 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETA: Efficiency through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
Jun 09, 2025How can we benefit from large models without sacrificing inference speed, a common dilemma in self-driving systems? A prevalent solution is a dual-system architecture, employing a small model for rapid, reactive decisions and a larger model for slower but more informative analyses. Existing dual-system designs often implement parallel architectures where inference is either directly conducted using the large model at each current frame or retrieved from previously stored inference results. However, these works still struggle to enable large models for a timely response to every online frame. Our key insight is to shift intensive computations of the current frame to previous time steps and perform a batch inference of multiple time steps to make large models respond promptly to each time step. To achieve the shifting, we introduce Efficiency through Thinking Ahead (ETA), an asynchronous system designed to: (1) propagate informative features from the past to the current frame using future predictions from the large model, (2) extract current frame features using a small model for real-time responsiveness, and (3) integrate these dual features via an action mask mechanism that emphasizes action-critical image regions. Evaluated on the Bench2Drive CARLA Leaderboard-v2 benchmark, ETA advances state-of-the-art performance by 8% with a driving score of 69.53 while maintaining a near-real-time inference speed at 50 ms.
Decoupled Diffusion Sparks Adaptive Scene Generation
Apr 14, 2025Controllable scene generation could reduce the cost of diverse data collection substantially for autonomous driving. Prior works formulate the traffic layout generation as predictive progress, either by denoising entire sequences at once or by iteratively predicting the next frame. However, full sequence denoising hinders online reaction, while the latter's short-sighted next-frame prediction lacks precise goal-state guidance. Further, the learned model struggles to generate complex or challenging scenarios due to a large number of safe and ordinal driving behaviors from open datasets. To overcome these, we introduce Nexus, a decoupled scene generation framework that improves reactivity and goal conditioning by simulating both ordinal and challenging scenarios from fine-grained tokens with independent noise states. At the core of the decoupled pipeline is the integration of a partial noise-masking training strategy and a noise-aware schedule that ensures timely environmental updates throughout the denoising process. To complement challenging scenario generation, we collect a dataset consisting of complex corner cases. It covers 540 hours of simulated data, including high-risk interactions such as cut-in, sudden braking, and collision. Nexus achieves superior generation realism while preserving reactivity and goal orientation, with a 40% reduction in displacement error. We further demonstrate that Nexus improves closed-loop planning by 20% through data augmentation and showcase its capability in safety-critical data generation.
Detect Anything 3D in the Wild
Apr 10, 2025Despite the success of deep learning in close-set 3D object detection, existing approaches struggle with zero-shot generalization to novel objects and camera configurations. We introduce DetAny3D, a promptable 3D detection foundation model capable of detecting any novel object under arbitrary camera configurations using only monocular inputs. Training a foundation model for 3D detection is fundamentally constrained by the limited availability of annotated 3D data, which motivates DetAny3D to leverage the rich prior knowledge embedded in extensively pre-trained 2D foundation models to compensate for this scarcity. To effectively transfer 2D knowledge to 3D, DetAny3D incorporates two core modules: the 2D Aggregator, which aligns features from different 2D foundation models, and the 3D Interpreter with Zero-Embedding Mapping, which mitigates catastrophic forgetting in 2D-to-3D knowledge transfer. Experimental results validate the strong generalization of our DetAny3D, which not only achieves state-of-the-art performance on unseen categories and novel camera configurations, but also surpasses most competitors on in-domain data.DetAny3D sheds light on the potential of the 3D foundation model for diverse applications in real-world scenarios, e.g., rare object detection in autonomous driving, and demonstrates promise for further exploration of 3D-centric tasks in open-world settings. More visualization results can be found at DetAny3D project page.
Test-time Correction with Human Feedback: An Online 3D Detection System via Visual Prompting
Dec 10, 2024This paper introduces Test-time Correction (TTC) system, a novel online 3D detection system designated for online correction of test-time errors via human feedback, to guarantee the safety of deployed autonomous driving systems. Unlike well-studied offline 3D detectors frozen at inference, TTC explores the capability of instant online error rectification. By leveraging user feedback with interactive prompts at a frame, e.g., a simple click or draw of boxes, TTC could immediately update the corresponding detection results for future streaming inputs, even though the model is deployed with fixed parameters. This enables autonomous driving systems to adapt to new scenarios immediately and decrease deployment risks reliably without additional expensive training. To achieve such TTC system, we equip existing 3D detectors with Online Adapter (OA) module, a prompt-driven query generator for online correction. At the core of OA module are visual prompts, images of missed object-of-interest for guiding the corresponding detection and subsequent tracking. Those visual prompts, belonging to missed objects through online inference, are maintained by the visual prompt buffer for continuous error correction in subsequent frames. By doing so, TTC consistently detects online missed objects and immediately lowers driving risks. It achieves reliable, versatile, and adaptive driving autonomy. Extensive experiments demonstrate significant gain on instant error rectification over pre-trained 3D detectors, even in challenging scenarios with limited labels, zero-shot detection, and adverse conditions. We hope this work would inspire the community to investigate online rectification systems for autonomous driving post-deployment. Code would be publicly shared.
NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking
Jun 21, 2024



Benchmarking vision-based driving policies is challenging. On one hand, open-loop evaluation with real data is easy, but these results do not reflect closed-loop performance. On the other, closed-loop evaluation is possible in simulation, but is hard to scale due to its significant computational demands. Further, the simulators available today exhibit a large domain gap to real data. This has resulted in an inability to draw clear conclusions from the rapidly growing body of research on end-to-end autonomous driving. In this paper, we present NAVSIM, a middle ground between these evaluation paradigms, where we use large datasets in combination with a non-reactive simulator to enable large-scale real-world benchmarking. Specifically, we gather simulation-based metrics, such as progress and time to collision, by unrolling bird's eye view abstractions of the test scenes for a short simulation horizon. Our simulation is non-reactive, i.e., the evaluated policy and environment do not influence each other. As we demonstrate empirically, this decoupling allows open-loop metric computation while being better aligned with closed-loop evaluations than traditional displacement errors. NAVSIM enabled a new competition held at CVPR 2024, where 143 teams submitted 463 entries, resulting in several new insights. On a large set of challenging scenarios, we observe that simple methods with moderate compute requirements such as TransFuser can match recent large-scale end-to-end driving architectures such as UniAD. Our modular framework can potentially be extended with new datasets, data curation strategies, and metrics, and will be continually maintained to host future challenges. Our code is available at https://github.com/autonomousvision/navsim.
Improving Distant 3D Object Detection Using 2D Box Supervision
Mar 14, 2024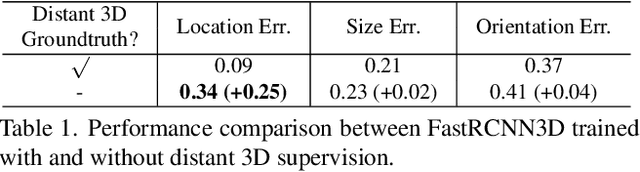
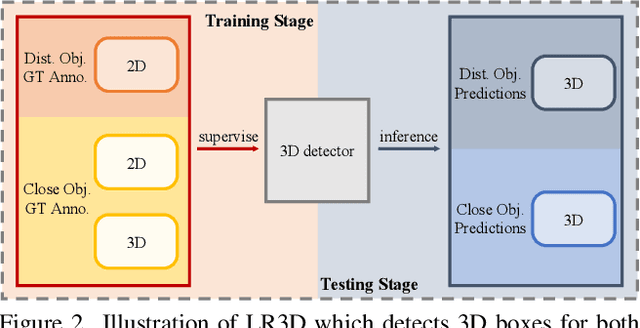
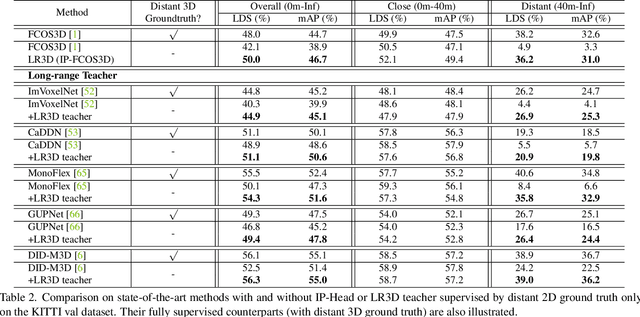
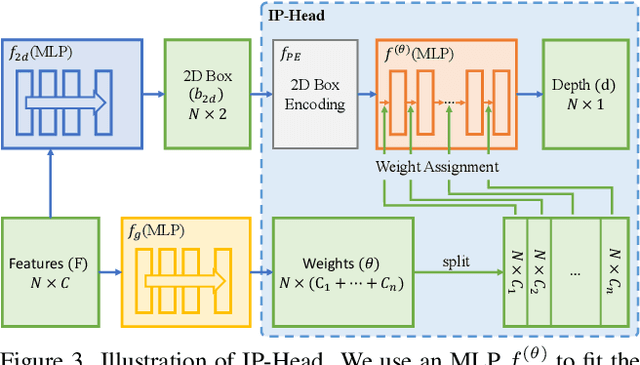
Improving the detection of distant 3d objects is an important yet challenging task. For camera-based 3D perception, the annotation of 3d bounding relies heavily on LiDAR for accurate depth information. As such, the distance of annotation is often limited due to the sparsity of LiDAR points on distant objects, which hampers the capability of existing detectors for long-range scenarios. We address this challenge by considering only 2D box supervision for distant objects since they are easy to annotate. We propose LR3D, a framework that learns to recover the missing depth of distant objects. LR3D adopts an implicit projection head to learn the generation of mapping between 2D boxes and depth using the 3D supervision on close objects. This mapping allows the depth estimation of distant objects conditioned on their 2D boxes, making long-range 3D detection with 2D supervision feasible. Experiments show that without distant 3D annotations, LR3D allows camera-based methods to detect distant objects (over 200m) with comparable accuracy to full 3D supervision. Our framework is general, and could widely benefit 3D detection methods to a large extent.
Visual Point Cloud Forecasting enables Scalable Autonomous Driving
Dec 29, 2023



In contrast to extensive studies on general vision, pre-training for scalable visual autonomous driving remains seldom explored. Visual autonomous driving applications require features encompassing semantics, 3D geometry, and temporal information simultaneously for joint perception, prediction, and planning, posing dramatic challenges for pre-training. To resolve this, we bring up a new pre-training task termed as visual point cloud forecasting - predicting future point clouds from historical visual input. The key merit of this task captures the synergic learning of semantics, 3D structures, and temporal dynamics. Hence it shows superiority in various downstream tasks. To cope with this new problem, we present ViDAR, a general model to pre-train downstream visual encoders. It first extracts historical embeddings by the encoder. These representations are then transformed to 3D geometric space via a novel Latent Rendering operator for future point cloud prediction. Experiments show significant gain in downstream tasks, e.g., 3.1% NDS on 3D detection, ~10% error reduction on motion forecasting, and ~15% less collision rate on planning.
Fully Sparse 3D Panoptic Occupancy Prediction
Dec 29, 2023Occupancy prediction plays a pivotal role in the realm of autonomous driving. Previous methods typically constructs a dense 3D volume, neglecting the inherent sparsity of the scene, which results in a high computational cost. Furthermore, these methods are limited to semantic occupancy and fail to differentiate between distinct instances. To exploit the sparsity property and ensure instance-awareness, we introduce a novel fully sparse panoptic occupancy network, termed SparseOcc. SparseOcc initially reconstructs a sparse 3D representation from visual inputs. Subsequently, it employs sparse instance queries to predict each object instance from the sparse 3D representation. These instance queries interact with 2D features via mask-guided sparse sampling, thereby circumventing the need for costly dense features or global attention. Additionally, we have established the first-ever vision-centric panoptic occupancy benchmark. SparseOcc demonstrates its efficacy on the Occ3D-nus dataset by achieving a mean Intersection over Union (mIoU) of 26.0, while maintaining a real-time inference speed of 25.4 FPS. By incorporating temporal modeling from the preceding 8 frames, SparseOcc further improves its performance, achieving 30.9 mIoU without whistles and bells. Code will be made available.
Self-supervised Pre-training with Masked Shape Prediction for 3D Scene Understanding
May 08, 2023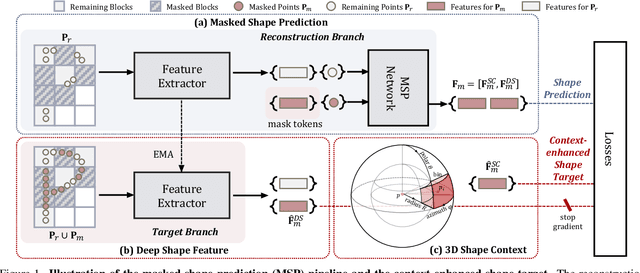



Masked signal modeling has greatly advanced self-supervised pre-training for language and 2D images. However, it is still not fully explored in 3D scene understanding. Thus, this paper introduces Masked Shape Prediction (MSP), a new framework to conduct masked signal modeling in 3D scenes. MSP uses the essential 3D semantic cue, i.e., geometric shape, as the prediction target for masked points. The context-enhanced shape target consisting of explicit shape context and implicit deep shape feature is proposed to facilitate exploiting contextual cues in shape prediction. Meanwhile, the pre-training architecture in MSP is carefully designed to alleviate the masked shape leakage from point coordinates. Experiments on multiple 3D understanding tasks on both indoor and outdoor datasets demonstrate the effectiveness of MSP in learning good feature representations to consistently boost downstream performance.
A Unified Query-based Paradigm for Point Cloud Understanding
Mar 03, 2022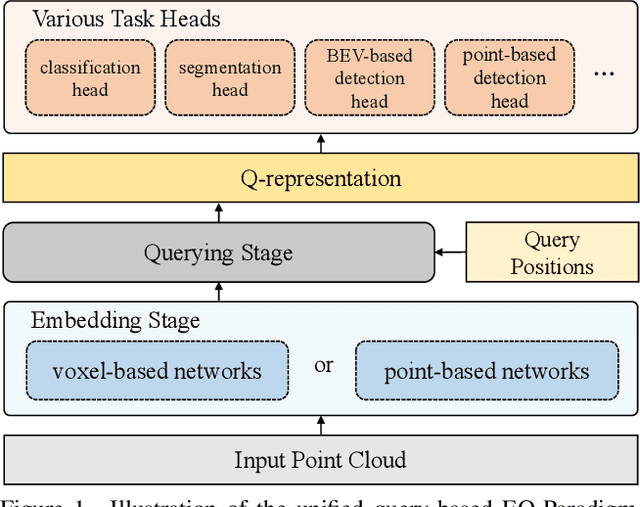
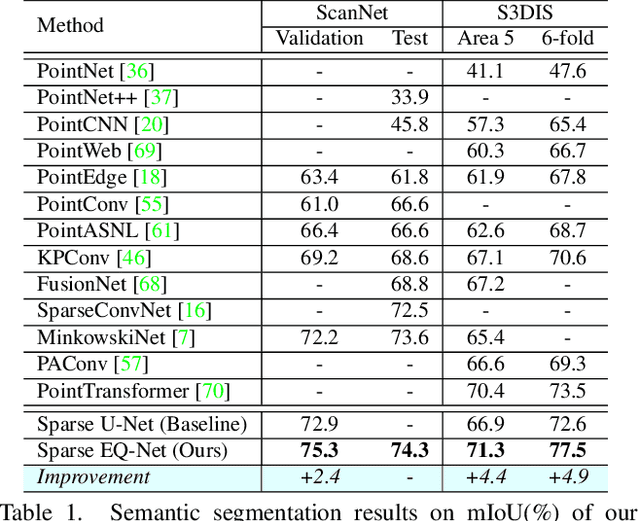
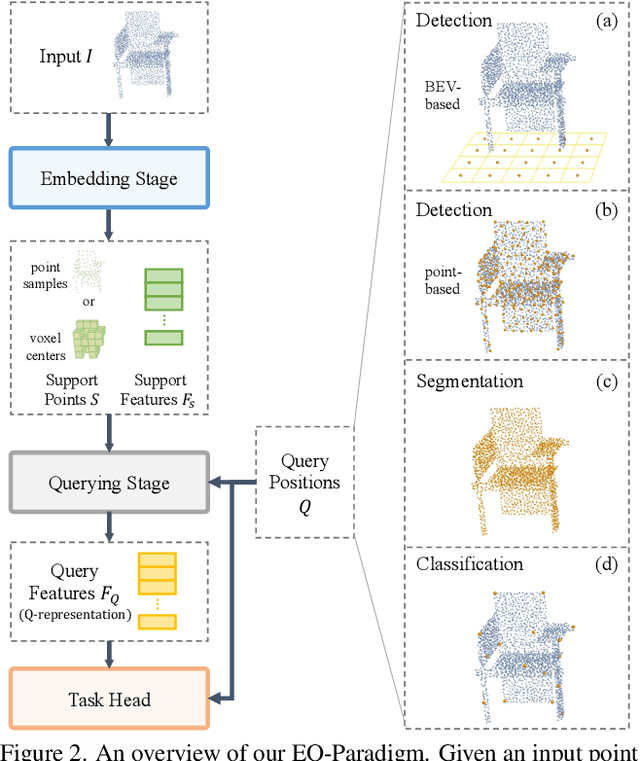
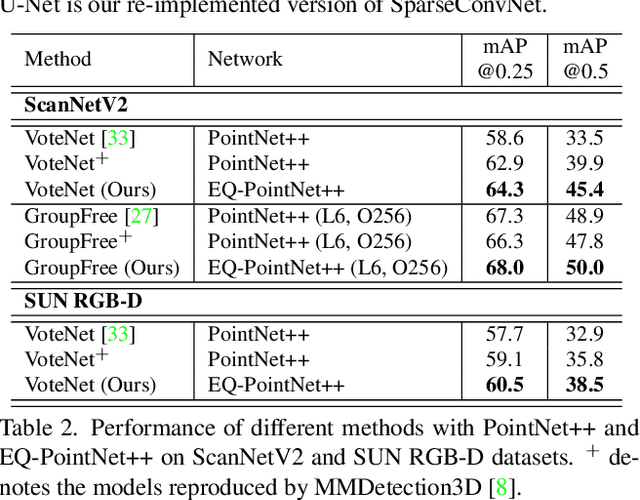
3D point cloud understanding is an important component in autonomous driving and robotics. In this paper, we present a novel Embedding-Querying paradigm (EQ-Paradigm) for 3D understanding tasks including detection, segmentation and classification. EQ-Paradigm is a unified paradigm that enables the combination of any existing 3D backbone architectures with different task heads. Under the EQ-Paradigm, the input is firstly encoded in the embedding stage with an arbitrary feature extraction architecture, which is independent of tasks and heads. Then, the querying stage enables the encoded features to be applicable for diverse task heads. This is achieved by introducing an intermediate representation, i.e., Q-representation, in the querying stage to serve as a bridge between the embedding stage and task heads. We design a novel Q-Net as the querying stage network. Extensive experimental results on various 3D tasks including semantic segmentation, object detection and shape classification show that EQ-Paradigm in tandem with Q-Net is a general and effective pipeline, which enables a flexible collaboration of backbones and heads, and further boosts the performance of the state-of-the-art methods. All codes and models will be published soon.