 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANGLED: Generating 3D Hair Strands from Images with Arbitrary Styles and Viewpoints
Feb 10, 2025



Hairstyles are intricate and culturally significant with various geometries, textures, and structures. Existing text or image-guided generation methods fail to handle the richness and complexity of diverse styles. We present TANGLED, a novel approach for 3D hair strand generation that accommodates diverse image inputs across styles, viewpoints, and quantities of input views. TANGLED employs a three-step pipeline. First, our MultiHair Dataset provides 457 diverse hairstyles annotated with 74 attributes, emphasizing complex and culturally significant styles to improve model generalization. Second, we propose a diffusion framework conditioned on multi-view linearts that can capture topological cues (e.g., strand density and parting lines) while filtering out noise. By leveraging a latent diffusion model with cross-attention on lineart features, our method achieves flexible and robust 3D hair generation across diverse input conditions. Third, a parametric post-processing module enforces braid-specific constraints to maintain coherence in complex structures. This framework not only advances hairstyle realism and diversity but also enables culturally inclusive digital avatars and novel applications like sketch-based 3D strand editing for animation and augmented reality.
Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
Jan 30, 2024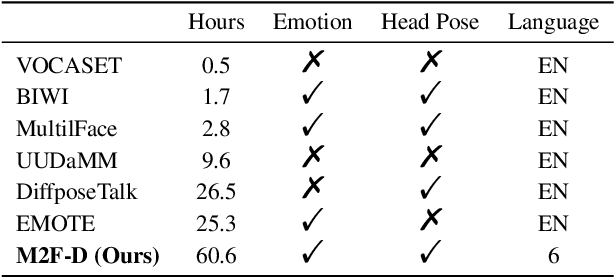
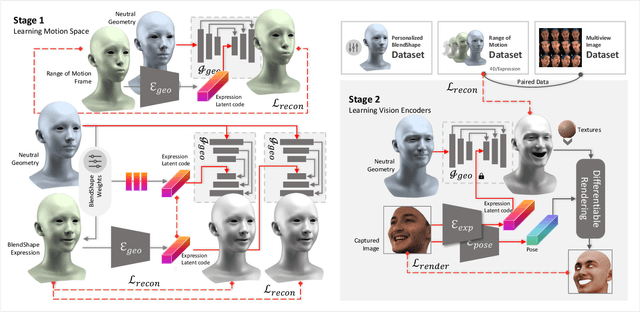

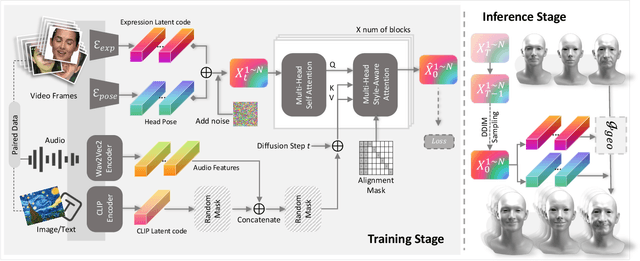
The synthesis of 3D facial animations from speech has garnered considerable attention. Due to the scarcity of high-quality 4D facial data and well-annotated abundant multi-modality labels, previous methods often suffer from limited realism and a lack of lexible conditioning. We address this challenge through a trilogy. We first introduce Generalized Neural Parametric Facial Asset (GNPFA), an efficient variational auto-encoder mapping facial geometry and images to a highly generalized expression latent space, decoupling expressions and identities. Then, we utilize GNPFA to extract high-quality expressions and accurate head poses from a large array of videos. This presents the M2F-D dataset, a large, diverse, and scan-level co-speech 3D facial animation dataset with well-annotated emotional and style labels. Finally, we propose Media2Face, a diffusion model in GNPFA latent space for co-speech facial animation generation, accepting rich multi-modality guidances from audio, text, and image. Extensive experiments demonstrate that our model not only achieves high fidelity in facial animation synthesis but also broadens the scope of expressiveness and style adaptability in 3D facial animation.