 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLASS: A Generative Recommender for Long-sequence Modeling via SID-Tier and Semantic Search
Feb 05, 2026Leveraging long-term user behavioral patterns is a key trajectory for enhancing the accuracy of modern recommender systems. While generative recommender systems have emerged as a transformative paradigm, they face hurdles in effectively modeling extensive historical sequences. To address this challenge, we propose GLASS, a novel framework that integrates long-term user interests into the generative process via SID-Tier and Semantic Search. We first introduce SID-Tier, a module that maps long-term interactions into a unified interest vector to enhance the prediction of the initial SID token. Unlike traditional retrieval models that struggle with massive item spaces, SID-Tier leverages the compact nature of the semantic codebook to incorporate cross features between the user's long-term history and candidate semantic codes. Furthermore, we present semantic hard search, which utilizes generated coarse-grained semantic ID as dynamic keys to extract relevant historical behaviors, which are then fused via an adaptive gated fusion module to recalibrate the trajectory of subsequent fine-grained tokens. To address the inherent data sparsity in semantic hard search, we propose two strategies: semantic neighbor augmentation and codebook resizing. Extensive experiments on two large-scale real-world datasets, TAOBAO-MM and KuaiRec, demonstrate that GLASS outperforms state-of-the-art baselines, achieving significant gains in recommendation quality. Our codes are made publicly available to facilitate further research in generative recommendation.
PROMISE: Process Reward Models Unlock Test-Time Scaling Laws in Generative Recommendations
Jan 08, 2026Generative Recommendation has emerged as a promising paradigm, reformulating recommendation as a sequence-to-sequence generation task over hierarchical Semantic IDs. However, existing methods suffer from a critical issue we term Semantic Drift, where errors in early, high-level tokens irreversibly divert the generation trajectory into irrelevant semantic subspaces. Inspired by Process Reward Models (PRMs) that enhance reasoning in Large Language Models, we propose Promise, a novel framework that integrates dense, step-by-step verification into generative models. Promise features a lightweight PRM to assess the quality of intermediate inference steps, coupled with a PRM-guided Beam Search strategy that leverages dense feedback to dynamically prune erroneous branches. Crucially, our approach unlocks Test-Time Scaling Laws for recommender systems: by increasing inference compute, smaller models can match or surpass larger models. Extensive offline experiments and online A/B tests on a large-scale platform demonstrate that Promise effectively mitigates Semantic Drift, significantly improving recommendation accuracy while enabling efficient deployment.
MISS: Multi-Modal Tree Indexing and Searching with Lifelong Sequential Behavior for Retrieval Recommendation
Aug 20, 2025



Large-scale industrial recommendation systems typically employ a two-stage paradigm of retrieval and ranking to handle huge amounts of information. Recent research focuses on improving the performance of retrieval model. A promising way is to introduce extensive information about users and items. On one hand, lifelong sequential behavior is valuable. Existing lifelong behavior modeling methods in ranking stage focus on the interaction of lifelong behavior and candidate items from retrieval stage. In retrieval stage, it is difficult to utilize lifelong behavior because of a large corpus of candidate items. On the other hand, existing retrieval methods mostly relay on interaction information, potentially disregarding valuable multi-modal information. To solve these problems, we represent the pioneering exploration of leveraging multi-modal information and lifelong sequence model within the advanced tree-based retrieval model. We propose Multi-modal Indexing and Searching with lifelong Sequence (MISS), which contains a multi-modal index tree and a multi-modal lifelong sequence modeling module. Specifically, for better index structure, we propose multi-modal index tree, which is built using the multi-modal embedding to precisely represent item similarity. To precisely capture diverse user interests in user lifelong sequence, we propose collaborative general search unit (Co-GSU) and multi-modal general search unit (MM-GSU) for multi-perspective interests searching.
RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance
Mar 15, 2025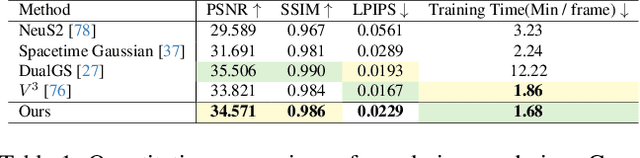
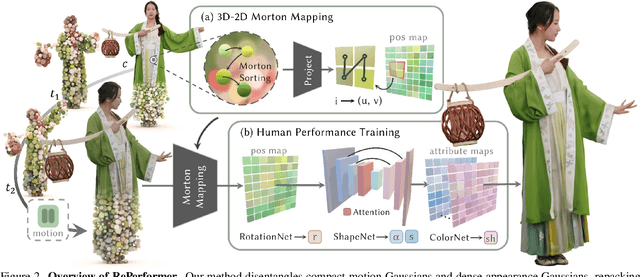
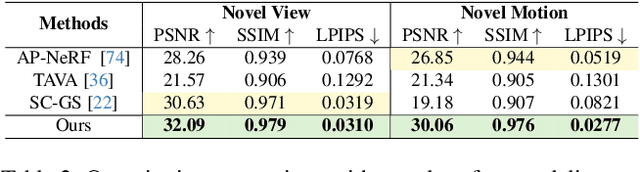
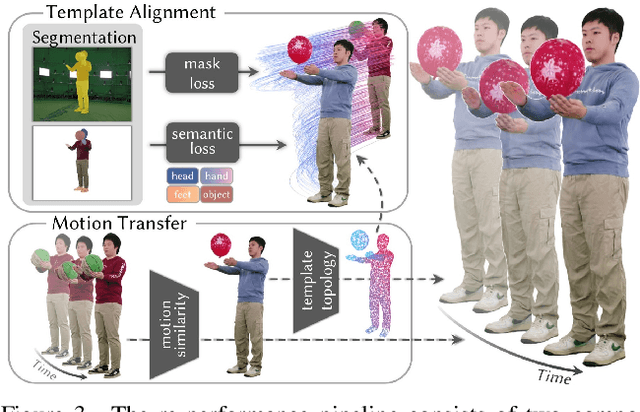
Human-centric volumetric videos offer immersive free-viewpoint experiences, yet existing methods focus either on replaying general dynamic scenes or animating human avatars, limiting their ability to re-perform general dynamic scenes. In this paper, we present RePerformer, a novel Gaussian-based representation that unifies playback and re-performance for high-fidelity human-centric volumetric videos. Specifically, we hierarchically disentangle the dynamic scenes into motion Gaussians and appearance Gaussians which are associated in the canonical space. We further employ a Morton-based parameterization to efficiently encode the appearance Gaussians into 2D position and attribute maps. For enhanced generalization, we adopt 2D CNNs to map position maps to attribute maps, which can be assembled into appearance Gaussians for high-fidelity rendering of the dynamic scenes. For re-performance, we develop a semantic-aware alignment module and apply deformation transfer on motion Gaussians, enabling photo-real rendering under novel motions. Extensive experiments validate the robustness and effectiveness of RePerformer, setting a new benchmark for playback-then-reperformance paradigm in human-centric volumetric videos.
BEAM: Bridging Physically-based Rendering and Gaussian Modeling for Relightable Volumetric Video
Feb 12, 2025Volumetric video enables immersive experiences by capturing dynamic 3D scenes, enabling diverse applications for virtual reality, education, and telepresence. However, traditional methods struggle with fixed lighting conditions, while neural approaches face trade-offs in efficiency, quality, or adaptability for relightable scenarios. To address these limitations, we present BEAM, a novel pipeline that bridges 4D Gaussian representations with physically-based rendering (PBR) to produce high-quality, relightable volumetric videos from multi-view RGB footage. BEAM recovers detailed geometry and PBR properties via a series of available Gaussian-based techniques. It first combines Gaussian-based performance tracking with geometry-aware rasterization in a coarse-to-fine optimization framework to recover spatially and temporally consistent geometries. We further enhance Gaussian attributes by incorporating PBR properties step by step. We generate roughness via a multi-view-conditioned diffusion model, and then derive AO and base color using a 2D-to-3D strategy, incorporating a tailored Gaussian-based ray tracer for efficient visibility computation. Once recovered, these dynamic, relightable assets integrate seamlessly into traditional CG pipelines, supporting real-time rendering with deferred shading and offline rendering with ray tracing. By offering realistic, lifelike visualizations under diverse lighting conditions, BEAM opens new possibilities for interactive entertainment, storytelling, and creative visualization.
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
Sep 12, 2024Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Dec 03, 2023



Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.
DeepCore: A Comprehensive Library for Coreset Selection in Deep Learning
Apr 18, 2022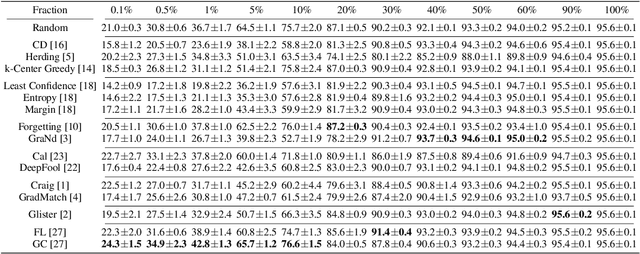
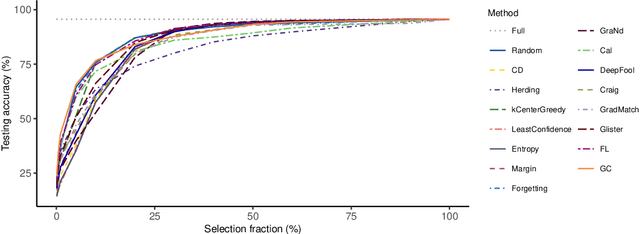
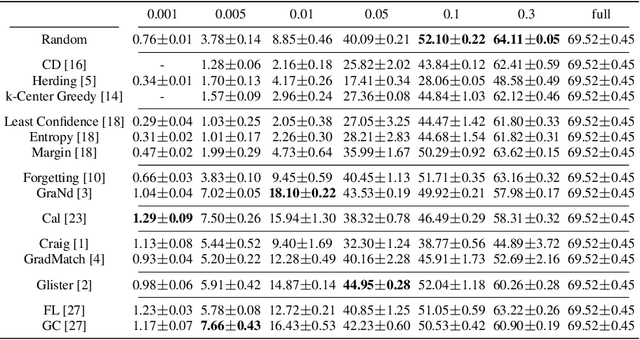
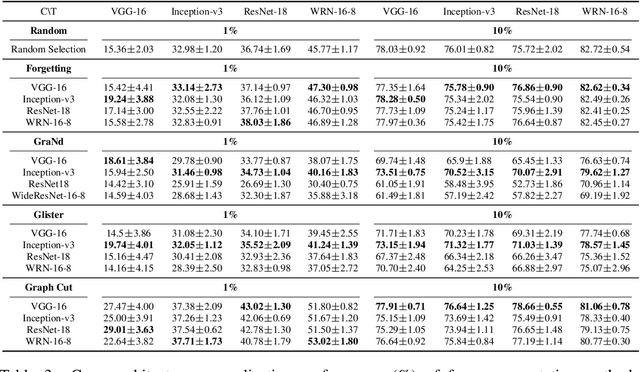
Coreset selection, which aims to select a subset of the most informative training samples, is a long-standing learning problem that can benefit many downstream tasks such as data-efficient learning, continual learning, neural architecture search, active learning, etc. However, many existing coreset selection methods are not designed for deep learning, which may have high complexity and poor generalization ability to unseen representations. In addition, the recently proposed methods are evaluated on models, datasets, and settings of different complexities. To advance the research of coreset selection in deep learning, we contribute a comprehensive code library, namely DeepCore, and provide an empirical study on popular coreset selection methods on CIFAR10 and ImageNet datasets. Extensive experiment results show that, although some methods perform better in certain experiment settings, random selection is still a strong baseline.
Coarse-to-fine Semantic Localization with HD Map for Autonomous Driving in Structural Scenes
Jul 06, 2021

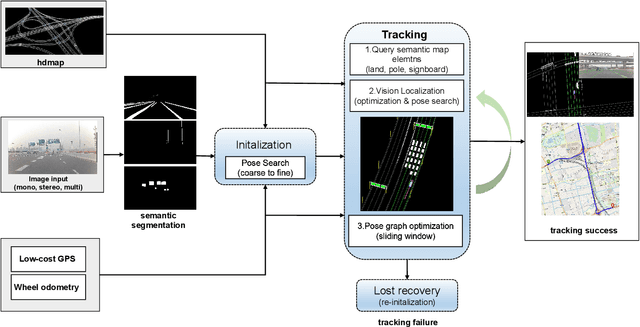

Robust and accurate localization is an essential component for robotic navigation and autonomous driving. The use of cameras for localization with high definition map (HD Map) provides an affordable localization sensor set. Existing methods suffer from pose estimation failure due to error prone data association or initialization with accurate initial pose requirement. In this paper, we propose a cost-effective vehicle localization system with HD map for autonomous driving that uses cameras as primary sensors. To this end, we formulate vision-based localization as a data association problem that maps visual semantics to landmarks in HD map. Specifically, system initialization is finished in a coarse to fine manner by combining coarse GPS (Global Positioning System) measurement and fine pose searching. In tracking stage, vehicle pose is refined by implicitly aligning the semantic segmentation result between image and landmarks in HD maps with photometric consistency. Finally, vehicle pose is computed by pose graph optimization in a sliding window fashion. We evaluate our method on two datasets and demonstrate that the proposed approach yields promising localization results in different driving scenarios. Additionally, our approach is suitable for both monocular camera and multi-cameras that provides flexibility and improves robustness for the localization system.