 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance
Mar 15, 2025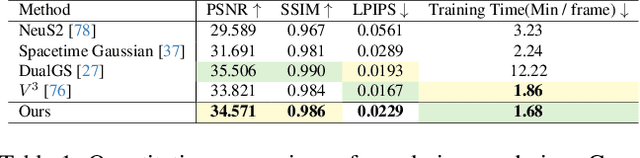
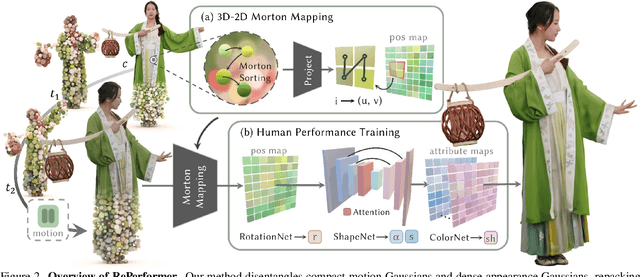
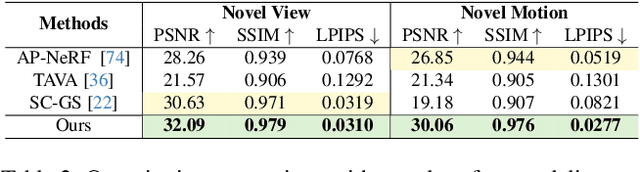
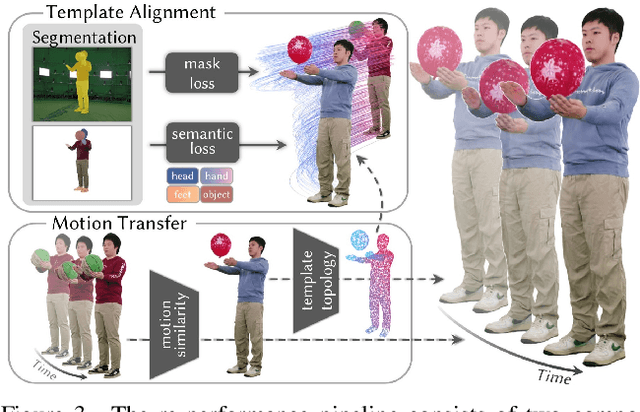
Human-centric volumetric videos offer immersive free-viewpoint experiences, yet existing methods focus either on replaying general dynamic scenes or animating human avatars, limiting their ability to re-perform general dynamic scenes. In this paper, we present RePerformer, a novel Gaussian-based representation that unifies playback and re-performance for high-fidelity human-centric volumetric videos. Specifically, we hierarchically disentangle the dynamic scenes into motion Gaussians and appearance Gaussians which are associated in the canonical space. We further employ a Morton-based parameterization to efficiently encode the appearance Gaussians into 2D position and attribute maps. For enhanced generalization, we adopt 2D CNNs to map position maps to attribute maps, which can be assembled into appearance Gaussians for high-fidelity rendering of the dynamic scenes. For re-performance, we develop a semantic-aware alignment module and apply deformation transfer on motion Gaussians, enabling photo-real rendering under novel motions. Extensive experiments validate the robustness and effectiveness of RePerformer, setting a new benchmark for playback-then-reperformance paradigm in human-centric volumetric videos.
BEAM: Bridging Physically-based Rendering and Gaussian Modeling for Relightable Volumetric Video
Feb 12, 2025Volumetric video enables immersive experiences by capturing dynamic 3D scenes, enabling diverse applications for virtual reality, education, and telepresence. However, traditional methods struggle with fixed lighting conditions, while neural approaches face trade-offs in efficiency, quality, or adaptability for relightable scenarios. To address these limitations, we present BEAM, a novel pipeline that bridges 4D Gaussian representations with physically-based rendering (PBR) to produce high-quality, relightable volumetric videos from multi-view RGB footage. BEAM recovers detailed geometry and PBR properties via a series of available Gaussian-based techniques. It first combines Gaussian-based performance tracking with geometry-aware rasterization in a coarse-to-fine optimization framework to recover spatially and temporally consistent geometries. We further enhance Gaussian attributes by incorporating PBR properties step by step. We generate roughness via a multi-view-conditioned diffusion model, and then derive AO and base color using a 2D-to-3D strategy, incorporating a tailored Gaussian-based ray tracer for efficient visibility computation. Once recovered, these dynamic, relightable assets integrate seamlessly into traditional CG pipelines, supporting real-time rendering with deferred shading and offline rendering with ray tracing. By offering realistic, lifelike visualizations under diverse lighting conditions, BEAM opens new possibilities for interactive entertainment, storytelling, and creative visualization.
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
Sep 12, 2024Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.
HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
Dec 07, 2023



We have recently seen tremendous progress in photo-real human modeling and rendering. Yet, efficiently rendering realistic human performance and integrating it into the rasterization pipeline remains challenging. In this paper, we present HiFi4G, an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage. Our core intuition is to marry the 3D Gaussian representation with non-rigid tracking, achieving a compact and compression-friendly representation. We first propose a dual-graph mechanism to obtain motion priors, with a coarse deformation graph for effective initialization and a fine-grained Gaussian graph to enforce subsequent constraints. Then, we utilize a 4D Gaussian optimization scheme with adaptive spatial-temporal regularizers to effectively balance the non-rigid prior and Gaussian updating. We also present a companion compression scheme with residual compensation for immersive experiences on various platforms. It achieves a substantial compression rate of approximately 25 times, with less than 2MB of storage per frame. Extensive experiments demonstrate the effectiveness of our approach, which significantly outperforms existing approaches in terms of optimization speed, rendering quality, and storage overhead.
Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions from Monocular RGBD Stream
Apr 06, 2023Convenient 4D modeling of human-object interactions is essential for numerous applications. However, monocular tracking and rendering of complex interaction scenarios remain challenging. In this paper, we propose Instant-NVR, a neural approach for instant volumetric human-object tracking and rendering using a single RGBD camera. It bridges traditional non-rigid tracking with recent instant radiance field techniques via a multi-thread tracking-rendering mechanism. In the tracking front-end, we adopt a robust human-object capture scheme to provide sufficient motion priors. We further introduce a separated instant neural representation with a novel hybrid deformation module for the interacting scene. We also provide an on-the-fly reconstruction scheme of the dynamic/static radiance fields via efficient motion-prior searching. Moreover, we introduce an online key frame selection scheme and a rendering-aware refinement strategy to significantly improve the appearance details for online novel-view synthesis. Extensive experiments demonstrate the effectiveness and efficiency of our approach for the instant generation of human-object radiance fields on the fly, notably achieving real-time photo-realistic novel view synthesis under complex human-object interactions.