes ($>6.5km^2$) from UrbanBIS. Extensive experiments demonstrate that our approach can be easily scaled to various large-scale scenes and achieve state-of-the-art scene rendering accuracy. Furthermore, our method exhibits significant efficiency, with an 8x acceleration in training and a 16x acceleration in rendering compared to Switch-NeRF. Codes will be released in https://github.com/MiZhenxing/Switch-NeRF.
ASLoRA: Adaptive Sharing Low-Rank Adaptation Across Layers
Dec 13, 2024



As large language models (LLMs) grow in size, traditional full fine-tuning becomes increasingly impractical due to its high computational and storage costs. Although popular parameter-efficient fine-tuning methods, such as LoRA, have significantly reduced the number of tunable parameters, there is still room for further optimization. In this work, we propose ASLoRA, a cross-layer parameter-sharing strategy combining global sharing with partial adaptive sharing. Specifically, we share the low-rank matrix A across all layers and adaptively merge matrix B during training. This sharing mechanism not only mitigates overfitting effectively but also captures inter-layer dependencies, significantly enhancing the model's representational capability. We conduct extensive experiments on various NLP tasks, showing that ASLoRA outperforms LoRA while using less than 25% of the parameters, highlighting its flexibility and superior parameter efficiency. Furthermore, in-depth analyses of the adaptive sharing strategy confirm its significant advantages in enhancing both model flexibility and task adaptability.
High-Performance Fine Defect Detection in Artificial Leather Using Dual Feature Pool Object Detection
Aug 16, 2023



In this study, the structural problems of the YOLOv5 model were analyzed emphatically. Based on the characteristics of fine defects in artificial leather, four innovative structures, namely DFP, IFF, AMP, and EOS, were designed. These advancements led to the proposal of a high-performance artificial leather fine defect detection model named YOLOD. YOLOD demonstrated outstanding performance on the artificial leather defect dataset, achieving an impressive increase of 11.7% - 13.5% in AP_50 compared to YOLOv5, along with a significant reduction of 5.2% - 7.2% in the error detection rate. Moreover, YOLOD also exhibited remarkable performance on the general MS-COCO dataset, with an increase of 0.4% - 2.6% in AP compared to YOLOv5, and a rise of 2.5% - 4.1% in AP_S compared to YOLOv5. These results demonstrate the superiority of YOLOD in both artificial leather defect detection and general object detection tasks, making it a highly efficient and effective model for real-world applications.
YOLOCS: Object Detection based on Dense Channel Compression for Feature Spatial Solidification
May 07, 2023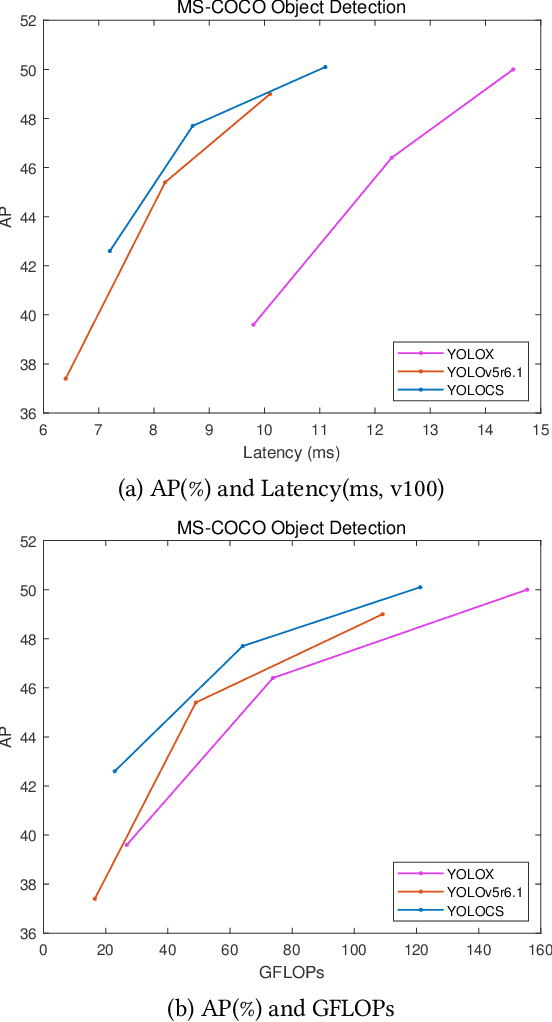
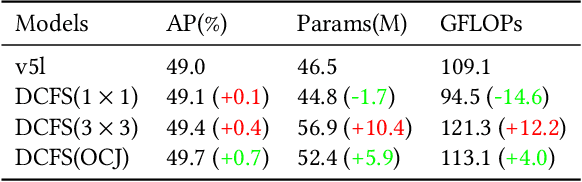
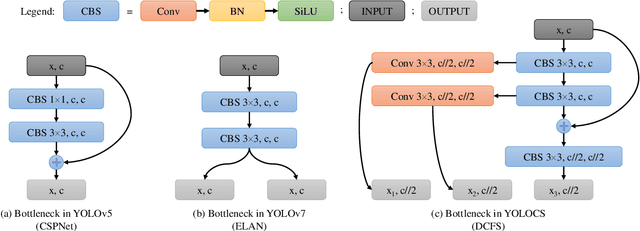
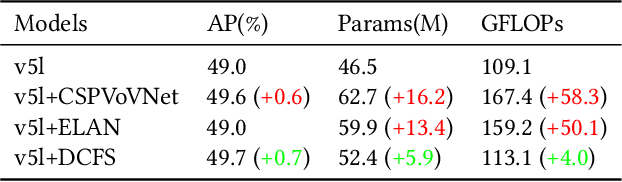
In this study, we examine the associations between channel features and convolutional kernels during the processes of feature purification and gradient backpropagation, with a focus on the forward and backward propagation within the network. Consequently, we propose a method called Dense Channel Compression for Feature Spatial Solidification. Drawing upon the central concept of this method, we introduce two innovative modules for backbone and head networks: the Dense Channel Compression for Feature Spatial Solidification Structure (DCFS) and the Asymmetric Multi-Level Compression Decoupled Head (ADH). When integrated into the YOLOv5 model, these two modules demonstrate exceptional performance, resulting in a modified model referred to as YOLOCS. Evaluated on the MSCOCO dataset, the large, medium, and small YOLOCS models yield AP of 50.1%, 47.6%, and 42.5%, respectively. Maintaining inference speeds remarkably similar to those of the YOLOv5 model, the large, medium, and small YOLOCS models surpass the YOLOv5 model's AP by 1.1%, 2.3%, and 5.2%, respectively.