 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision
Apr 01, 2026Existing humanoid table tennis systems remain limited by their reliance on external sensing and their inability to achieve agile whole-body coordination for precise task execution. These limitations stem from two core challenges: achieving low-latency and robust onboard egocentric perception under fast robot motion, and obtaining sufficiently diverse task-aligned strike motions for learning precise yet natural whole-body behaviors. In this work, we present \methodname, a modular system for agile humanoid table tennis that unifies scalable whole-body skill learning with onboard egocentric perception, eliminating the need for external cameras during deployment. Our work advances prior humanoid table-tennis systems in three key aspects. First, we achieve agile and precise ball interaction with tightly coordinated whole-body control, rather than relying on decoupled upper- and lower-body behaviors. This enables the system to exhibit diverse strike motions, including explosive whole-body smashes and low crouching shots. Second, by augmenting and diversifying strike motions with a generative model, our framework benefits from scalable motion priors and produces natural, robust striking behaviors across a wide workspace. Third, to the best of our knowledge, we demonstrate the first humanoid table-tennis system capable of consecutive strikes using onboard sensing alone, despite the challenges of low-latency perception, ego-motion-induced instability, and limited field of view. Extensive real-world experiments demonstrate stable and precise ball exchanges under high-speed conditions, validating scalable, perception-driven whole-body skill learning for dynamic humanoid interaction tasks.
SeGPruner: Semantic-Geometric Visual Token Pruner for 3D Question Answering
Mar 31, 2026Vision-language models (VLMs) have been widely adopted for 3D question answering (3D QA). In typical pipelines, visual tokens extracted from multiple viewpoints are concatenated with language tokens and jointly processed by a large language model (LLM) for inference. However, aggregating multi-view observations inevitably introduces severe token redundancy, leading to an overly large visual token set that significantly hinders inference efficiency under constrained token budgets. Visual token pruning has emerged as a prevalent strategy to address this issue. Nevertheless, most existing pruners are primarily tailored to 2D inputs or rely on indirect geometric cues, which limits their ability to explicitly retain semantically critical objects and maintain sufficient spatial coverage for robust 3D reasoning. In this paper, we propose SeGPruner, a semantic-aware and geometry-guided token reduction framework for efficient 3D QA with multi-view images. Specifically, SeGPruner first preserves semantically salient tokens through an attention-based importance module (Saliency-aware Token Selector), ensuring that object-critical evidence is retained. It then complements these tokens with spatially diverse ones via a geometry-guided selector (Geometry-aware Token Diversifier), which jointly considers semantic relevance and 3D geometric distance. This cooperation between saliency preservation and geometry-guided diversification balances object-level evidence and global scene coverage under aggressive token reduction. Extensive experiments on ScanQA and OpenEQA demonstrate that SeGPruner substantially improves inference efficiency, reducing the visual token budget by 91% and inference latency by 86%, while maintaining competitive performance in 3D reasoning tasks.
TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
Mar 18, 2026Automatically generating photorealistic and self-consistent appearances for untextured 3D models is a critical challenge in digital content creation. The advancement of large-scale video generation models offers a natural approach: directly synthesizing 360-degree turntable videos (TTVs), which can serve not only as high-quality dynamic previews but also as an intermediate representation to drive texture synthesis and neural rendering. However, existing general-purpose video diffusion models struggle to maintain strict geometric consistency and appearance stability across the full range of views, making their outputs ill-suited for high-quality 3D reconstruction. To this end, we introduce TAPESTRY, a framework for generating high-fidelity TTVs conditioned on explicit 3D geometry. We reframe the 3D appearance generation task as a geometry-conditioned video diffusion problem: given a 3D mesh, we first render and encode multi-modal geometric features to constrain the video generation process with pixel-level precision, thereby enabling the creation of high-quality and consistent TTVs. Building upon this, we also design a method for downstream reconstruction tasks from the TTV input, featuring a multi-stage pipeline with 3D-Aware Inpainting. By rotating the model and performing a context-aware secondary generation, this pipeline effectively completes self-occluded regions to achieve full surface coverage. The videos generated by TAPESTRY are not only high-quality dynamic previews but also serve as a reliable, 3D-aware intermediate representation that can be seamlessly back-projected into UV textures or used to supervise neural rendering methods like 3DGS. This enables the automated creation of production-ready, complete 3D assets from untextured meshes. Experimental results demonstrate that our method outperforms existing approaches in both video consistency and final reconstruction quality.
EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration
Feb 10, 2026Human demonstrations offer rich environmental diversity and scale naturally, making them an appealing alternative to robot teleoperation. While this paradigm has advanced robot-arm manipulation, its potential for the more challenging, data-hungry problem of humanoid loco-manipulation remains largely unexplored. We present EgoHumanoid, the first framework to co-train a vision-language-action policy using abundant egocentric human demonstrations together with a limited amount of robot data, enabling humanoids to perform loco-manipulation across diverse real-world environments. To bridge the embodiment gap between humans and robots, including discrepancies in physical morphology and viewpoint, we introduce a systematic alignment pipeline spanning from hardware design to data processing. A portable system for scalable human data collection is developed, and we establish practical collection protocols to improve transferability. At the core of our human-to-humanoid alignment pipeline lies two key components. The view alignment reduces visual domain discrepancies caused by camera height and perspective variation. The action alignment maps human motions into a unified, kinematically feasible action space for humanoid control. Extensive real-world experiments demonstrate that incorporating robot-free egocentric data significantly outperforms robot-only baselines by 51\%, particularly in unseen environments. Our analysis further reveals which behaviors transfer effectively and the potential for scaling human data.
WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
Dec 15, 2025Humanoid robots require precise locomotion and dexterous manipulation to perform challenging loco-manipulation tasks. Yet existing approaches, modular or end-to-end, are deficient in manipulation-aware locomotion. This confines the robot to a limited workspace, preventing it from performing large-space loco-manipulation. We attribute this to: (1) the challenge of acquiring loco-manipulation knowledge due to the scarcity of humanoid teleoperation data, and (2) the difficulty of faithfully and reliably executing locomotion commands, stemming from the limited precision and stability of existing RL controllers. To acquire richer loco-manipulation knowledge, we propose a unified latent learning framework that enables Vision-Language-Action (VLA) system to learn from low-cost action-free egocentric videos. Moreover, an efficient human data collection pipeline is devised to augment the dataset and scale the benefits. To execute the desired locomotion commands more precisely, we present a loco-manipulation-oriented (LMO) RL policy specifically tailored for accurate and stable core loco-manipulation movements, such as advancing, turning, and squatting. Building on these components, we introduce WholeBodyVLA, a unified framework for humanoid loco-manipulation. To the best of our knowledge, WholeBodyVLA is one of its kind enabling large-space humanoid loco-manipulation. It is verified via comprehensive experiments on the AgiBot X2 humanoid, outperforming prior baseline by 21.3%. It also demonstrates strong generalization and high extensibility across a broad range of tasks.
HypoChainer: A Collaborative System Combining LLMs and Knowledge Graphs for Hypothesis-Driven Scientific Discovery
Jul 23, 2025



Modern scientific discovery faces growing challenges in integrating vast and heterogeneous knowledge critical to breakthroughs in biomedicine and drug development. Traditional hypothesis-driven research, though effective, is constrained by human cognitive limits, the complexity of biological systems, and the high cost of trial-and-error experimentation. Deep learning models, especially graph neural networks (GNNs), have accelerated prediction generation, but the sheer volume of outputs makes manual selection for validation unscalable. Large language models (LLMs) offer promise in filtering and hypothesis generation, yet suffer from hallucinations and lack grounding in structured knowledge, limiting their reliability. To address these issues, we propose HypoChainer, a collaborative visualization framework that integrates human expertise, LLM-driven reasoning, and knowledge graphs (KGs) to enhance hypothesis generation and validation. HypoChainer operates in three stages: First, exploration and contextualization -- experts use retrieval-augmented LLMs (RAGs) and dimensionality reduction to navigate large-scale GNN predictions, assisted by interactive explanations. Second, hypothesis chain formation -- experts iteratively examine KG relationships around predictions and semantically linked entities, refining hypotheses with LLM and KG suggestions. Third, validation prioritization -- refined hypotheses are filtered based on KG-supported evidence to identify high-priority candidates for experimentation, with visual analytics further strengthening weak links in reasoning. We demonstrate HypoChainer's effectiveness through case studies in two domains and expert interviews, highlighting its potential to support interpretable, scalable, and knowledge-grounded scientific discovery.
Detect Anything 3D in the Wild
Apr 10, 2025Despite the success of deep learning in close-set 3D object detection, existing approaches struggle with zero-shot generalization to novel objects and camera configurations. We introduce DetAny3D, a promptable 3D detection foundation model capable of detecting any novel object under arbitrary camera configurations using only monocular inputs. Training a foundation model for 3D detection is fundamentally constrained by the limited availability of annotated 3D data, which motivates DetAny3D to leverage the rich prior knowledge embedded in extensively pre-trained 2D foundation models to compensate for this scarcity. To effectively transfer 2D knowledge to 3D, DetAny3D incorporates two core modules: the 2D Aggregator, which aligns features from different 2D foundation models, and the 3D Interpreter with Zero-Embedding Mapping, which mitigates catastrophic forgetting in 2D-to-3D knowledge transfer. Experimental results validate the strong generalization of our DetAny3D, which not only achieves state-of-the-art performance on unseen categories and novel camera configurations, but also surpasses most competitors on in-domain data.DetAny3D sheds light on the potential of the 3D foundation model for diverse applications in real-world scenarios, e.g., rare object detection in autonomous driving, and demonstrates promise for further exploration of 3D-centric tasks in open-world settings. More visualization results can be found at DetAny3D project page.
ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipulation Detection
Nov 29, 2024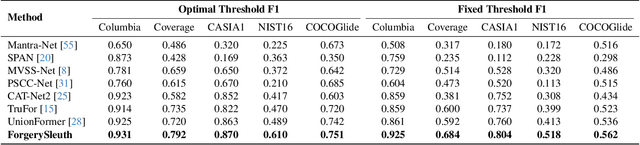
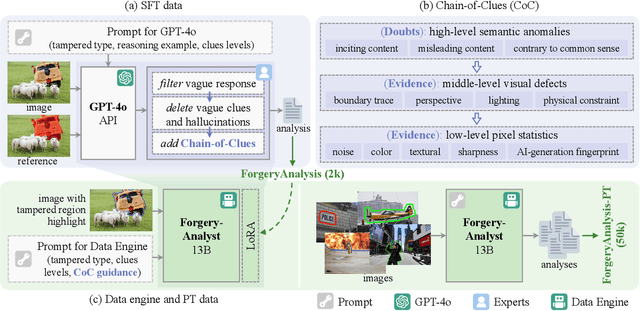
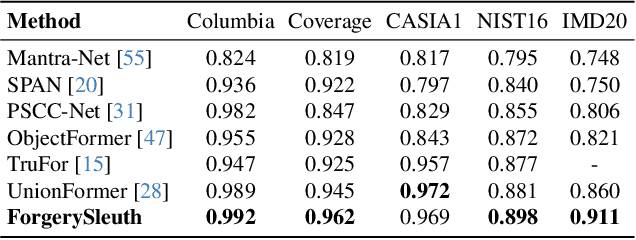
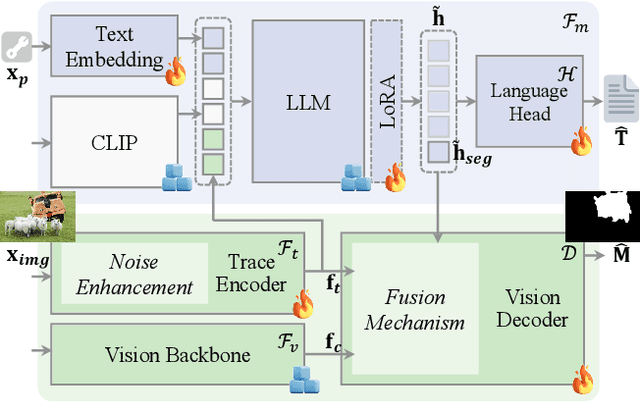
Multimodal large language models have unlocked new possibilities for various multimodal tasks. However, their potential in image manipulation detection remains unexplored. When directly applied to the IMD task, M-LLMs often produce reasoning texts that suffer from hallucinations and overthinking. To address this, in this work, we propose ForgerySleuth, which leverages M-LLMs to perform comprehensive clue fusion and generate segmentation outputs indicating specific regions that are tampered with. Moreover, we construct the ForgeryAnalysis dataset through the Chain-of-Clues prompt, which includes analysis and reasoning text to upgrade the image manipulation detection task. A data engine is also introduced to build a larger-scale dataset for the pre-training phase. Our extensive experiments demonstrate the effectiveness of ForgeryAnalysis and show that ForgerySleuth significantly outperforms existing methods in generalization, robustness, and explainability.
Task Consistent Prototype Learning for Incremental Few-shot Semantic Segmentation
Oct 16, 2024



Incremental Few-Shot Semantic Segmentation (iFSS) tackles a task that requires a model to continually expand its segmentation capability on novel classes using only a few annotated examples. Typical incremental approaches encounter a challenge that the objective of the base training phase (fitting base classes with sufficient instances) does not align with the incremental learning phase (rapidly adapting to new classes with less forgetting). This disconnect can result in suboptimal performance in the incremental setting. This study introduces a meta-learning-based prototype approach that encourages the model to learn how to adapt quickly while preserving previous knowledge. Concretely, we mimic the incremental evaluation protocol during the base training session by sampling a sequence of pseudo-incremental tasks. Each task in the simulated sequence is trained using a meta-objective to enable rapid adaptation without forgetting. To enhance discrimination among class prototypes, we introduce prototype space redistribution learning, which dynamically updates class prototypes to establish optimal inter-prototype boundaries within the prototype space. Extensive experiments on iFSS datasets built upon PASCAL and COCO benchmarks show the advanced performance of the proposed approach, offering valuable insights for addressing iFSS challenges.
CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets
May 30, 2024



In the realm of digital creativity, our potential to craft intricate 3D worlds from imagination is often hampered by the limitations of existing digital tools, which demand extensive expertise and efforts. To narrow this disparity, we introduce CLAY, a 3D geometry and material generator designed to effortlessly transform human imagination into intricate 3D digital structures. CLAY supports classic text or image inputs as well as 3D-aware controls from diverse primitives (multi-view images, voxels, bounding boxes, point clouds, implicit representations, etc). At its core is a large-scale generative model composed of a multi-resolution Variational Autoencoder (VAE) and a minimalistic latent Diffusion Transformer (DiT), to extract rich 3D priors directly from a diverse range of 3D geometries. Specifically, it adopts neural fields to represent continuous and complete surfaces and uses a geometry generative module with pure transformer blocks in latent space. We present a progressive training scheme to train CLAY on an ultra large 3D model dataset obtained through a carefully designed processing pipeline, resulting in a 3D native geometry generator with 1.5 billion parameters. For appearance generation, CLAY sets out to produce physically-based rendering (PBR) textures by employing a multi-view material diffusion model that can generate 2K resolution textures with diffuse, roughness, and metallic modalities. We demonstrate using CLAY for a range of controllable 3D asset creations, from sketchy conceptual designs to production ready assets with intricate details. Even first time users can easily use CLAY to bring their vivid 3D imaginations to life, unleashing unlimited creativity.