 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
Mar 18, 2026Automatically generating photorealistic and self-consistent appearances for untextured 3D models is a critical challenge in digital content creation. The advancement of large-scale video generation models offers a natural approach: directly synthesizing 360-degree turntable videos (TTVs), which can serve not only as high-quality dynamic previews but also as an intermediate representation to drive texture synthesis and neural rendering. However, existing general-purpose video diffusion models struggle to maintain strict geometric consistency and appearance stability across the full range of views, making their outputs ill-suited for high-quality 3D reconstruction. To this end, we introduce TAPESTRY, a framework for generating high-fidelity TTVs conditioned on explicit 3D geometry. We reframe the 3D appearance generation task as a geometry-conditioned video diffusion problem: given a 3D mesh, we first render and encode multi-modal geometric features to constrain the video generation process with pixel-level precision, thereby enabling the creation of high-quality and consistent TTVs. Building upon this, we also design a method for downstream reconstruction tasks from the TTV input, featuring a multi-stage pipeline with 3D-Aware Inpainting. By rotating the model and performing a context-aware secondary generation, this pipeline effectively completes self-occluded regions to achieve full surface coverage. The videos generated by TAPESTRY are not only high-quality dynamic previews but also serve as a reliable, 3D-aware intermediate representation that can be seamlessly back-projected into UV textures or used to supervise neural rendering methods like 3DGS. This enables the automated creation of production-ready, complete 3D assets from untextured meshes. Experimental results demonstrate that our method outperforms existing approaches in both video consistency and final reconstruction quality.
CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image
Feb 18, 2025Recovering high-quality 3D scenes from a single RGB image is a challenging task in computer graphics. Current methods often struggle with domain-specific limitations or low-quality object generation. To address these, we propose CAST (Component-Aligned 3D Scene Reconstruction from a Single RGB Image), a novel method for 3D scene reconstruction and recovery. CAST starts by extracting object-level 2D segmentation and relative depth information from the input image, followed by using a GPT-based model to analyze inter-object spatial relationships. This enables the understanding of how objects relate to each other within the scene, ensuring more coherent reconstruction. CAST then employs an occlusion-aware large-scale 3D generation model to independently generate each object's full geometry, using MAE and point cloud conditioning to mitigate the effects of occlusions and partial object information, ensuring accurate alignment with the source image's geometry and texture. To align each object with the scene, the alignment generation model computes the necessary transformations, allowing the generated meshes to be accurately placed and integrated into the scene's point cloud. Finally, CAST incorporates a physics-aware correction step that leverages a fine-grained relation graph to generate a constraint graph. This graph guides the optimization of object poses, ensuring physical consistency and spatial coherence. By utilizing Signed Distance Fields (SDF), the model effectively addresses issues such as occlusions, object penetration, and floating objects, ensuring that the generated scene accurately reflects real-world physical interactions. CAST can be leveraged in robotics, enabling efficient real-to-simulation workflows and providing realistic, scalable simulation environments for robotic systems.
CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets
May 30, 2024



In the realm of digital creativity, our potential to craft intricate 3D worlds from imagination is often hampered by the limitations of existing digital tools, which demand extensive expertise and efforts. To narrow this disparity, we introduce CLAY, a 3D geometry and material generator designed to effortlessly transform human imagination into intricate 3D digital structures. CLAY supports classic text or image inputs as well as 3D-aware controls from diverse primitives (multi-view images, voxels, bounding boxes, point clouds, implicit representations, etc). At its core is a large-scale generative model composed of a multi-resolution Variational Autoencoder (VAE) and a minimalistic latent Diffusion Transformer (DiT), to extract rich 3D priors directly from a diverse range of 3D geometries. Specifically, it adopts neural fields to represent continuous and complete surfaces and uses a geometry generative module with pure transformer blocks in latent space. We present a progressive training scheme to train CLAY on an ultra large 3D model dataset obtained through a carefully designed processing pipeline, resulting in a 3D native geometry generator with 1.5 billion parameters. For appearance generation, CLAY sets out to produce physically-based rendering (PBR) textures by employing a multi-view material diffusion model that can generate 2K resolution textures with diffuse, roughness, and metallic modalities. We demonstrate using CLAY for a range of controllable 3D asset creations, from sketchy conceptual designs to production ready assets with intricate details. Even first time users can easily use CLAY to bring their vivid 3D imaginations to life, unleashing unlimited creativity.
GaussianHair: Hair Modeling and Rendering with Light-aware Gaussians
Feb 16, 2024


Hairstyle reflects culture and ethnicity at first glance. In the digital era, various realistic human hairstyles are also critical to high-fidelity digital human assets for beauty and inclusivity. Yet, realistic hair modeling and real-time rendering for animation is a formidable challenge due to its sheer number of strands, complicated structures of geometry, and sophisticated interaction with light. This paper presents GaussianHair, a novel explicit hair representation. It enables comprehensive modeling of hair geometry and appearance from images, fostering innovative illumination effects and dynamic animation capabilities. At the heart of GaussianHair is the novel concept of representing each hair strand as a sequence of connected cylindrical 3D Gaussian primitives. This approach not only retains the hair's geometric structure and appearance but also allows for efficient rasterization onto a 2D image plane, facilitating differentiable volumetric rendering. We further enhance this model with the "GaussianHair Scattering Model", adept at recreating the slender structure of hair strands and accurately capturing their local diffuse color in uniform lighting. Through extensive experiments, we substantiate that GaussianHair achieves breakthroughs in both geometric and appearance fidelity, transcending the limitations encountered in state-of-the-art methods for hair reconstruction. Beyond representation, GaussianHair extends to support editing, relighting, and dynamic rendering of hair, offering seamless integration with conventional CG pipeline workflows. Complementing these advancements, we have compiled an extensive dataset of real human hair, each with meticulously detailed strand geometry, to propel further research in this field.
Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
Jan 30, 2024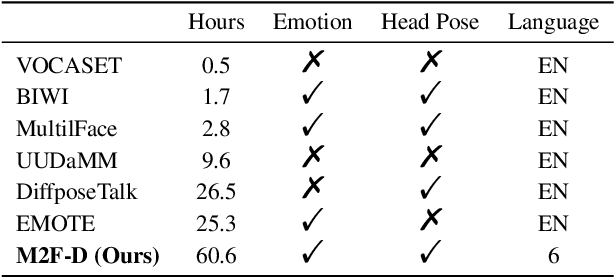
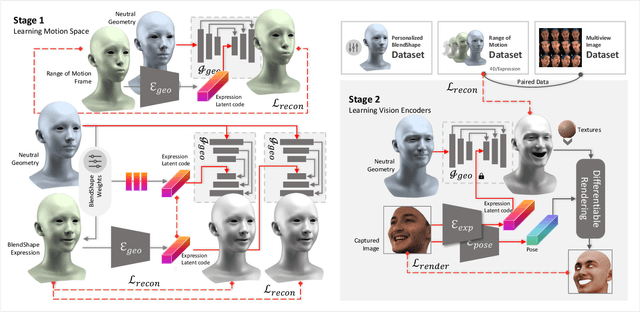

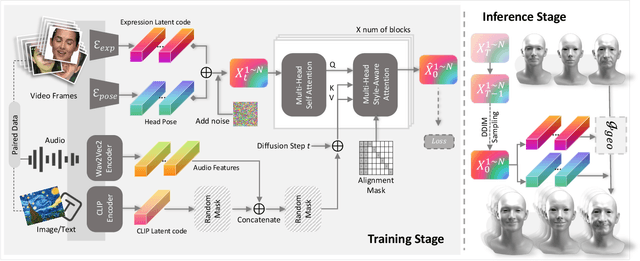
The synthesis of 3D facial animations from speech has garnered considerable attention. Due to the scarcity of high-quality 4D facial data and well-annotated abundant multi-modality labels, previous methods often suffer from limited realism and a lack of lexible conditioning. We address this challenge through a trilogy. We first introduce Generalized Neural Parametric Facial Asset (GNPFA), an efficient variational auto-encoder mapping facial geometry and images to a highly generalized expression latent space, decoupling expressions and identities. Then, we utilize GNPFA to extract high-quality expressions and accurate head poses from a large array of videos. This presents the M2F-D dataset, a large, diverse, and scan-level co-speech 3D facial animation dataset with well-annotated emotional and style labels. Finally, we propose Media2Face, a diffusion model in GNPFA latent space for co-speech facial animation generation, accepting rich multi-modality guidances from audio, text, and image. Extensive experiments demonstrate that our model not only achieves high fidelity in facial animation synthesis but also broadens the scope of expressiveness and style adaptability in 3D facial animation.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022
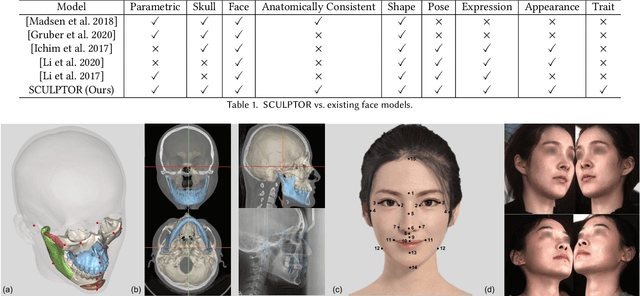
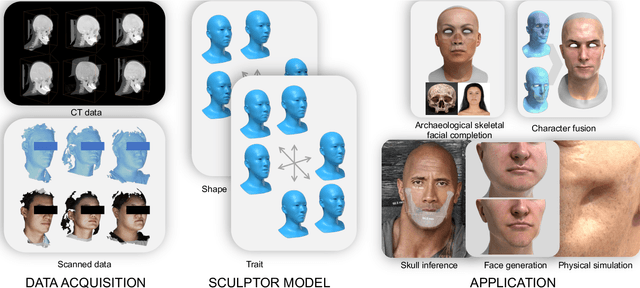
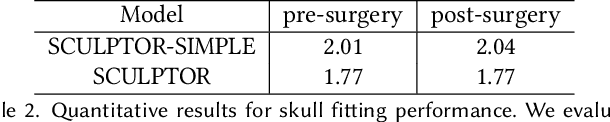
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.
Video-driven Neural Physically-based Facial Asset for Production
Feb 18, 2022
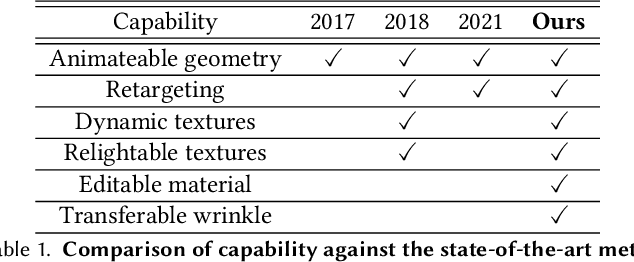

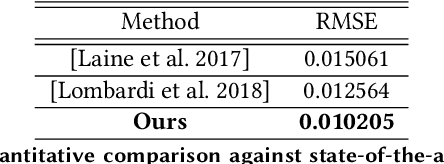
Production-level workflows for producing convincing 3D dynamic human faces have long relied on a disarray of labor-intensive tools for geometry and texture generation, motion capture and rigging, and expression synthesis. Recent neural approaches automate individual components but the corresponding latent representations cannot provide artists explicit controls as in conventional tools. In this paper, we present a new learning-based, video-driven approach for generating dynamic facial geometries with high-quality physically-based assets. Two key components are well-structured latent spaces due to dense temporal samplings from videos and explicit facial expression controls to regulate the latent spaces. For data collection, we construct a hybrid multiview-photometric capture stage, coupling with an ultra-fast video camera to obtain raw 3D facial assets. We then model the facial expression, geometry and physically-based textures using separate VAEs with a global MLP-based expression mapping across the latent spaces, to preserve characteristics across respective attributes while maintaining explicit controls over geometry and texture. We also introduce to model the delta information as wrinkle maps for physically-base textures, achieving high-quality rendering of dynamic textures. We demonstrate our approach in high-fidelity performer-specific facial capture and cross-identity facial motion retargeting. In addition, our neural asset along with fast adaptation schemes can also be deployed to handle in-the-wild videos. Besides, we motivate the utility of our explicit facial disentangle strategy by providing promising physically-based editing results like geometry and material editing or winkle transfer with high realism. Comprehensive experiments show that our technique provides higher accuracy and visual fidelity than previous video-driven facial reconstruction and animation methods.
NIMBLE: A Non-rigid Hand Model with Bones and Muscles
Feb 09, 2022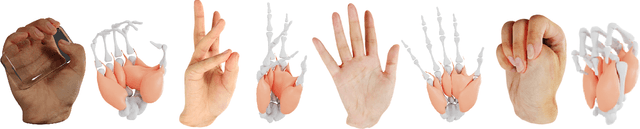
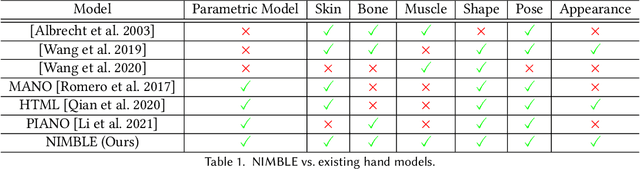

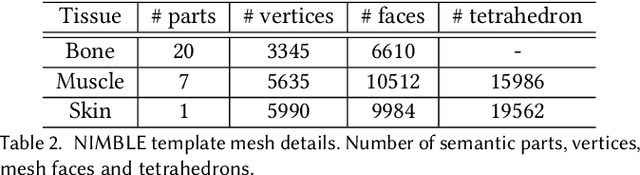
Emerging Metaverse applications demand reliable, accurate, and photorealistic reproductions of human hands to perform sophisticated operations as if in the physical world. While real human hand represents one of the most intricate coordination between bones, muscle, tendon, and skin, state-of-the-art techniques unanimously focus on modeling only the skeleton of the hand. In this paper, we present NIMBLE, a novel parametric hand model that includes the missing key components, bringing 3D hand model to a new level of realism. We first annotate muscles, bones and skins on the recent Magnetic Resonance Imaging hand (MRI-Hand) dataset and then register a volumetric template hand onto individual poses and subjects within the dataset. NIMBLE consists of 20 bones as triangular meshes, 7 muscle groups as tetrahedral meshes, and a skin mesh. Via iterative shape registration and parameter learning, it further produces shape blend shapes, pose blend shapes, and a joint regressor. We demonstrate applying NIMBLE to modeling, rendering, and visual inference tasks. By enforcing the inner bones and muscles to match anatomic and kinematic rules, NIMBLE can animate 3D hands to new poses at unprecedented realism. To model the appearance of skin, we further construct a photometric HandStage to acquire high-quality textures and normal maps to model wrinkles and palm print. Finally, NIMBLE also benefits learning-based hand pose and shape estimation by either synthesizing rich data or acting directly as a differentiable layer in the inference network.
Neural Video Portrait Relighting in Real-time via Consistency Modeling
Apr 01, 2021
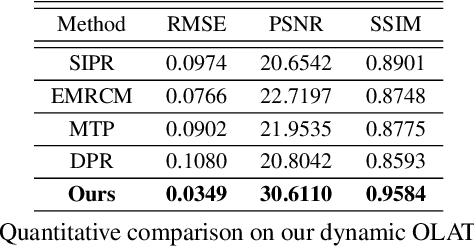
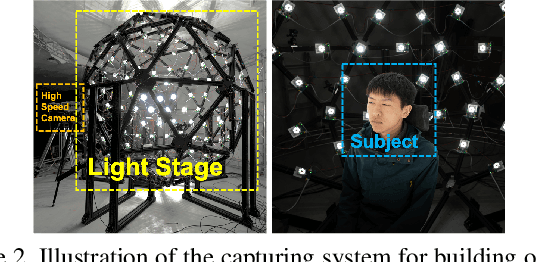
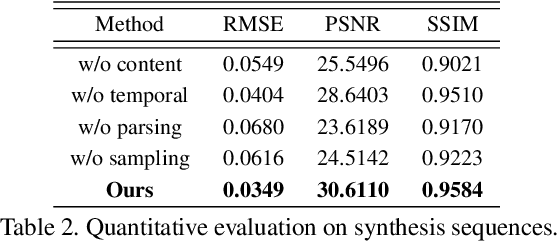
Video portraits relighting is critical in user-facing human photography, especially for immersive VR/AR experience. Recent advances still fail to recover consistent relit result under dynamic illuminations from monocular RGB stream, suffering from the lack of video consistency supervision. In this paper, we propose a neural approach for real-time, high-quality and coherent video portrait relighting, which jointly models the semantic, temporal and lighting consistency using a new dynamic OLAT dataset. We propose a hybrid structure and lighting disentanglement in an encoder-decoder architecture, which combines a multi-task and adversarial training strategy for semantic-aware consistency modeling. We adopt a temporal modeling scheme via flow-based supervision to encode the conjugated temporal consistency in a cross manner. We also propose a lighting sampling strategy to model the illumination consistency and mutation for natural portrait light manipulation in real-world. Extensive experiments demonstrate the effectiveness of our approach for consistent video portrait light-editing and relighting, even using mobile computing.