 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Heterogeneous Mixture of Scene Experts for Large-scale Neural Radiance Fields
May 04, 2025Recent NeRF methods on large-scale scenes have underlined the importance of scene decomposition for scalable NeRFs. Although achieving reasonable scalability, there are several critical problems remaining unexplored, i.e., learnable decomposition, modeling scene heterogeneity, and modeling efficiency. In this paper, we introduce Switch-NeRF++, a Heterogeneous Mixture of Hash Experts (HMoHE) network that addresses these challenges within a unified framework. It is a highly scalable NeRF that learns heterogeneous decomposition and heterogeneous NeRFs efficiently for large-scale scenes in an end-to-end manner. In our framework, a gating network learns to decomposes scenes and allocates 3D points to specialized NeRF experts. This gating network is co-optimized with the experts, by our proposed Sparsely Gated Mixture of Experts (MoE) NeRF framework. We incorporate a hash-based gating network and distinct heterogeneous hash experts. The hash-based gating efficiently learns the decomposition of the large-scale scene. The distinct heterogeneous hash experts consist of hash grids of different resolution ranges, enabling effective learning of the heterogeneous representation of different scene parts. These design choices make our framework an end-to-end and highly scalable NeRF solution for real-world large-scale scene modeling to achieve both quality and efficiency. We evaluate our accuracy and scalability on existing large-scale NeRF datasets and a new dataset with very large-scale scenes ($>6.5km^2$) from UrbanBIS. Extensive experiments demonstrate that our approach can be easily scaled to various large-scale scenes and achieve state-of-the-art scene rendering accuracy. Furthermore, our method exhibits significant efficiency, with an 8x acceleration in training and a 16x acceleration in rendering compared to Switch-NeRF. Codes will be released in https://github.com/MiZhenxing/Switch-NeRF.
LeC$^2$O-NeRF: Learning Continuous and Compact Large-Scale Occupancy for Urban Scenes
Nov 18, 2024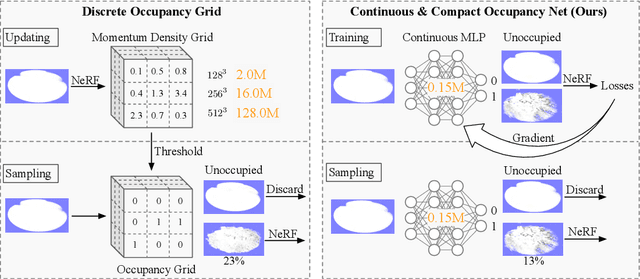
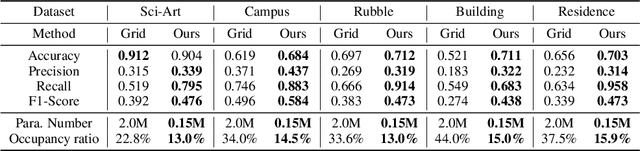
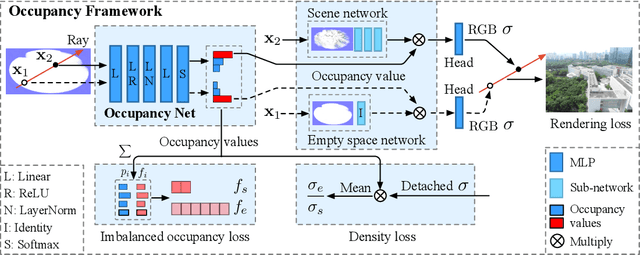
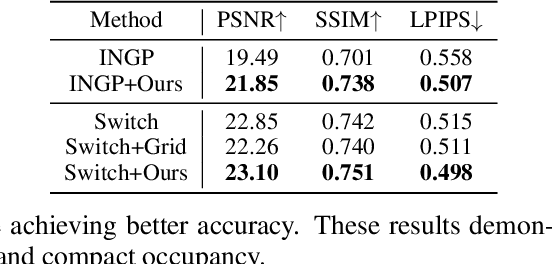
In NeRF, a critical problem is to effectively estimate the occupancy to guide empty-space skipping and point sampling. Grid-based methods work well for small-scale scenes. However, on large-scale scenes, they are limited by predefined bounding boxes, grid resolutions, and high memory usage for grid updates, and thus struggle to speed up training for large-scale, irregularly bounded and complex urban scenes without sacrificing accuracy. In this paper, we propose to learn a continuous and compact large-scale occupancy network, which can classify 3D points as occupied or unoccupied points. We train this occupancy network end-to-end together with the radiance field in a self-supervised manner by three designs. First, we propose a novel imbalanced occupancy loss to regularize the occupancy network. It makes the occupancy network effectively control the ratio of unoccupied and occupied points, motivated by the prior that most of 3D scene points are unoccupied. Second, we design an imbalanced architecture containing a large scene network and a small empty space network to separately encode occupied and unoccupied points classified by the occupancy network. This imbalanced structure can effectively model the imbalanced nature of occupied and unoccupied regions. Third, we design an explicit density loss to guide the occupancy network, making the density of unoccupied points smaller. As far as we know, we are the first to learn a continuous and compact occupancy of large-scale NeRF by a network. In our experiments, our occupancy network can quickly learn more compact, accurate and smooth occupancy compared to the occupancy grid. With our learned occupancy as guidance for empty space skipping on challenging large-scale benchmarks, our method consistently obtains higher accuracy compared to the occupancy grid, and our method can speed up state-of-the-art NeRF methods without sacrificing accuracy.
Generalized Binary Search Network for Highly-Efficient Multi-View Stereo
Dec 04, 2021

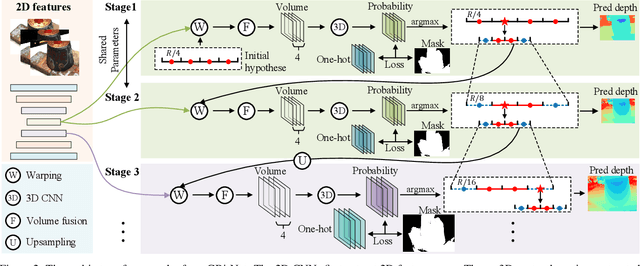
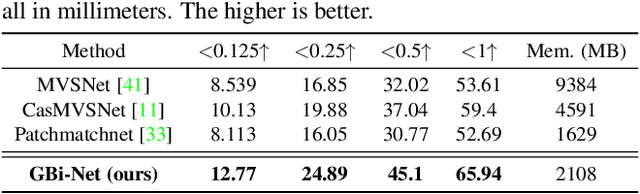
Multi-view Stereo (MVS) with known camera parameters is essentially a 1D search problem within a valid depth range. Recent deep learning-based MVS methods typically densely sample depth hypotheses in the depth range, and then construct prohibitively memory-consuming 3D cost volumes for depth prediction. Although coarse-to-fine sampling strategies alleviate this overhead issue to a certain extent, the efficiency of MVS is still an open challenge. In this work, we propose a novel method for highly efficient MVS that remarkably decreases the memory footprint, meanwhile clearly advancing state-of-the-art depth prediction performance. We investigate what a search strategy can be reasonably optimal for MVS taking into account of both efficiency and effectiveness. We first formulate MVS as a binary search problem, and accordingly propose a generalized binary search network for MVS. Specifically, in each step, the depth range is split into 2 bins with extra 1 error tolerance bin on both sides. A classification is performed to identify which bin contains the true depth. We also design three mechanisms to respectively handle classification errors, deal with out-of-range samples and decrease the training memory. The new formulation makes our method only sample a very small number of depth hypotheses in each step, which is highly memory efficient, and also greatly facilitates quick training convergence. Experiments on competitive benchmarks show that our method achieves state-of-the-art accuracy with much less memory. Particularly, our method obtains an overall score of 0.289 on DTU dataset and tops the first place on challenging Tanks and Temples advanced dataset among all the learning-based methods. The trained models and code will be released at https://github.com/MiZhenxing/GBi-Net.
DeepDT: Learning Geometry From Delaunay Triangulation for Surface Reconstruction
Jan 25, 2021



In this paper, a novel learning-based network, named DeepDT, is proposed to reconstruct the surface from Delaunay triangulation of point cloud. DeepDT learns to predict inside/outside labels of Delaunay tetrahedrons directly from a point cloud and corresponding Delaunay triangulation. The local geometry features are first extracted from the input point cloud and aggregated into a graph deriving from the Delaunay triangulation. Then a graph filtering is applied on the aggregated features in order to add structural regularization to the label prediction of tetrahedrons. Due to the complicated spatial relations between tetrahedrons and the triangles, it is impossible to directly generate ground truth labels of tetrahedrons from ground truth surface. Therefore, we propose a multilabel supervision strategy which votes for the label of a tetrahedron with labels of sampling locations inside it. The proposed DeepDT can maintain abundant geometry details without generating overly complex surfaces , especially for inner surfaces of open scenes. Meanwhile, the generalization ability and time consumption of the proposed method is acceptable and competitive compared with the state-of-the-art methods. Experiments demonstrate the superior performance of the proposed DeepDT.
TSRNet: Scalable 3D Surface Reconstruction Network for Point Clouds using Tangent Convolution
Nov 18, 2019


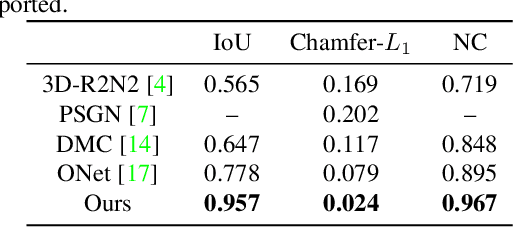
Existing learning-based surface reconstruction methods from point clouds are still facing challenges in terms of scalability and preservation of details on point clouds of large scales. In this paper, we propose the TSRNet, a novel scalable learning-based method for surface reconstruction. It first takes a point cloud and its related octree vertices as input and learns to classify whether the octree vertices are in front or at back of the implicit surface. Then the Marching Cubes (MC) is applied to extract a surface from the binary labeled octree. In our method, we design a scalable learning-based pipeline for surface reconstruction. It does not consider the whole input data at once. It allows to divide the point cloud and octree vertices and to process different parts in parallel. Our network captures local geometry details by constructing local geometry-aware features for octree vertices. The local geometry-aware features enhance the predication accuracy greatly for the relative position among the vertices and the implicit surface. They also boost the generalization capability of our network. Our method is able to reconstruct local geometry details from point clouds of different scales, especially for point clouds with millions of points. More importantly, the time consumption on such point clouds is acceptable and competitive. Experiments show that our method achieves a significant breakthrough in scalability and quality compared with state-of-the-art learning-based methods.