 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALLES: A Multi-agent LLMs-based Economic Sandbox with Consumer Preference Alignment
Mar 18, 2026In the real economy, modern decision-making is fundamentally challenged by high-dimensional, multimodal environments, which are further complicated by agent heterogeneity and combinatorial data sparsity. This paper introduces a Multi-Agent Large Language Model-based Economic Sandbox (MALLES), leveraging the inherent generalization capabilities of large-sacle models to establish a unified simulation framework applicable to cross-domain and cross-category scenarios. Central to our approach is a preference learning paradigm in which LLMs are economically aligned via post-training on extensive, heterogeneous transaction records across diverse product categories. This methodology enables the models to internalize and transfer latent consumer preference patterns, thereby mitigating the data sparsity issues prevalent in individual categories. To enhance simulation stability, we implement a mean-field mechanism designed to model the dynamic interactions between the product environment and customer populations, effectively stabilizing sampling processes within high-dimensional decision spaces. Furthermore, we propose a multi-agent discussion framework wherein specialized agents collaboratively process extensive product information. This architecture distributes cognitive load to alleviate single-agent attention bottlenecks and captures critical decision factors through structured dialogue. Experiments demonstrate that our framework achieves significant improvements in product selection accuracy, purchase quantity prediction, and simulation stability compared to existing economic and financial LLM simulation baselines. Our results substantiate the potential of large language models as a foundational pillar for high-fidelity, scalable decision simulation and latter analysis in the real economy based on foundational database.
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Jan 07, 2026Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.
PRISM: A Personality-Driven Multi-Agent Framework for Social Media Simulation
Dec 22, 2025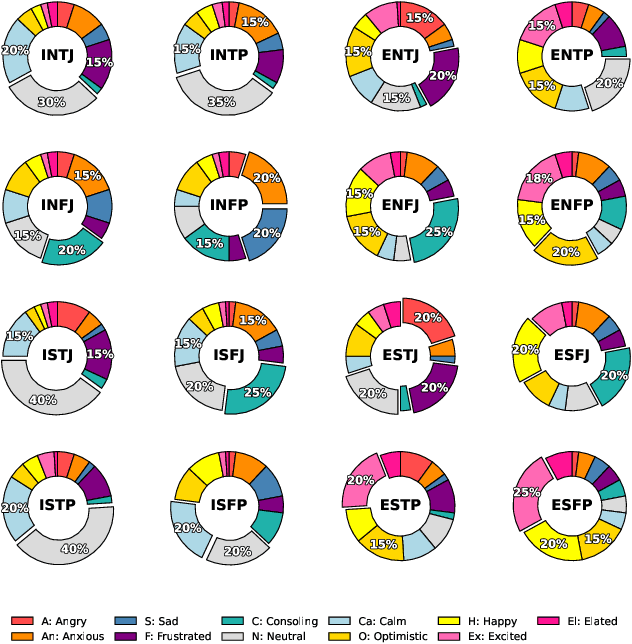
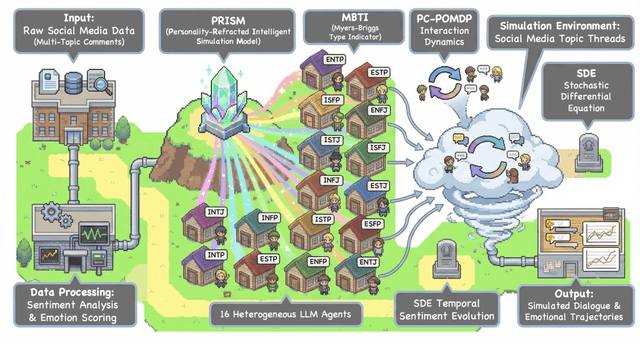
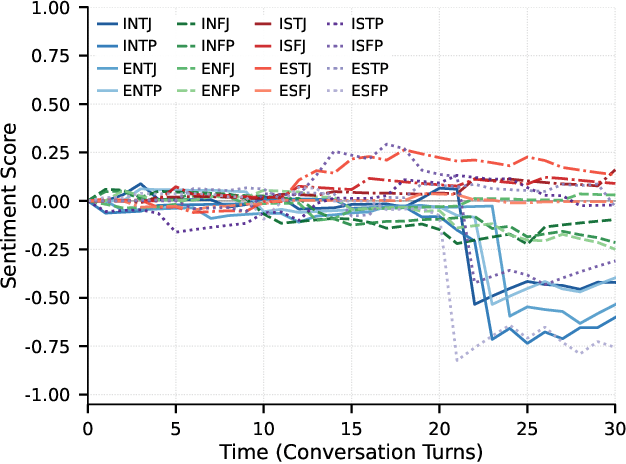

Traditional agent-based models (ABMs) of opinion dynamics often fail to capture the psychological heterogeneity driving online polarization due to simplistic homogeneity assumptions. This limitation obscures the critical interplay between individual cognitive biases and information propagation, thereby hindering a mechanistic understanding of how ideological divides are amplified. To address this challenge, we introduce the Personality-Refracted Intelligent Simulation Model (PRISM), a hybrid framework coupling stochastic differential equations (SDE) for continuous emotional evolution with a personality-conditional partially observable Markov decision process (PC-POMDP) for discrete decision-making. In contrast to continuous trait approaches, PRISM assigns distinct Myers-Briggs Type Indicator (MBTI) based cognitive policies to multimodal large language model (MLLM) agents, initialized via data-driven priors from large-scale social media datasets. PRISM achieves superior personality consistency aligned with human ground truth, significantly outperforming standard homogeneous and Big Five benchmarks. This framework effectively replicates emergent phenomena such as rational suppression and affective resonance, offering a robust tool for analyzing complex social media ecosystems.
A2Seek: Towards Reasoning-Centric Benchmark for Aerial Anomaly Understanding
May 28, 2025While unmanned aerial vehicles (UAVs) offer wide-area, high-altitude coverage for anomaly detection, they face challenges such as dynamic viewpoints, scale variations, and complex scenes. Existing datasets and methods, mainly designed for fixed ground-level views, struggle to adapt to these conditions, leading to significant performance drops in drone-view scenarios. To bridge this gap, we introduce A2Seek (Aerial Anomaly Seek), a large-scale, reasoning-centric benchmark dataset for aerial anomaly understanding. This dataset covers various scenarios and environmental conditions, providing high-resolution real-world aerial videos with detailed annotations, including anomaly categories, frame-level timestamps, region-level bounding boxes, and natural language explanations for causal reasoning. Building on this dataset, we propose A2Seek-R1, a novel reasoning framework that generalizes R1-style strategies to aerial anomaly understanding, enabling a deeper understanding of "Where" anomalies occur and "Why" they happen in aerial frames. To this end, A2Seek-R1 first employs a graph-of-thought (GoT)-guided supervised fine-tuning approach to activate the model's latent reasoning capabilities on A2Seek. Then, we introduce Aerial Group Relative Policy Optimization (A-GRPO) to design rule-based reward functions tailored to aerial scenarios. Furthermore, we propose a novel "seeking" mechanism that simulates UAV flight behavior by directing the model's attention to informative regions. Extensive experiments demonstrate that A2Seek-R1 achieves up to a 22.04% improvement in AP for prediction accuracy and a 13.9% gain in mIoU for anomaly localization, exhibiting strong generalization across complex environments and out-of-distribution scenarios. Our dataset and code will be released at https://hayneyday.github.io/A2Seek/.
Beyond Euclidean: Dual-Space Representation Learning for Weakly Supervised Video Violence Detection
Sep 28, 2024



While numerous Video Violence Detection (VVD) methods have focused on representation learning in Euclidean space, they struggle to learn sufficiently discriminative features, leading to weaknesses in recognizing normal events that are visually similar to violent events (\emph{i.e.}, ambiguous violence). In contrast, hyperbolic representation learning, renowned for its ability to model hierarchical and complex relationships between events, has the potential to amplify the discrimination between visually similar events. Inspired by these, we develop a novel Dual-Space Representation Learning (DSRL) method for weakly supervised VVD to utilize the strength of both Euclidean and hyperbolic geometries, capturing the visual features of events while also exploring the intrinsic relations between events, thereby enhancing the discriminative capacity of the features. DSRL employs a novel information aggregation strategy to progressively learn event context in hyperbolic spaces, which selects aggregation nodes through layer-sensitive hyperbolic association degrees constrained by hyperbolic Dirichlet energy. Furthermore, DSRL attempts to break the cyber-balkanization of different spaces, utilizing cross-space attention to facilitate information interactions between Euclidean and hyperbolic space to capture better discriminative features for final violence detection. Comprehensive experiments demonstrate the effectiveness of our proposed DSRL.
An End-to-End Reinforcement Learning Based Approach for Micro-View Order-Dispatching in Ride-Hailing
Aug 20, 2024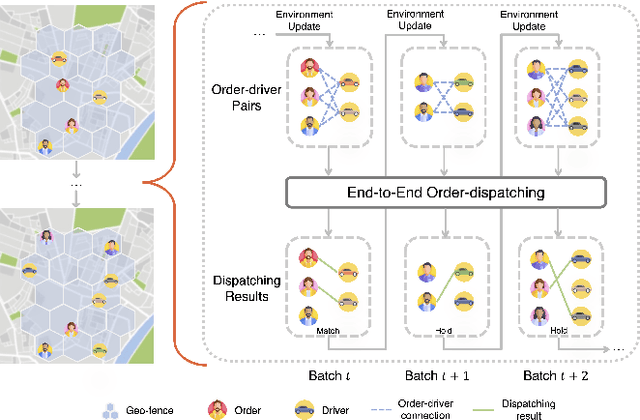

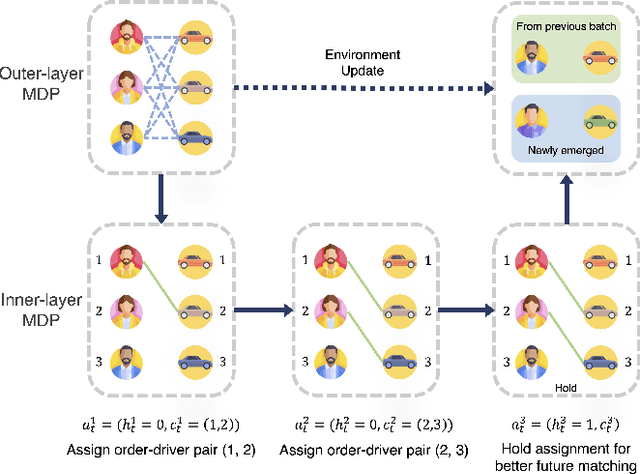

Assigning orders to drivers under localized spatiotemporal context (micro-view order-dispatching) is a major task in Didi, as it influences ride-hailing service experience. Existing industrial solutions mainly follow a two-stage pattern that incorporate heuristic or learning-based algorithms with naive combinatorial methods, tackling the uncertainty of both sides' behaviors, including emerging timings, spatial relationships, and travel duration, etc. In this paper, we propose a one-stage end-to-end reinforcement learning based order-dispatching approach that solves behavior prediction and combinatorial optimization uniformly in a sequential decision-making manner. Specifically, we employ a two-layer Markov Decision Process framework to model this problem, and present \underline{D}eep \underline{D}ouble \underline{S}calable \underline{N}etwork (D2SN), an encoder-decoder structure network to generate order-driver assignments directly and stop assignments accordingly. Besides, by leveraging contextual dynamics, our approach can adapt to the behavioral patterns for better performance. Extensive experiments on Didi's real-world benchmarks justify that the proposed approach significantly outperforms competitive baselines in optimizing matching efficiency and user experience tasks. In addition, we evaluate the deployment outline and discuss the gains and experiences obtained during the deployment tests from the view of large-scale engineering implementation.
Prejudice and Caprice: A Statistical Framework for Measuring Social Discrimination in Large Language Models
Feb 29, 2024



The growing integration of large language models (LLMs) into social operations amplifies their impact on decisions in crucial areas such as economics, law, education, and healthcare, raising public concerns about these models' discrimination-related safety and reliability. However, prior discrimination measuring frameworks solely assess the average discriminatory behavior of LLMs, often proving inadequate due to the overlook of an additional discrimination-leading factor, i.e., the LLMs' prediction variation across diverse contexts. In this work, we present the Prejudice-Caprice Framework (PCF) that comprehensively measures discrimination in LLMs by considering both their consistently biased preference and preference variation across diverse contexts. Specifically, we mathematically dissect the aggregated contextualized discrimination risk of LLMs into prejudice risk, originating from LLMs' persistent prejudice, and caprice risk, stemming from their generation inconsistency. In addition, we utilize a data-mining approach to gather preference-detecting probes from sentence skeletons, devoid of attribute indications, to approximate LLMs' applied contexts. While initially intended for assessing discrimination in LLMs, our proposed PCF facilitates the comprehensive and flexible measurement of any inductive biases, including knowledge alongside prejudice, across various modality models. We apply our discrimination-measuring framework to 12 common LLMs, yielding intriguing findings: i) modern LLMs demonstrate significant pro-male stereotypes, ii) LLMs' exhibited discrimination correlates with several social and economic factors, iii) prejudice risk dominates the overall discrimination risk and follows a normal distribution, and iv) caprice risk contributes minimally to the overall risk but follows a fat-tailed distribution, suggesting that it is wild risk requiring enhanced surveillance.
HandDiffuse: Generative Controllers for Two-Hand Interactions via Diffusion Models
Dec 08, 2023Existing hands datasets are largely short-range and the interaction is weak due to the self-occlusion and self-similarity of hands, which can not yet fit the need for interacting hands motion generation. To rescue the data scarcity, we propose HandDiffuse12.5M, a novel dataset that consists of temporal sequences with strong two-hand interactions. HandDiffuse12.5M has the largest scale and richest interactions among the existing two-hand datasets. We further present a strong baseline method HandDiffuse for the controllable motion generation of interacting hands using various controllers. Specifically, we apply the diffusion model as the backbone and design two motion representations for different controllers. To reduce artifacts, we also propose Interaction Loss which explicitly quantifies the dynamic interaction process. Our HandDiffuse enables various applications with vivid two-hand interactions, i.e., motion in-betweening and trajectory control. Experiments show that our method outperforms the state-of-the-art techniques in motion generation and can also contribute to data augmentation for other datasets. Our dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research towards two-hand interaction modeling.
Tuna: Instruction Tuning using Feedback from Large Language Models
Oct 20, 2023Instruction tuning of open-source large language models (LLMs) like LLaMA, using direct outputs from more powerful LLMs such as Instruct-GPT and GPT-4, has proven to be a cost-effective way to align model behaviors with human preferences. However, the instruction-tuned model has only seen one response per instruction, lacking the knowledge of potentially better responses. In this paper, we propose finetuning an instruction-tuned LLM using our novel \textit{probabilistic ranking} and \textit{contextual ranking} approaches to increase the likelihood of generating better responses. Probabilistic ranking enables the instruction-tuned model to inherit the relative rankings of high-quality and low-quality responses from the teacher LLM. On the other hand, learning with contextual ranking allows the model to refine its own response distribution using the contextual understanding ability of stronger LLMs. Furthermore, we apply probabilistic ranking and contextual ranking sequentially to the instruction-tuned LLM. The resulting model, which we call \textbf{Tuna}, consistently improves the performance on Super Natural Instructions (119 test tasks), LMentry (25 test tasks), Vicuna QA, and can even obtain better results than several strong reinforcement learning baselines. Our code and data are available at \url{ https://github.com/microsoft/LMOps}.
Momentum Calibration for Text Generation
Dec 08, 2022The input and output of most text generation tasks can be transformed to two sequences of tokens and they can be modeled using sequence-to-sequence learning modeling tools such as Transformers. These models are usually trained by maximizing the likelihood the output text sequence and assumes the input sequence and all gold preceding tokens are given during training, while during inference the model suffers from the exposure bias problem (i.e., it only has access to its previously predicted tokens rather gold tokens during beam search). In this paper, we propose MoCa ({\bf Mo}mentum {\bf Ca}libration) for text generation. MoCa is an online method that dynamically generates slowly evolving (but consistent) samples using a momentum moving average generator with beam search and MoCa learns to align its model scores of these samples with their actual qualities. Experiments on four text generation datasets (i.e., CNN/DailyMail, XSum, SAMSum and Gigaword) show MoCa consistently improves strong pre-trained transformers using vanilla fine-tuning and we achieve the state-of-the-art results on CNN/DailyMail and SAMSum datasets.