 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
X-Part: high fidelity and structure coherent shape decomposition
Sep 10, 2025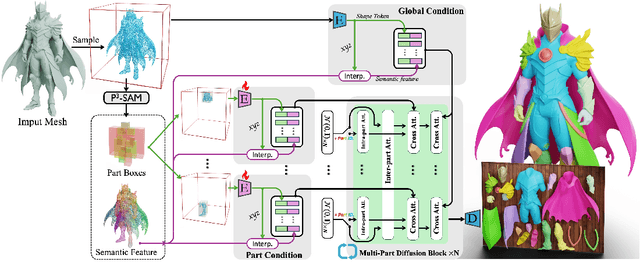
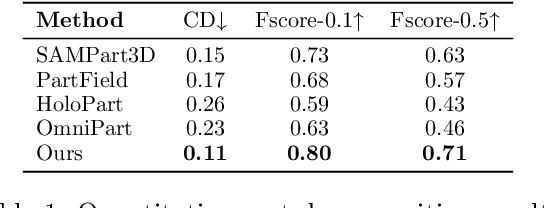

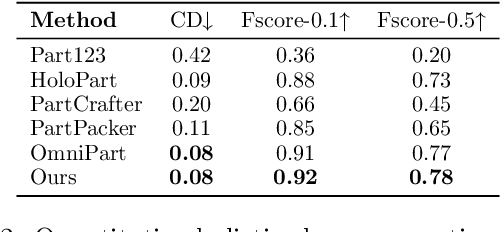
Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
Parameterize Structure with Differentiable Template for 3D Shape Generation
Oct 15, 2024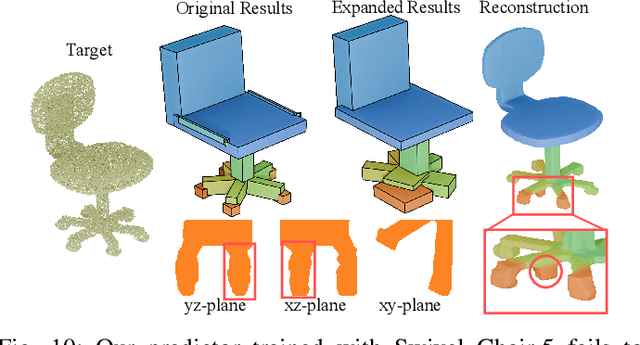
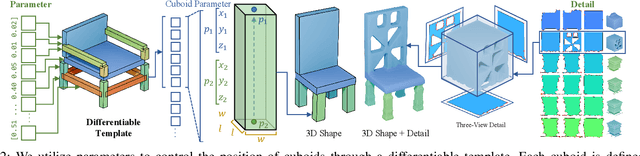
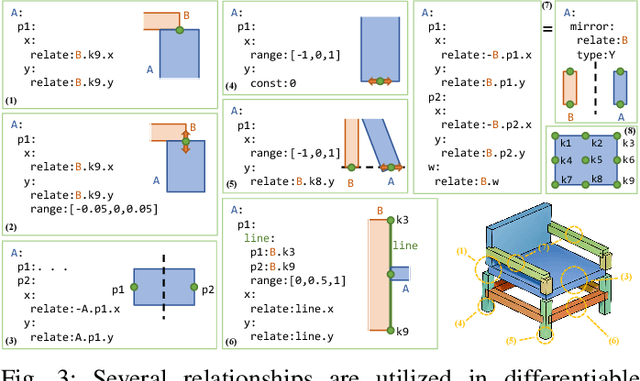

Structural representation is crucial for reconstructing and generating editable 3D shapes with part semantics. Recent 3D shape generation works employ complicated networks and structure definitions relying on hierarchical annotations and pay less attention to the details inside parts. In this paper, we propose the method that parameterizes the shared structure in the same category using a differentiable template and corresponding fixed-length parameters. Specific parameters are fed into the template to calculate cuboids that indicate a concrete shape. We utilize the boundaries of three-view drawings of each cuboid to further describe the inside details. Shapes are represented with the parameters and three-view details inside cuboids, from which the SDF can be calculated to recover the object. Benefiting from our fixed-length parameters and three-view details, our networks for reconstruction and generation are simple and effective to learn the latent space. Our method can reconstruct or generate diverse shapes with complicated details, and interpolate them smoothly. Extensive evaluations demonstrate the superiority of our method on reconstruction from point cloud, generation, and interpolation.
Quasi Non-Negative Quaternion Matrix Factorization with Application to Color Face Recognition
Nov 30, 2022To address the non-negativity dropout problem of quaternion models, a novel quasi non-negative quaternion matrix factorization (QNQMF) model is presented for color image processing. To implement QNQMF, the quaternion projected gradient algorithm and the quaternion alternating direction method of multipliers are proposed via formulating QNQMF as the non-convex constraint quaternion optimization problems. Some properties of the proposed algorithms are studied. The numerical experiments on the color image reconstruction show that these algorithms encoded on the quaternion perform better than these algorithms encoded on the red, green and blue channels. Furthermore, we apply the proposed algorithms to the color face recognition. Numerical results indicate that the accuracy rate of face recognition on the quaternion model is better than on the red, green and blue channels of color image as well as single channel of gray level images for the same data, when large facial expressions and shooting angle variations are presented.
Completing Partial Point Clouds with Outliers by Collaborative Completion and Segmentation
Mar 18, 2022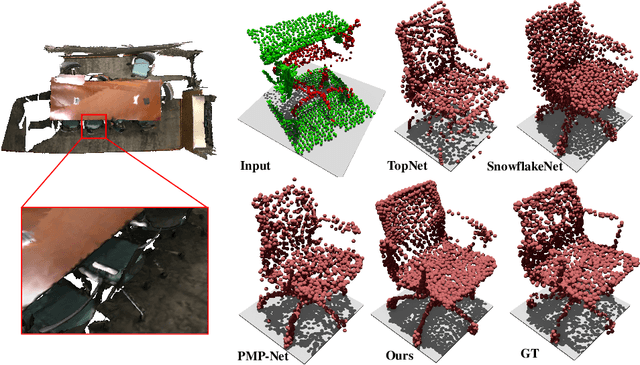
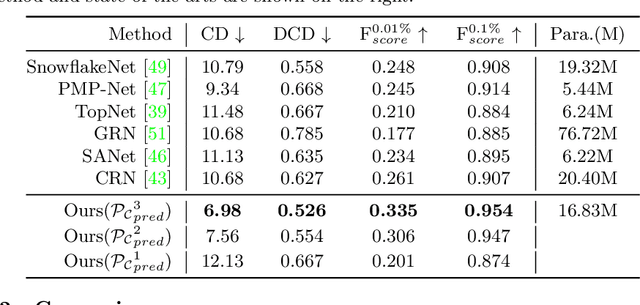
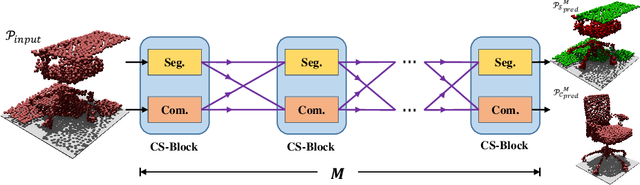
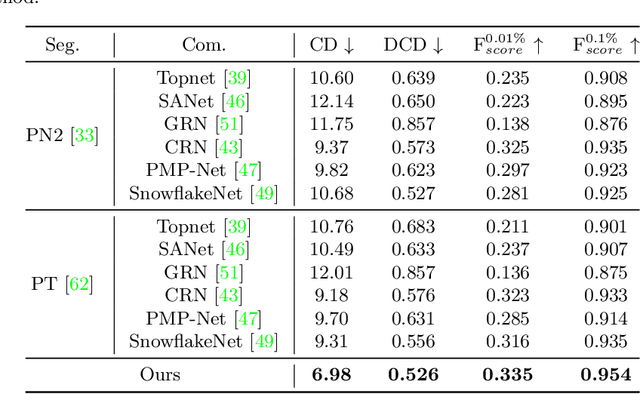
Most existing point cloud completion methods are only applicable to partial point clouds without any noises and outliers, which does not always hold in practice. We propose in this paper an end-to-end network, named CS-Net, to complete the point clouds contaminated by noises or containing outliers. In our CS-Net, the completion and segmentation modules work collaboratively to promote each other, benefited from our specifically designed cascaded structure. With the help of segmentation, more clean point cloud is fed into the completion module. We design a novel completion decoder which harnesses the labels obtained by segmentation together with FPS to purify the point cloud and leverages KNN-grouping for better generation. The completion and segmentation modules work alternately share the useful information from each other to gradually improve the quality of prediction. To train our network, we build a dataset to simulate the real case where incomplete point clouds contain outliers. Our comprehensive experiments and comparisons against state-of-the-art completion methods demonstrate our superiority. We also compare with the scheme of segmentation followed by completion and their end-to-end fusion, which also proves our efficacy.