 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Swept Volume SDF: Enabling Continuous Collision-Free Trajectory Generation for Arbitrary Shapes
May 01, 2024
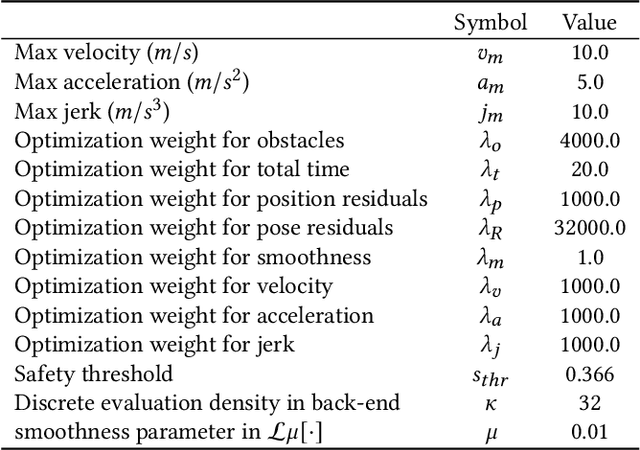


In the field of trajectory generation for objects, ensuring continuous collision-free motion remains a huge challenge, especially for non-convex geometries and complex environments. Previous methods either oversimplify object shapes, which results in a sacrifice of feasible space or rely on discrete sampling, which suffers from the "tunnel effect". To address these limitations, we propose a novel hierarchical trajectory generation pipeline, which utilizes the Swept Volume Signed Distance Field (SVSDF) to guide trajectory optimization for Continuous Collision Avoidance (CCA). Our interdisciplinary approach, blending techniques from graphics and robotics, exhibits outstanding effectiveness in solving this problem. We formulate the computation of the SVSDF as a Generalized Semi-Infinite Programming model, and we solve for the numerical solutions at query points implicitly, thereby eliminating the need for explicit reconstruction of the surface. Our algorithm has been validated in a variety of complex scenarios and applies to robots of various dynamics, including both rigid and deformable shapes. It demonstrates exceptional universality and superior CCA performance compared to typical algorithms. The code will be released at https://github.com/ZJU-FAST-Lab/Implicit-SVSDF-Planner for the benefit of the community.
Video-driven Neural Physically-based Facial Asset for Production
Feb 18, 2022
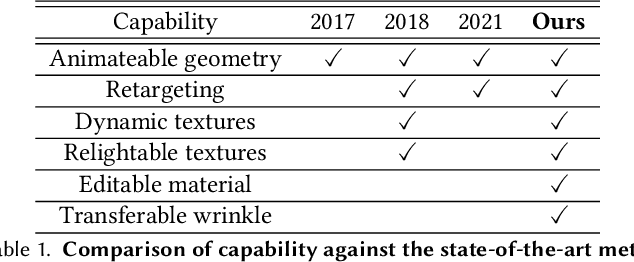

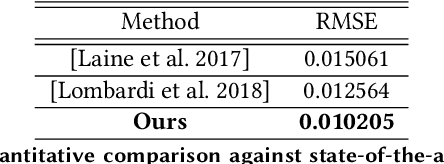
Production-level workflows for producing convincing 3D dynamic human faces have long relied on a disarray of labor-intensive tools for geometry and texture generation, motion capture and rigging, and expression synthesis. Recent neural approaches automate individual components but the corresponding latent representations cannot provide artists explicit controls as in conventional tools. In this paper, we present a new learning-based, video-driven approach for generating dynamic facial geometries with high-quality physically-based assets. Two key components are well-structured latent spaces due to dense temporal samplings from videos and explicit facial expression controls to regulate the latent spaces. For data collection, we construct a hybrid multiview-photometric capture stage, coupling with an ultra-fast video camera to obtain raw 3D facial assets. We then model the facial expression, geometry and physically-based textures using separate VAEs with a global MLP-based expression mapping across the latent spaces, to preserve characteristics across respective attributes while maintaining explicit controls over geometry and texture. We also introduce to model the delta information as wrinkle maps for physically-base textures, achieving high-quality rendering of dynamic textures. We demonstrate our approach in high-fidelity performer-specific facial capture and cross-identity facial motion retargeting. In addition, our neural asset along with fast adaptation schemes can also be deployed to handle in-the-wild videos. Besides, we motivate the utility of our explicit facial disentangle strategy by providing promising physically-based editing results like geometry and material editing or winkle transfer with high realism. Comprehensive experiments show that our technique provides higher accuracy and visual fidelity than previous video-driven facial reconstruction and animation methods.