 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoVGGT: Feed-Forward 3D Reconstruction from Panoramic Imagery
Mar 18, 2026Panoramic imagery offers a full 360° field of view and is increasingly common in consumer devices. However, it introduces non-pinhole distortions that challenge joint pose estimation and 3D reconstruction. Existing feed-forward models, built for perspective cameras, generalize poorly to this setting. We propose PanoVGGT, a permutation-equivariant Transformer framework that jointly predicts camera poses, depth maps, and 3D point clouds from one or multiple panoramas in a single forward pass. The model incorporates spherical-aware positional embeddings and a panorama-specific three-axis SO(3) rotation augmentation, enabling effective geometric reasoning in the spherical domain. To resolve inherent global-frame ambiguity, we further introduce a stochastic anchoring strategy during training. In addition, we contribute PanoCity, a large-scale outdoor panoramic dataset with dense depth and 6-DoF pose annotations. Extensive experiments on PanoCity and standard benchmarks demonstrate that PanoVGGT achieves competitive accuracy, strong robustness, and improved cross-domain generalization. Code and dataset will be released.
CityGo: Lightweight Urban Modeling and Rendering with Proxy Buildings and Residual Gaussians
May 28, 2025



Accurate and efficient modeling of large-scale urban scenes is critical for applications such as AR navigation, UAV based inspection, and smart city digital twins. While aerial imagery offers broad coverage and complements limitations of ground-based data, reconstructing city-scale environments from such views remains challenging due to occlusions, incomplete geometry, and high memory demands. Recent advances like 3D Gaussian Splatting (3DGS) improve scalability and visual quality but remain limited by dense primitive usage, long training times, and poor suit ability for edge devices. We propose CityGo, a hybrid framework that combines textured proxy geometry with residual and surrounding 3D Gaussians for lightweight, photorealistic rendering of urban scenes from aerial perspectives. Our approach first extracts compact building proxy meshes from MVS point clouds, then uses zero order SH Gaussians to generate occlusion-free textures via image-based rendering and back-projection. To capture high-frequency details, we introduce residual Gaussians placed based on proxy-photo discrepancies and guided by depth priors. Broader urban context is represented by surrounding Gaussians, with importance-aware downsampling applied to non-critical regions to reduce redundancy. A tailored optimization strategy jointly refines proxy textures and Gaussian parameters, enabling real-time rendering of complex urban scenes on mobile GPUs with significantly reduced training and memory requirements. Extensive experiments on real-world aerial datasets demonstrate that our hybrid representation significantly reduces training time, achieving on average 1.4x speedup, while delivering comparable visual fidelity to pure 3D Gaussian Splatting approaches. Furthermore, CityGo enables real-time rendering of large-scale urban scenes on mobile consumer GPUs, with substantially reduced memory usage and energy consumption.
RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance
Mar 15, 2025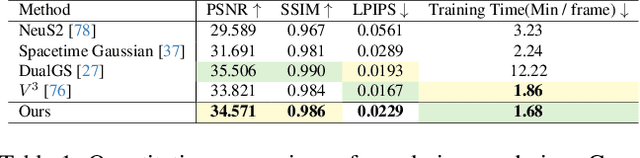
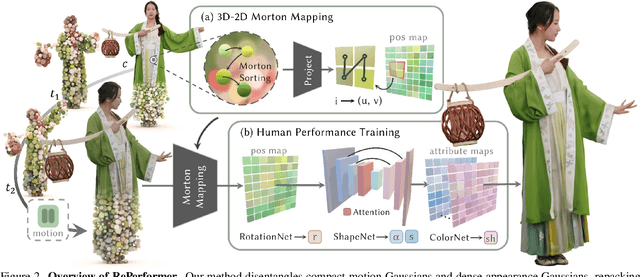
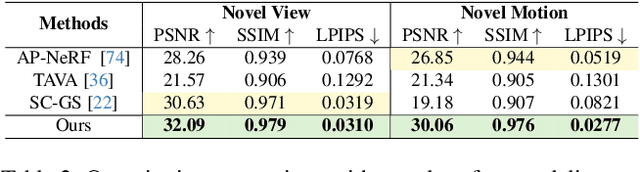
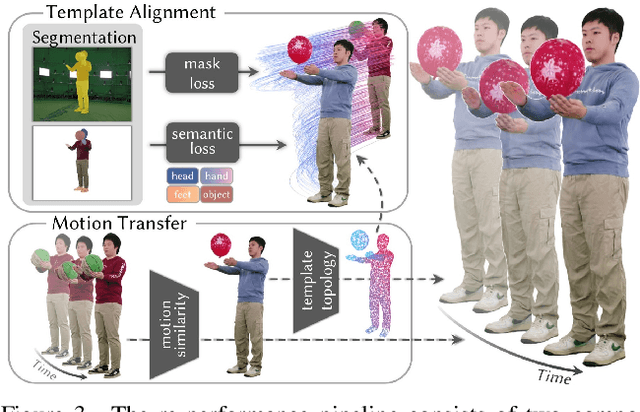
Human-centric volumetric videos offer immersive free-viewpoint experiences, yet existing methods focus either on replaying general dynamic scenes or animating human avatars, limiting their ability to re-perform general dynamic scenes. In this paper, we present RePerformer, a novel Gaussian-based representation that unifies playback and re-performance for high-fidelity human-centric volumetric videos. Specifically, we hierarchically disentangle the dynamic scenes into motion Gaussians and appearance Gaussians which are associated in the canonical space. We further employ a Morton-based parameterization to efficiently encode the appearance Gaussians into 2D position and attribute maps. For enhanced generalization, we adopt 2D CNNs to map position maps to attribute maps, which can be assembled into appearance Gaussians for high-fidelity rendering of the dynamic scenes. For re-performance, we develop a semantic-aware alignment module and apply deformation transfer on motion Gaussians, enabling photo-real rendering under novel motions. Extensive experiments validate the robustness and effectiveness of RePerformer, setting a new benchmark for playback-then-reperformance paradigm in human-centric volumetric videos.
BEAM: Bridging Physically-based Rendering and Gaussian Modeling for Relightable Volumetric Video
Feb 12, 2025Volumetric video enables immersive experiences by capturing dynamic 3D scenes, enabling diverse applications for virtual reality, education, and telepresence. However, traditional methods struggle with fixed lighting conditions, while neural approaches face trade-offs in efficiency, quality, or adaptability for relightable scenarios. To address these limitations, we present BEAM, a novel pipeline that bridges 4D Gaussian representations with physically-based rendering (PBR) to produce high-quality, relightable volumetric videos from multi-view RGB footage. BEAM recovers detailed geometry and PBR properties via a series of available Gaussian-based techniques. It first combines Gaussian-based performance tracking with geometry-aware rasterization in a coarse-to-fine optimization framework to recover spatially and temporally consistent geometries. We further enhance Gaussian attributes by incorporating PBR properties step by step. We generate roughness via a multi-view-conditioned diffusion model, and then derive AO and base color using a 2D-to-3D strategy, incorporating a tailored Gaussian-based ray tracer for efficient visibility computation. Once recovered, these dynamic, relightable assets integrate seamlessly into traditional CG pipelines, supporting real-time rendering with deferred shading and offline rendering with ray tracing. By offering realistic, lifelike visualizations under diverse lighting conditions, BEAM opens new possibilities for interactive entertainment, storytelling, and creative visualization.
CADSpotting: Robust Panoptic Symbol Spotting on Large-Scale CAD Drawings
Dec 10, 2024We introduce CADSpotting, an efficient method for panoptic symbol spotting in large-scale architectural CAD drawings. Existing approaches struggle with the diversity of symbols, scale variations, and overlapping elements in CAD designs. CADSpotting overcomes these challenges by representing each primitive with dense points instead of a single primitive point, described by essential attributes like coordinates and color. Building upon a unified 3D point cloud model for joint semantic, instance, and panoptic segmentation, CADSpotting learns robust feature representations. To enable accurate segmentation in large, complex drawings, we further propose a novel Sliding Window Aggregation (SWA) technique, combining weighted voting and Non-Maximum Suppression (NMS). Moreover, we introduce a large-scale CAD dataset named LS-CAD to support our experiments. Each floorplan in LS-CAD has an average coverage of 1,000 square meter(versus 100 square meter in the existing dataset), providing a valuable benchmark for symbol spotting research. Experimental results on FloorPlanCAD and LS-CAD datasets demonstrate that CADSpotting outperforms existing methods, showcasing its robustness and scalability for real-world CAD applications.
AerialGo: Walking-through City View Generation from Aerial Perspectives
Nov 29, 2024



High-quality 3D urban reconstruction is essential for applications in urban planning, navigation, and AR/VR. However, capturing detailed ground-level data across cities is both labor-intensive and raises significant privacy concerns related to sensitive information, such as vehicle plates, faces, and other personal identifiers. To address these challenges, we propose AerialGo, a novel framework that generates realistic walking-through city views from aerial images, leveraging multi-view diffusion models to achieve scalable, photorealistic urban reconstructions without direct ground-level data collection. By conditioning ground-view synthesis on accessible aerial data, AerialGo bypasses the privacy risks inherent in ground-level imagery. To support the model training, we introduce AerialGo dataset, a large-scale dataset containing diverse aerial and ground-view images, paired with camera and depth information, designed to support generative urban reconstruction. Experiments show that AerialGo significantly enhances ground-level realism and structural coherence, providing a privacy-conscious, scalable solution for city-scale 3D modeling.
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
Sep 12, 2024Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Apr 15, 2024



Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
Jan 30, 2024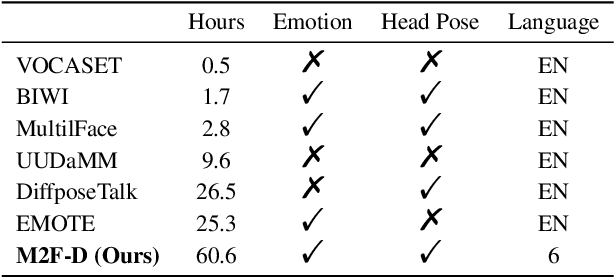
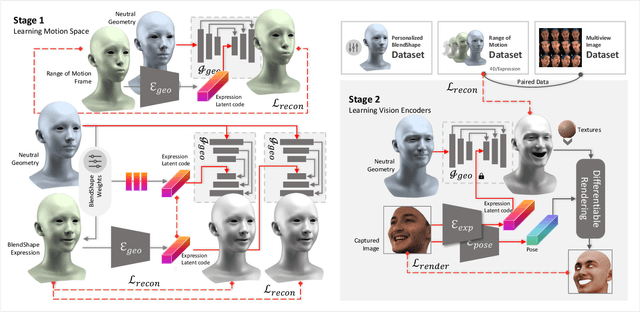

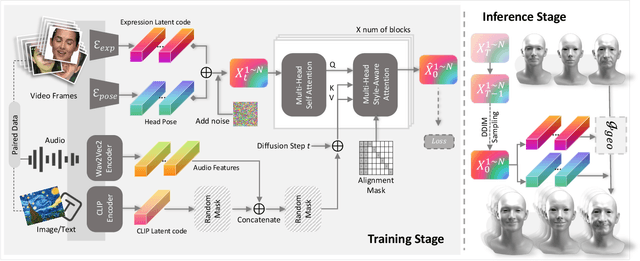
The synthesis of 3D facial animations from speech has garnered considerable attention. Due to the scarcity of high-quality 4D facial data and well-annotated abundant multi-modality labels, previous methods often suffer from limited realism and a lack of lexible conditioning. We address this challenge through a trilogy. We first introduce Generalized Neural Parametric Facial Asset (GNPFA), an efficient variational auto-encoder mapping facial geometry and images to a highly generalized expression latent space, decoupling expressions and identities. Then, we utilize GNPFA to extract high-quality expressions and accurate head poses from a large array of videos. This presents the M2F-D dataset, a large, diverse, and scan-level co-speech 3D facial animation dataset with well-annotated emotional and style labels. Finally, we propose Media2Face, a diffusion model in GNPFA latent space for co-speech facial animation generation, accepting rich multi-modality guidances from audio, text, and image. Extensive experiments demonstrate that our model not only achieves high fidelity in facial animation synthesis but also broadens the scope of expressiveness and style adaptability in 3D facial animation.
HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
Dec 07, 2023



We have recently seen tremendous progress in photo-real human modeling and rendering. Yet, efficiently rendering realistic human performance and integrating it into the rasterization pipeline remains challenging. In this paper, we present HiFi4G, an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage. Our core intuition is to marry the 3D Gaussian representation with non-rigid tracking, achieving a compact and compression-friendly representation. We first propose a dual-graph mechanism to obtain motion priors, with a coarse deformation graph for effective initialization and a fine-grained Gaussian graph to enforce subsequent constraints. Then, we utilize a 4D Gaussian optimization scheme with adaptive spatial-temporal regularizers to effectively balance the non-rigid prior and Gaussian updating. We also present a companion compression scheme with residual compensation for immersive experiences on various platforms. It achieves a substantial compression rate of approximately 25 times, with less than 2MB of storage per frame. Extensive experiments demonstrate the effectiveness of our approach, which significantly outperforms existing approaches in terms of optimization speed, rendering quality, and storage overhead.