 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerialGo: Walking-through City View Generation from Aerial Perspectives
Nov 29, 2024



High-quality 3D urban reconstruction is essential for applications in urban planning, navigation, and AR/VR. However, capturing detailed ground-level data across cities is both labor-intensive and raises significant privacy concerns related to sensitive information, such as vehicle plates, faces, and other personal identifiers. To address these challenges, we propose AerialGo, a novel framework that generates realistic walking-through city views from aerial images, leveraging multi-view diffusion models to achieve scalable, photorealistic urban reconstructions without direct ground-level data collection. By conditioning ground-view synthesis on accessible aerial data, AerialGo bypasses the privacy risks inherent in ground-level imagery. To support the model training, we introduce AerialGo dataset, a large-scale dataset containing diverse aerial and ground-view images, paired with camera and depth information, designed to support generative urban reconstruction. Experiments show that AerialGo significantly enhances ground-level realism and structural coherence, providing a privacy-conscious, scalable solution for city-scale 3D modeling.
GrainGrasp: Dexterous Grasp Generation with Fine-grained Contact Guidance
May 16, 2024



One goal of dexterous robotic grasping is to allow robots to handle objects with the same level of flexibility and adaptability as humans. However, it remains a challenging task to generate an optimal grasping strategy for dexterous hands, especially when it comes to delicate manipulation and accurate adjustment the desired grasping poses for objects of varying shapes and sizes. In this paper, we propose a novel dexterous grasp generation scheme called GrainGrasp that provides fine-grained contact guidance for each fingertip. In particular, we employ a generative model to predict separate contact maps for each fingertip on the object point cloud, effectively capturing the specifics of finger-object interactions. In addition, we develop a new dexterous grasping optimization algorithm that solely relies on the point cloud as input, eliminating the necessity for complete mesh information of the object. By leveraging the contact maps of different fingertips, the proposed optimization algorithm can generate precise and determinable strategies for human-like object grasping. Experimental results confirm the efficiency of the proposed scheme.
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Apr 15, 2024



Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
Toward Spatial Temporal Consistency of Joint Visual Tactile Perception in VR Applications
Dec 29, 2023With the development of VR technology, especially the emergence of the metaverse concept, the integration of visual and tactile perception has become an expected experience in human-machine interaction. Therefore, achieving spatial-temporal consistency of visual and tactile information in VR applications has become a necessary factor for realizing this experience. The state-of-the-art vibrotactile datasets generally contain temporal-level vibrotactile information collected by randomly sliding on the surface of an object, along with the corresponding image of the material/texture. However, they lack the position/spatial information that corresponds to the signal acquisition, making it difficult to achieve spatiotemporal alignment of visual-tactile data. Therefore, we develop a new data acquisition system in this paper which can collect visual and vibrotactile signals of different textures/materials with spatial and temporal consistency. In addition, we develop a VR-based application call "V-Touching" by leveraging the dataset generated by the new acquisition system, which can provide pixel-to-taxel joint visual-tactile perception when sliding over the surface of objects in the virtual environment with distinct vibrotactile feedback of different textures/materials.
Fast calibration for ultrasound imaging guidance based on depth camera
Aug 10, 2023During the process of robot-assisted ultrasound(US) puncture, it is important to estimate the location of the puncture from the 2D US images. To this end, the calibration of the US image becomes an important issue. In this paper, we proposed a depth camera-based US calibration method, where an easy-to-deploy device is designed for the calibration. With this device, the coordinates of the puncture needle tip are collected respectively in US image and in the depth camera, upon which a correspondence matrix is built for calibration. Finally, a number of experiments are conducted to validate the effectiveness of our calibration method.
A novel tactile palm for robotic object manipulation
Aug 10, 2023Tactile sensing is of great importance during human hand usage such as object exploration, grasping and manipulation. Different types of tactile sensors have been designed during the past decades, which are mainly focused on either the fingertips for grasping or the upper-body for human-robot interaction. In this paper, a novel soft tactile sensor has been designed to mimic the functionality of human palm that can estimate the contact state of different objects. The tactile palm mainly consists of three parts including an electrode array, a soft cover skin and the conductive sponge. The design principle are described in details, with a number of experiments showcasing the effectiveness of the proposed design.
NEPHELE: A Neural Platform for Highly Realistic Cloud Radiance Rendering
Mar 07, 2023We have recently seen tremendous progress in neural rendering (NR) advances, i.e., NeRF, for photo-real free-view synthesis. Yet, as a local technique based on a single computer/GPU, even the best-engineered Instant-NGP or i-NGP cannot reach real-time performance when rendering at a high resolution, and often requires huge local computing resources. In this paper, we resort to cloud rendering and present NEPHELE, a neural platform for highly realistic cloud radiance rendering. In stark contrast with existing NR approaches, our NEPHELE allows for more powerful rendering capabilities by combining multiple remote GPUs and facilitates collaboration by allowing multiple people to view the same NeRF scene simultaneously. We introduce i-NOLF to employ opacity light fields for ultra-fast neural radiance rendering in a one-query-per-ray manner. We further resemble the Lumigraph with geometry proxies for fast ray querying and subsequently employ a small MLP to model the local opacity lumishperes for high-quality rendering. We also adopt Perfect Spatial Hashing in i-NOLF to enhance cache coherence. As a result, our i-NOLF achieves an order of magnitude performance gain in terms of efficiency than i-NGP, especially for the multi-user multi-viewpoint setting under cloud rendering scenarios. We further tailor a task scheduler accompanied by our i-NOLF representation and demonstrate the advance of our methodological design through a comprehensive cloud platform, consisting of a series of cooperated modules, i.e., render farms, task assigner, frame composer, and detailed streaming strategies. Using such a cloud platform compatible with neural rendering, we further showcase the capabilities of our cloud radiance rendering through a series of applications, ranging from cloud VR/AR rendering.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

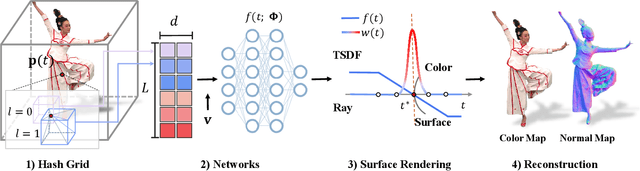
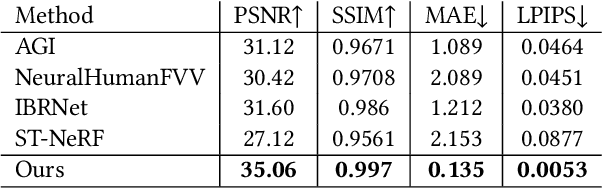
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
Real-time Scene Text Detection Based on Global Level and Word Level Features
Mar 10, 2022
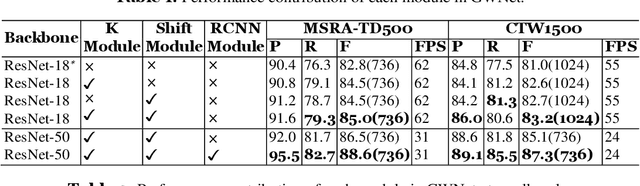
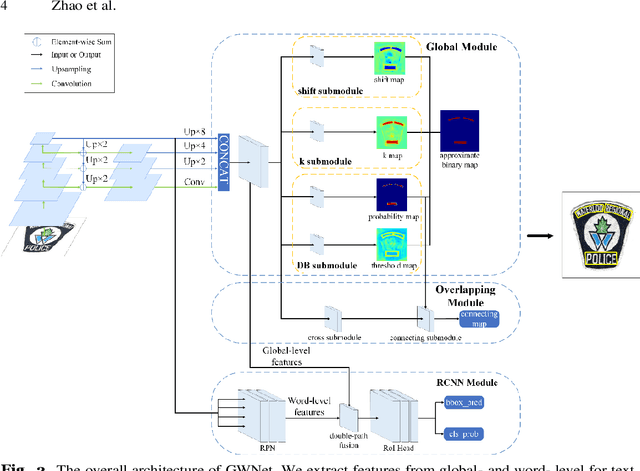
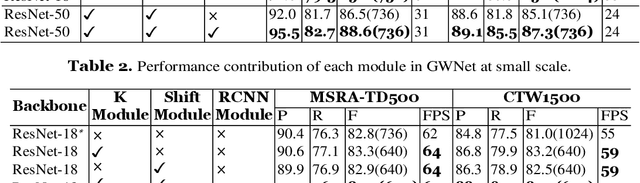
It is an extremely challenging task to detect arbitrary shape text in natural scenes on high accuracy and efficiency. In this paper, we propose a scene text detection framework, namely GWNet, which mainly includes two modules: Global module and RCNN module. Specifically, Global module improves the adaptive performance of the DB (Differentiable Binarization) module by adding k submodule and shift submodule. Two submodules enhance the adaptability of amplifying factor k, accelerate the convergence of models and help to produce more accurate detection results. RCNN module fuses global-level and word-level features. The word-level label is generated by obtaining the minimum axis-aligned rectangle boxes of the shrunk polygon. In the inference period, GWNet only uses global-level features to output simple polygon detections. Experiments on four benchmark datasets, including the MSRA-TD500, Total-Text, ICDAR2015 and CTW-1500, demonstrate that our GWNet outperforms the state-of-the-art detectors. Specifically, with a backbone of ResNet-50, we achieve an F-measure of 88.6% on MSRA- TD500, 87.9% on Total-Text, 89.2% on ICDAR2015 and 87.5% on CTW-1500.
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time
Feb 22, 2022
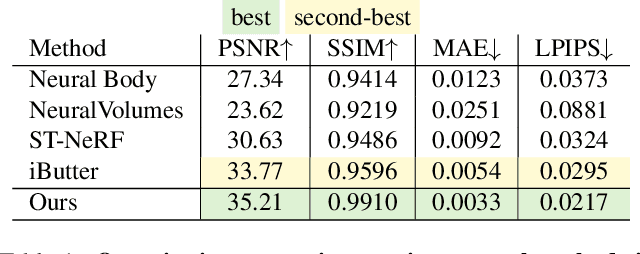
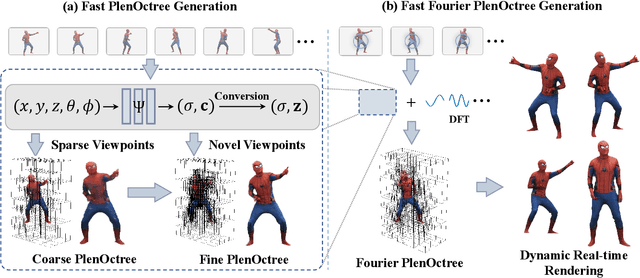

Implicit neural representations such as Neural Radiance Field (NeRF) have focused mainly on modeling static objects captured under multi-view settings where real-time rendering can be achieved with smart data structures, e.g., PlenOctree. In this paper, we present a novel Fourier PlenOctree (FPO) technique to tackle efficient neural modeling and real-time rendering of dynamic scenes captured under the free-view video (FVV) setting. The key idea in our FPO is a novel combination of generalized NeRF, PlenOctree representation, volumetric fusion and Fourier transform. To accelerate FPO construction, we present a novel coarse-to-fine fusion scheme that leverages the generalizable NeRF technique to generate the tree via spatial blending. To tackle dynamic scenes, we tailor the implicit network to model the Fourier coefficients of timevarying density and color attributes. Finally, we construct the FPO and train the Fourier coefficients directly on the leaves of a union PlenOctree structure of the dynamic sequence. We show that the resulting FPO enables compact memory overload to handle dynamic objects and supports efficient fine-tuning. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF and achieves over an order of magnitude acceleration over SOTA while preserving high visual quality for the free-viewpoint rendering of unseen dynamic scenes.