 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
X-Part: high fidelity and structure coherent shape decomposition
Sep 10, 2025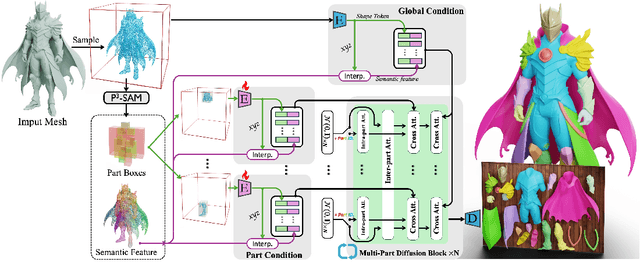
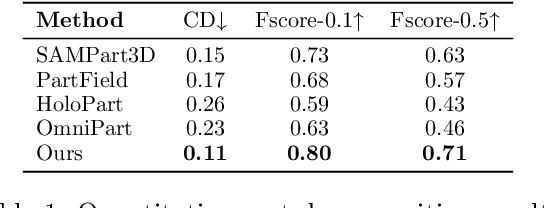

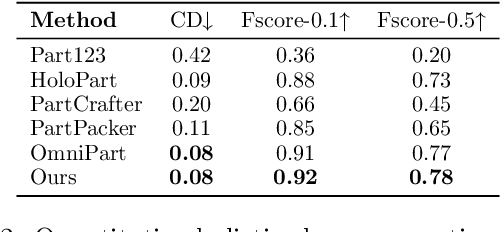
Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image
Feb 18, 2025Recovering high-quality 3D scenes from a single RGB image is a challenging task in computer graphics. Current methods often struggle with domain-specific limitations or low-quality object generation. To address these, we propose CAST (Component-Aligned 3D Scene Reconstruction from a Single RGB Image), a novel method for 3D scene reconstruction and recovery. CAST starts by extracting object-level 2D segmentation and relative depth information from the input image, followed by using a GPT-based model to analyze inter-object spatial relationships. This enables the understanding of how objects relate to each other within the scene, ensuring more coherent reconstruction. CAST then employs an occlusion-aware large-scale 3D generation model to independently generate each object's full geometry, using MAE and point cloud conditioning to mitigate the effects of occlusions and partial object information, ensuring accurate alignment with the source image's geometry and texture. To align each object with the scene, the alignment generation model computes the necessary transformations, allowing the generated meshes to be accurately placed and integrated into the scene's point cloud. Finally, CAST incorporates a physics-aware correction step that leverages a fine-grained relation graph to generate a constraint graph. This graph guides the optimization of object poses, ensuring physical consistency and spatial coherence. By utilizing Signed Distance Fields (SDF), the model effectively addresses issues such as occlusions, object penetration, and floating objects, ensuring that the generated scene accurately reflects real-world physical interactions. CAST can be leveraged in robotics, enabling efficient real-to-simulation workflows and providing realistic, scalable simulation environments for robotic systems.
Dual-Space NeRF: Learning Animatable Avatars and Scene Lighting in Separate Spaces
Aug 31, 2022

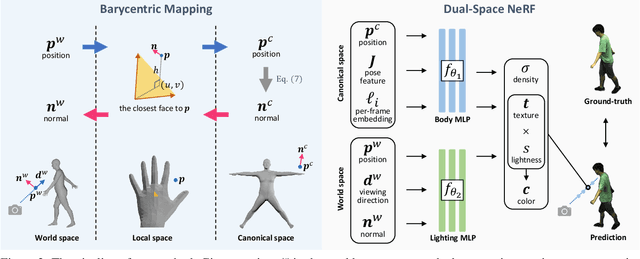

Modeling the human body in a canonical space is a common practice for capturing and animation. But when involving the neural radiance field (NeRF), learning a static NeRF in the canonical space is not enough because the lighting of the body changes when the person moves even though the scene lighting is constant. Previous methods alleviate the inconsistency of lighting by learning a per-frame embedding, but this operation does not generalize to unseen poses. Given that the lighting condition is static in the world space while the human body is consistent in the canonical space, we propose a dual-space NeRF that models the scene lighting and the human body with two MLPs in two separate spaces. To bridge these two spaces, previous methods mostly rely on the linear blend skinning (LBS) algorithm. However, the blending weights for LBS of a dynamic neural field are intractable and thus are usually memorized with another MLP, which does not generalize to novel poses. Although it is possible to borrow the blending weights of a parametric mesh such as SMPL, the interpolation operation introduces more artifacts. In this paper, we propose to use the barycentric mapping, which can directly generalize to unseen poses and surprisingly achieves superior results than LBS with neural blending weights. Quantitative and qualitative results on the Human3.6M and the ZJU-MoCap datasets show the effectiveness of our method.
PREF: Phasorial Embedding Fields for Compact Neural Representations
May 26, 2022

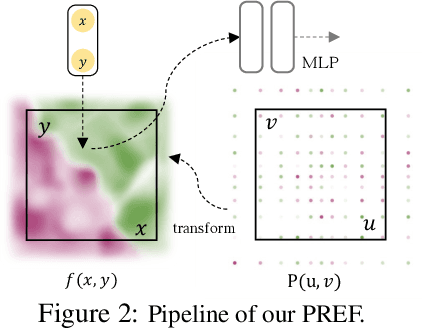
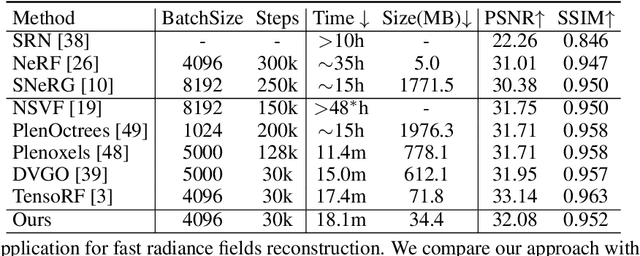
We present a phasorial embedding field \emph{PREF} as a compact representation to facilitate neural signal modeling and reconstruction tasks. Pure multi-layer perceptron (MLP) based neural techniques are biased towards low frequency signals and have relied on deep layers or Fourier encoding to avoid losing details. PREF instead employs a compact and physically explainable encoding field based on the phasor formulation of the Fourier embedding space. We conduct a comprehensive theoretical analysis to demonstrate the advantages of PREF over the latest spatial embedding techniques. We then develop a highly efficient frequency learning framework using an approximated inverse Fourier transform scheme for PREF along with a novel Parseval regularizer. Extensive experiments show our compact PREF-based neural signal processing technique is on par with the state-of-the-art in 2D image completion, 3D SDF surface regression, and 5D radiance field reconstruction.