 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaF-VLA: Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
Jan 30, 2026Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.
Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
Jan 28, 2026Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.
PP-Tac: Paper Picking Using Tactile Feedback in Dexterous Robotic Hands
Apr 23, 2025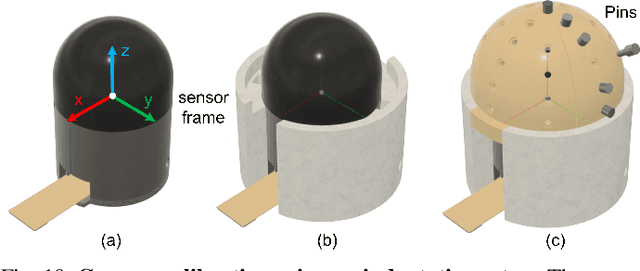
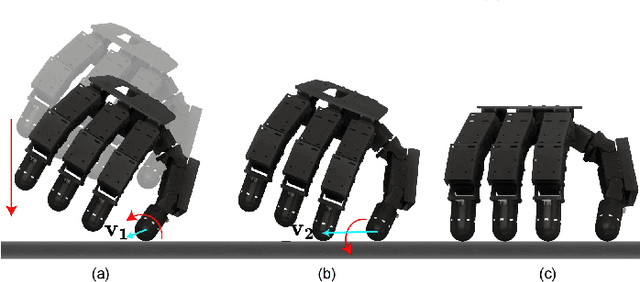
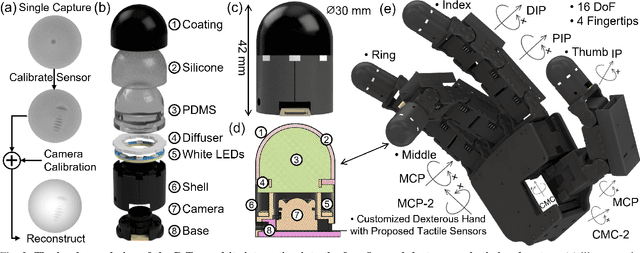
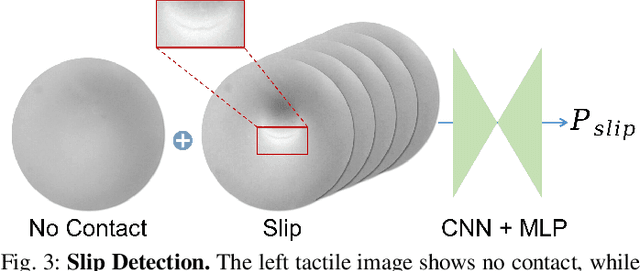
Robots are increasingly envisioned as human companions, assisting with everyday tasks that often involve manipulating deformable objects. Although recent advances in robotic hardware and embodied AI have expanded their capabilities, current systems still struggle with handling thin, flat, and deformable objects such as paper and fabric. This limitation arises from the lack of suitable perception techniques for robust state estimation under diverse object appearances, as well as the absence of planning techniques for generating appropriate grasp motions. To bridge these gaps, this paper introduces PP-Tac, a robotic system for picking up paper-like objects. PP-Tac features a multi-fingered robotic hand with high-resolution omnidirectional tactile sensors \sensorname. This hardware configuration enables real-time slip detection and online frictional force control that mitigates such slips. Furthermore, grasp motion generation is achieved through a trajectory synthesis pipeline, which first constructs a dataset of finger's pinching motions. Based on this dataset, a diffusion-based policy is trained to control the hand-arm robotic system. Experiments demonstrate that PP-Tac can effectively grasp paper-like objects of varying material, thickness, and stiffness, achieving an overall success rate of 87.5\%. To our knowledge, this work is the first attempt to grasp paper-like deformable objects using a tactile dexterous hand. Our project webpage can be found at: https://peilin-666.github.io/projects/PP-Tac/
Dual-Space Optimization: Improved Molecule Sequence Design by Latent Prompt Transformer
Feb 27, 2024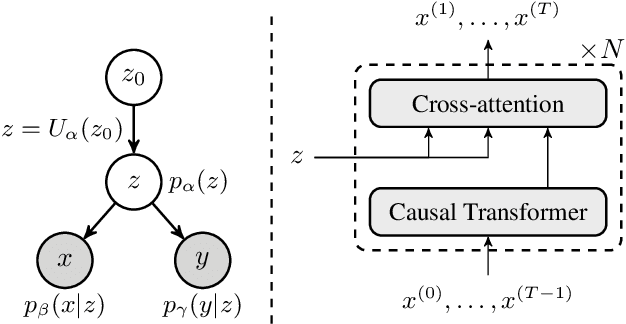
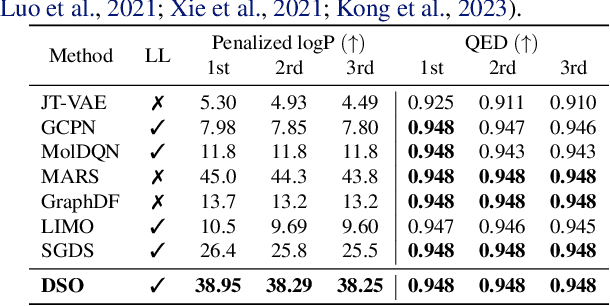
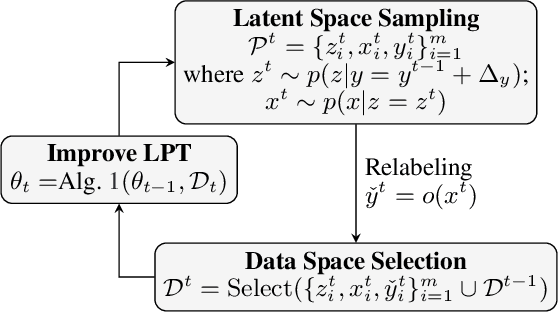
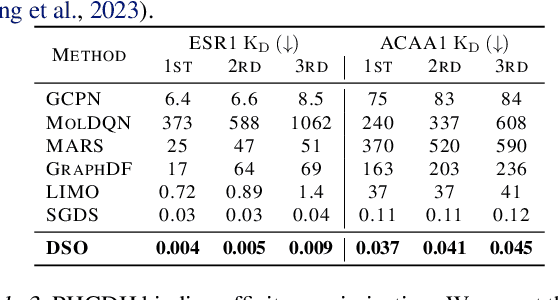
Designing molecules with desirable properties, such as drug-likeliness and high binding affinities towards protein targets, is a challenging problem. In this paper, we propose the Dual-Space Optimization (DSO) method that integrates latent space sampling and data space selection to solve this problem. DSO iteratively updates a latent space generative model and a synthetic dataset in an optimization process that gradually shifts the generative model and the synthetic data towards regions of desired property values. Our generative model takes the form of a Latent Prompt Transformer (LPT) where the latent vector serves as the prompt of a causal transformer. Our extensive experiments demonstrate effectiveness of the proposed method, which sets new performance benchmarks across single-objective, multi-objective and constrained molecule design tasks.
HandDiffuse: Generative Controllers for Two-Hand Interactions via Diffusion Models
Dec 08, 2023Existing hands datasets are largely short-range and the interaction is weak due to the self-occlusion and self-similarity of hands, which can not yet fit the need for interacting hands motion generation. To rescue the data scarcity, we propose HandDiffuse12.5M, a novel dataset that consists of temporal sequences with strong two-hand interactions. HandDiffuse12.5M has the largest scale and richest interactions among the existing two-hand datasets. We further present a strong baseline method HandDiffuse for the controllable motion generation of interacting hands using various controllers. Specifically, we apply the diffusion model as the backbone and design two motion representations for different controllers. To reduce artifacts, we also propose Interaction Loss which explicitly quantifies the dynamic interaction process. Our HandDiffuse enables various applications with vivid two-hand interactions, i.e., motion in-betweening and trajectory control. Experiments show that our method outperforms the state-of-the-art techniques in motion generation and can also contribute to data augmentation for other datasets. Our dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research towards two-hand interaction modeling.
HumanNeRF: Generalizable Neural Human Radiance Field from Sparse Inputs
Dec 15, 2021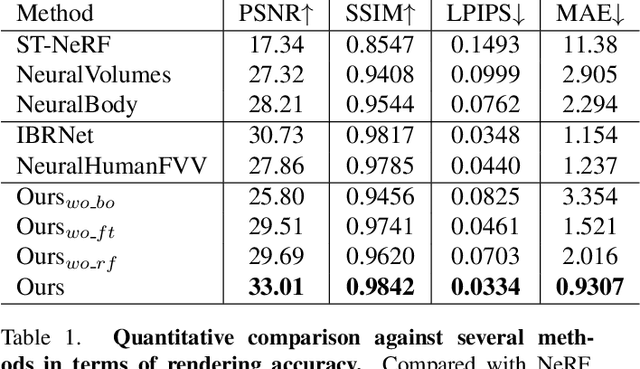

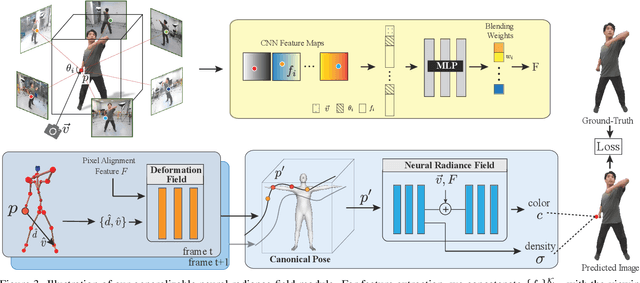

Recent neural human representations can produce high-quality multi-view rendering but require using dense multi-view inputs and costly training. They are hence largely limited to static models as training each frame is infeasible. We present HumanNeRF - a generalizable neural representation - for high-fidelity free-view synthesis of dynamic humans. Analogous to how IBRNet assists NeRF by avoiding per-scene training, HumanNeRF employs an aggregated pixel-alignment feature across multi-view inputs along with a pose embedded non-rigid deformation field for tackling dynamic motions. The raw HumanNeRF can already produce reasonable rendering on sparse video inputs of unseen subjects and camera settings. To further improve the rendering quality, we augment our solution with an appearance blending module for combining the benefits of both neural volumetric rendering and neural texture blending. Extensive experiments on various multi-view dynamic human datasets demonstrate the generalizability and effectiveness of our approach in synthesizing photo-realistic free-view humans under challenging motions and with very sparse camera view inputs.
iButter: Neural Interactive Bullet Time Generator for Human Free-viewpoint Rendering
Aug 12, 2021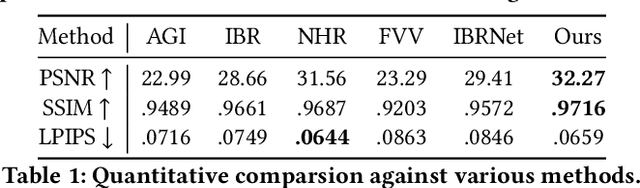
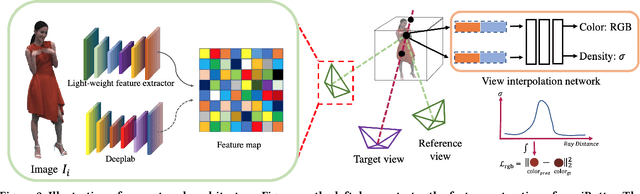
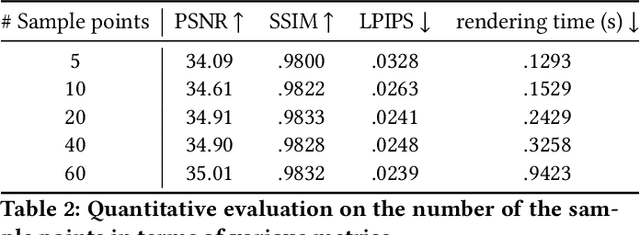
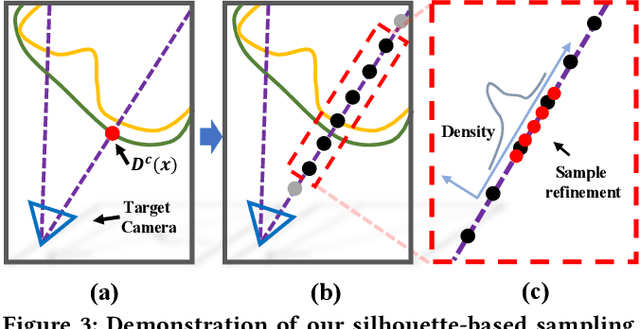
Generating ``bullet-time'' effects of human free-viewpoint videos is critical for immersive visual effects and VR/AR experience. Recent neural advances still lack the controllable and interactive bullet-time design ability for human free-viewpoint rendering, especially under the real-time, dynamic and general setting for our trajectory-aware task. To fill this gap, in this paper we propose a neural interactive bullet-time generator (iButter) for photo-realistic human free-viewpoint rendering from dense RGB streams, which enables flexible and interactive design for human bullet-time visual effects. Our iButter approach consists of a real-time preview and design stage as well as a trajectory-aware refinement stage. During preview, we propose an interactive bullet-time design approach by extending the NeRF rendering to a real-time and dynamic setting and getting rid of the tedious per-scene training. To this end, our bullet-time design stage utilizes a hybrid training set, light-weight network design and an efficient silhouette-based sampling strategy. During refinement, we introduce an efficient trajectory-aware scheme within 20 minutes, which jointly encodes the spatial, temporal consistency and semantic cues along the designed trajectory, achieving photo-realistic bullet-time viewing experience of human activities. Extensive experiments demonstrate the effectiveness of our approach for convenient interactive bullet-time design and photo-realistic human free-viewpoint video generation.
Neural Free-Viewpoint Performance Rendering under Complex Human-object Interactions
Aug 03, 2021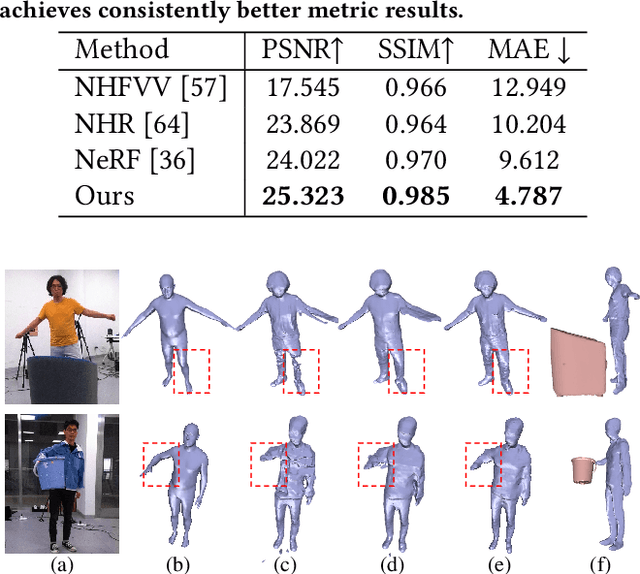
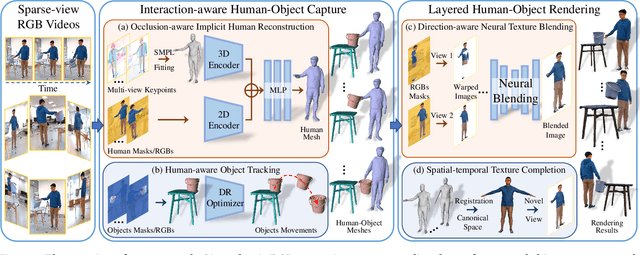
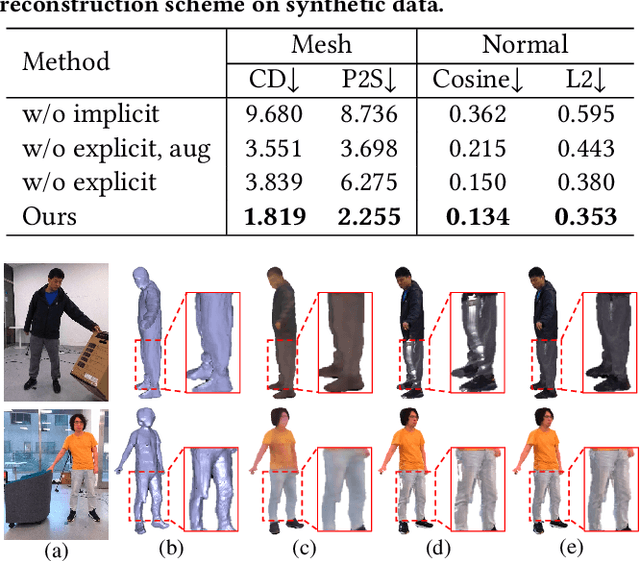

4D reconstruction of human-object interaction is critical for immersive VR/AR experience and human activity understanding. Recent advances still fail to recover fine geometry and texture results from sparse RGB inputs, especially under challenging human-object interactions scenarios. In this paper, we propose a neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of both human and objects under challenging interaction scenarios in arbitrary novel views, from only sparse RGB streams. To deal with complex occlusions raised by human-object interactions, we adopt a layer-wise scene decoupling strategy and perform volumetric reconstruction and neural rendering of the human and object. Specifically, for geometry reconstruction, we propose an interaction-aware human-object capture scheme that jointly considers the human reconstruction and object reconstruction with their correlations. Occlusion-aware human reconstruction and robust human-aware object tracking are proposed for consistent 4D human-object dynamic reconstruction. For neural texture rendering, we propose a layer-wise human-object rendering scheme, which combines direction-aware neural blending weight learning and spatial-temporal texture completion to provide high-resolution and photo-realistic texture results in the occluded scenarios. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and texture reconstruction in free viewpoints for challenging human-object interactions.
NeuralHumanFVV: Real-Time Neural Volumetric Human Performance Rendering using RGB Cameras
Mar 13, 2021

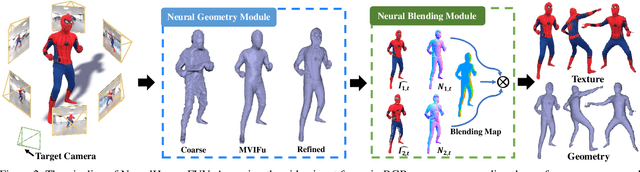
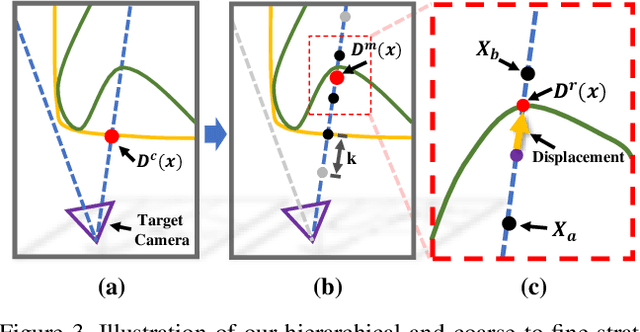
4D reconstruction and rendering of human activities is critical for immersive VR/AR experience.Recent advances still fail to recover fine geometry and texture results with the level of detail present in the input images from sparse multi-view RGB cameras. In this paper, we propose NeuralHumanFVV, a real-time neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of human activities in arbitrary novel views. We propose a neural geometry generation scheme with a hierarchical sampling strategy for real-time implicit geometry inference, as well as a novel neural blending scheme to generate high resolution (e.g., 1k) and photo-realistic texture results in the novel views. Furthermore, we adopt neural normal blending to enhance geometry details and formulate our neural geometry and texture rendering into a multi-task learning framework. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and photo-realistic free view-point reconstruction for challenging human performances.