 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDen-1K: A Density Field Dataset of Real-World Objects
Dec 11, 2025A deep understanding of the physical world is a central goal for embodied AI and realistic simulation. While current models excel at capturing an object's surface geometry and appearance, they largely neglect its internal physical properties. This omission is critical, as properties like volumetric density are fundamental for predicting an object's center of mass, stability, and interaction dynamics in applications ranging from robotic manipulation to physical simulation. The primary bottleneck has been the absence of large-scale, real-world data. To bridge this gap, we introduce XDen-1K, the first large-scale, multi-modal dataset designed for real-world physical property estimation, with a particular focus on volumetric density. The core of this dataset consists of 1,000 real-world objects across 148 categories, for which we provide comprehensive multi-modal data, including a high-resolution 3D geometric model with part-level annotations and a corresponding set of real-world biplanar X-ray scans. Building upon this data, we introduce a novel optimization framework that recovers a high-fidelity volumetric density field of each object from its sparse X-ray views. To demonstrate its practical value, we add X-ray images as a conditioning signal to an existing segmentation network and perform volumetric segmentation. Furthermore, we conduct experiments on downstream robotics tasks. The results show that leveraging the dataset can effectively improve the accuracy of center-of-mass estimation and the success rate of robotic manipulation. We believe XDen-1K will serve as a foundational resource and a challenging new benchmark, catalyzing future research in physically grounded visual inference and embodied AI.
BG-Triangle: Bézier Gaussian Triangle for 3D Vectorization and Rendering
Mar 18, 2025Differentiable rendering enables efficient optimization by allowing gradients to be computed through the rendering process, facilitating 3D reconstruction, inverse rendering and neural scene representation learning. To ensure differentiability, existing solutions approximate or re-formulate traditional rendering operations using smooth, probabilistic proxies such as volumes or Gaussian primitives. Consequently, they struggle to preserve sharp edges due to the lack of explicit boundary definitions. We present a novel hybrid representation, B\'ezier Gaussian Triangle (BG-Triangle), that combines B\'ezier triangle-based vector graphics primitives with Gaussian-based probabilistic models, to maintain accurate shape modeling while conducting resolution-independent differentiable rendering. We present a robust and effective discontinuity-aware rendering technique to reduce uncertainties at object boundaries. We also employ an adaptive densification and pruning scheme for efficient training while reliably handling level-of-detail (LoD) variations. Experiments show that BG-Triangle achieves comparable rendering quality as 3DGS but with superior boundary preservation. More importantly, BG-Triangle uses a much smaller number of primitives than its alternatives, showcasing the benefits of vectorized graphics primitives and the potential to bridge the gap between classic and emerging representations.
CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image
Feb 18, 2025Recovering high-quality 3D scenes from a single RGB image is a challenging task in computer graphics. Current methods often struggle with domain-specific limitations or low-quality object generation. To address these, we propose CAST (Component-Aligned 3D Scene Reconstruction from a Single RGB Image), a novel method for 3D scene reconstruction and recovery. CAST starts by extracting object-level 2D segmentation and relative depth information from the input image, followed by using a GPT-based model to analyze inter-object spatial relationships. This enables the understanding of how objects relate to each other within the scene, ensuring more coherent reconstruction. CAST then employs an occlusion-aware large-scale 3D generation model to independently generate each object's full geometry, using MAE and point cloud conditioning to mitigate the effects of occlusions and partial object information, ensuring accurate alignment with the source image's geometry and texture. To align each object with the scene, the alignment generation model computes the necessary transformations, allowing the generated meshes to be accurately placed and integrated into the scene's point cloud. Finally, CAST incorporates a physics-aware correction step that leverages a fine-grained relation graph to generate a constraint graph. This graph guides the optimization of object poses, ensuring physical consistency and spatial coherence. By utilizing Signed Distance Fields (SDF), the model effectively addresses issues such as occlusions, object penetration, and floating objects, ensuring that the generated scene accurately reflects real-world physical interactions. CAST can be leveraged in robotics, enabling efficient real-to-simulation workflows and providing realistic, scalable simulation environments for robotic systems.
DressCode: Autoregressively Sewing and Generating Garments from Text Guidance
Jan 29, 2024Apparel's significant role in human appearance underscores the importance of garment digitalization for digital human creation. Recent advances in 3D content creation are pivotal for digital human creation. Nonetheless, garment generation from text guidance is still nascent. We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-on, and digital human creation. For our framework, we first introduce SewingGPT, a GPT-based architecture integrating cross-attention with text-conditioned embedding to generate sewing patterns with text guidance. We also tailored a pre-trained Stable Diffusion for high-quality, tile-based PBR texture generation. By leveraging a large language model, our framework generates CG-friendly garments through natural language interaction. Our method also facilitates pattern completion and texture editing, simplifying the process for designers by user-friendly interaction. With comprehensive evaluations and comparisons with other state-of-the-art methods, our method showcases the best quality and alignment with input prompts. User studies further validate our high-quality rendering results, highlighting its practical utility and potential in production settings.
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Dec 03, 2023



Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.
Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions from Monocular RGBD Stream
Apr 06, 2023Convenient 4D modeling of human-object interactions is essential for numerous applications. However, monocular tracking and rendering of complex interaction scenarios remain challenging. In this paper, we propose Instant-NVR, a neural approach for instant volumetric human-object tracking and rendering using a single RGBD camera. It bridges traditional non-rigid tracking with recent instant radiance field techniques via a multi-thread tracking-rendering mechanism. In the tracking front-end, we adopt a robust human-object capture scheme to provide sufficient motion priors. We further introduce a separated instant neural representation with a novel hybrid deformation module for the interacting scene. We also provide an on-the-fly reconstruction scheme of the dynamic/static radiance fields via efficient motion-prior searching. Moreover, we introduce an online key frame selection scheme and a rendering-aware refinement strategy to significantly improve the appearance details for online novel-view synthesis. Extensive experiments demonstrate the effectiveness and efficiency of our approach for the instant generation of human-object radiance fields on the fly, notably achieving real-time photo-realistic novel view synthesis under complex human-object interactions.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

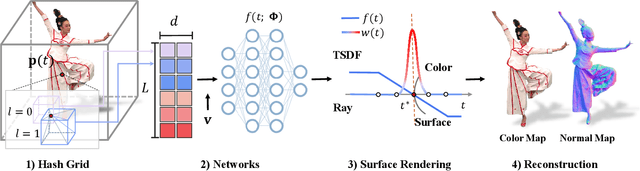
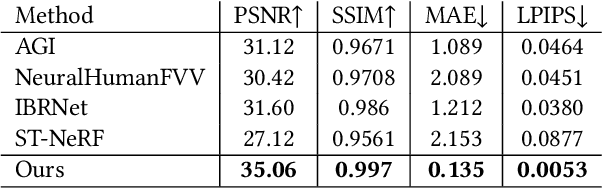
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.