 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAM: Bridging Physically-based Rendering and Gaussian Modeling for Relightable Volumetric Video
Feb 12, 2025Volumetric video enables immersive experiences by capturing dynamic 3D scenes, enabling diverse applications for virtual reality, education, and telepresence. However, traditional methods struggle with fixed lighting conditions, while neural approaches face trade-offs in efficiency, quality, or adaptability for relightable scenarios. To address these limitations, we present BEAM, a novel pipeline that bridges 4D Gaussian representations with physically-based rendering (PBR) to produce high-quality, relightable volumetric videos from multi-view RGB footage. BEAM recovers detailed geometry and PBR properties via a series of available Gaussian-based techniques. It first combines Gaussian-based performance tracking with geometry-aware rasterization in a coarse-to-fine optimization framework to recover spatially and temporally consistent geometries. We further enhance Gaussian attributes by incorporating PBR properties step by step. We generate roughness via a multi-view-conditioned diffusion model, and then derive AO and base color using a 2D-to-3D strategy, incorporating a tailored Gaussian-based ray tracer for efficient visibility computation. Once recovered, these dynamic, relightable assets integrate seamlessly into traditional CG pipelines, supporting real-time rendering with deferred shading and offline rendering with ray tracing. By offering realistic, lifelike visualizations under diverse lighting conditions, BEAM opens new possibilities for interactive entertainment, storytelling, and creative visualization.
EasySpec: Layer-Parallel Speculative Decoding for Efficient Multi-GPU Utilization
Feb 04, 2025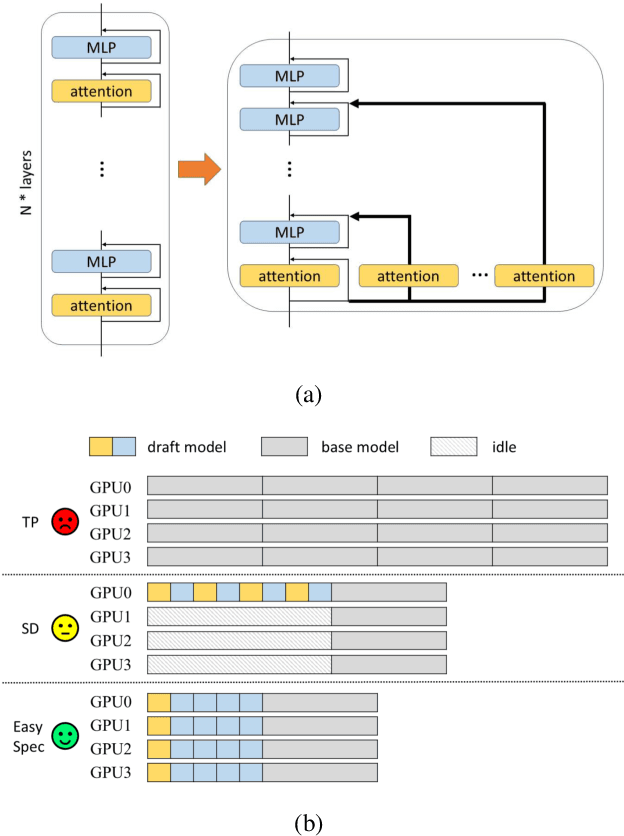
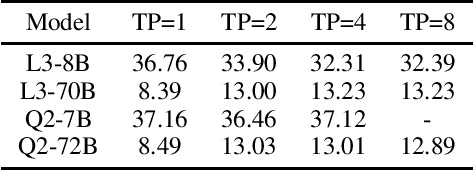
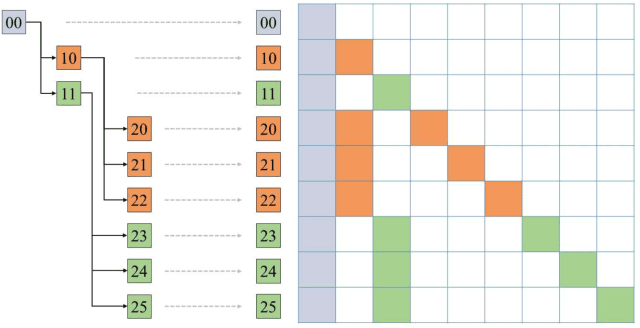
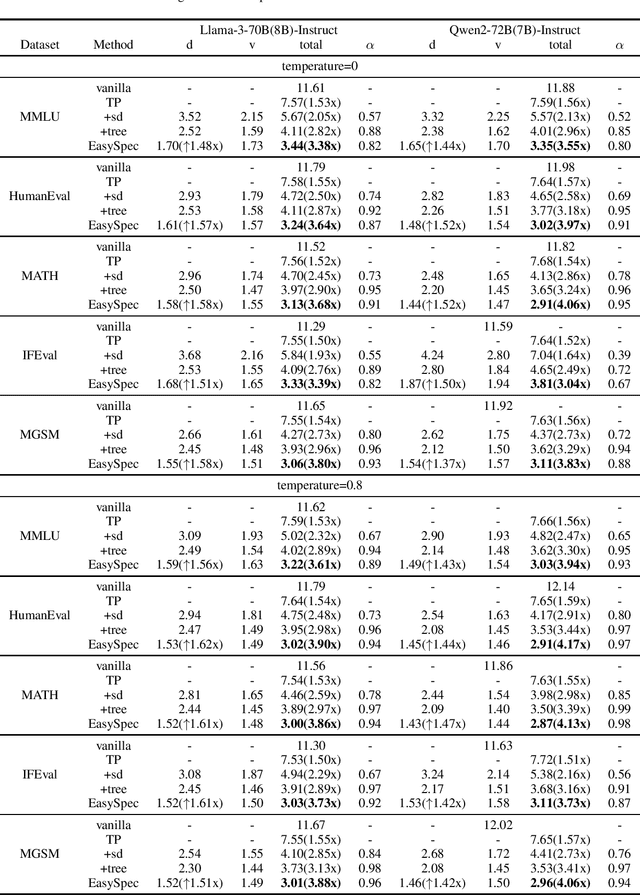
Speculative decoding is an effective and lossless method for Large Language Model (LLM) inference acceleration. It employs a smaller model to generate a draft token sequence, which is then verified by the original base model. In multi-GPU systems, inference latency can be further reduced through tensor parallelism (TP), while the optimal TP size of the draft model is typically smaller than that of the base model, leading to GPU idling during the drafting stage. To solve this problem, we propose EasySpec, a layer-parallel speculation strategy that optimizes the efficiency of multi-GPU utilization.EasySpec breaks the sequential execution order of layers in the drafting model, enabling multi-layer parallelization across devices, albeit with some induced approximation errors. After each drafting-and-verification iteration, the draft model's key-value (KV) cache is calibrated in a single forward pass, preventing long-term error accumulation at minimal additional latency. We evaluated EasySpec on several mainstream open-source LLMs, using smaller versions of models from the same series as drafters. The results demonstrate that EasySpec can achieve a peak speedup of 4.17x compared to vanilla decoding, while preserving the original distribution of the base LLMs. Specifically, the drafting stage can be accelerated by up to 1.62x with a maximum accuracy drop of only 7%, requiring no training or fine-tuning on the draft models.
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
Sep 12, 2024Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.