 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowIt: Global Matching for Optical Flow with Confidence-Guided Refinement
Mar 30, 2026We present FlowIt, a novel architecture for optical flow estimation designed to robustly handle large pixel displacements. At its core, FlowIt leverages a hierarchical transformer architecture that captures extensive global context, enabling the model to effectively model long-range correspondences. To overcome the limitations of localized matching, we formulate the flow initialization as an optimal transport problem. This formulation yields a highly robust initial flow field, alongside explicitly derived occlusion and confidence maps. These cues are then seamlessly integrated into a guided refinement stage, where the network actively propagates reliable motion estimates from high-confidence regions into ambiguous, low-confidence areas. Extensive experiments across the Sintel, KITTI, Spring, and LayeredFlow datasets validate the efficacy of our approach. FlowIt achieves state-of-the-art results on the competitive Sintel and KITTI benchmarks, while simultaneously establishing new state-of-the-art cross-dataset zero-shot generalization performance on Sintel, Spring, and LayeredFlow.
Real-World Point Tracking with Verifier-Guided Pseudo-Labeling
Mar 12, 2026Models for long-term point tracking are typically trained on large synthetic datasets. The performance of these models degrades in real-world videos due to different characteristics and the absence of dense ground-truth annotations. Self-training on unlabeled videos has been explored as a practical solution, but the quality of pseudo-labels strongly depends on the reliability of teacher models, which vary across frames and scenes. In this paper, we address the problem of real-world fine-tuning and introduce verifier, a meta-model that learns to assess the reliability of tracker predictions and guide pseudo-label generation. Given candidate trajectories from multiple pretrained trackers, the verifier evaluates them per frame and selects the most trustworthy predictions, resulting in high-quality pseudo-label trajectories. When applied for fine-tuning, verifier-guided pseudo-labeling substantially improves the quality of supervision and enables data-efficient adaptation to unlabeled videos. Extensive experiments on four real-world benchmarks demonstrate that our approach achieves state-of-the-art results while requiring less data than prior self-training methods. Project page: https://kuis-ai.github.io/track_on_r
Mapping like a Skeptic: Probabilistic BEV Projection for Online HD Mapping
Aug 29, 2025Constructing high-definition (HD) maps from sensory input requires accurately mapping the road elements in image space to the Bird's Eye View (BEV) space. The precision of this mapping directly impacts the quality of the final vectorized HD map. Existing HD mapping approaches outsource the projection to standard mapping techniques, such as attention-based ones. However, these methods struggle with accuracy due to generalization problems, often hallucinating non-existent road elements. Our key idea is to start with a geometric mapping based on camera parameters and adapt it to the scene to extract relevant map information from camera images. To implement this, we propose a novel probabilistic projection mechanism with confidence scores to (i) refine the mapping to better align with the scene and (ii) filter out irrelevant elements that should not influence HD map generation. In addition, we improve temporal processing by using confidence scores to selectively accumulate reliable information over time. Experiments on new splits of the nuScenes and Argoverse2 datasets demonstrate improved performance over state-of-the-art approaches, indicating better generalization. The improvements are particularly pronounced on nuScenes and in the challenging long perception range. Our code and model checkpoints are available at https://github.com/Fatih-Erdogan/mapping-like-skeptic .
ETA: Efficiency through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
Jun 09, 2025How can we benefit from large models without sacrificing inference speed, a common dilemma in self-driving systems? A prevalent solution is a dual-system architecture, employing a small model for rapid, reactive decisions and a larger model for slower but more informative analyses. Existing dual-system designs often implement parallel architectures where inference is either directly conducted using the large model at each current frame or retrieved from previously stored inference results. However, these works still struggle to enable large models for a timely response to every online frame. Our key insight is to shift intensive computations of the current frame to previous time steps and perform a batch inference of multiple time steps to make large models respond promptly to each time step. To achieve the shifting, we introduce Efficiency through Thinking Ahead (ETA), an asynchronous system designed to: (1) propagate informative features from the past to the current frame using future predictions from the large model, (2) extract current frame features using a small model for real-time responsiveness, and (3) integrate these dual features via an action mask mechanism that emphasizes action-critical image regions. Evaluated on the Bench2Drive CARLA Leaderboard-v2 benchmark, ETA advances state-of-the-art performance by 8% with a driving score of 69.53 while maintaining a near-real-time inference speed at 50 ms.
Track-On: Transformer-based Online Point Tracking with Memory
Jan 30, 2025



In this paper, we consider the problem of long-term point tracking, which requires consistent identification of points across multiple frames in a video, despite changes in appearance, lighting, perspective, and occlusions. We target online tracking on a frame-by-frame basis, making it suitable for real-world, streaming scenarios. Specifically, we introduce Track-On, a simple transformer-based model designed for online long-term point tracking. Unlike prior methods that depend on full temporal modeling, our model processes video frames causally without access to future frames, leveraging two memory modules -- spatial memory and context memory -- to capture temporal information and maintain reliable point tracking over long time horizons. At inference time, it employs patch classification and refinement to identify correspondences and track points with high accuracy. Through extensive experiments, we demonstrate that Track-On sets a new state-of-the-art for online models and delivers superior or competitive results compared to offline approaches on seven datasets, including the TAP-Vid benchmark. Our method offers a robust and scalable solution for real-time tracking in diverse applications. Project page: https://kuis-ai.github.io/track_on
Segment-Level Road Obstacle Detection Using Visual Foundation Model Priors and Likelihood Ratios
Dec 07, 2024



Detecting road obstacles is essential for autonomous vehicles to navigate dynamic and complex traffic environments safely. Current road obstacle detection methods typically assign a score to each pixel and apply a threshold to generate final predictions. However, selecting an appropriate threshold is challenging, and the per-pixel classification approach often leads to fragmented predictions with numerous false positives. In this work, we propose a novel method that leverages segment-level features from visual foundation models and likelihood ratios to predict road obstacles directly. By focusing on segments rather than individual pixels, our approach enhances detection accuracy, reduces false positives, and offers increased robustness to scene variability. We benchmark our approach against existing methods on the RoadObstacle and LostAndFound datasets, achieving state-of-the-art performance without needing a predefined threshold.
O1O: Grouping of Known Classes to Identify Unknown Objects as Odd-One-Out
Oct 10, 2024



Object detection methods trained on a fixed set of known classes struggle to detect objects of unknown classes in the open-world setting. Current fixes involve adding approximate supervision with pseudo-labels corresponding to candidate locations of objects, typically obtained in a class-agnostic manner. While previous approaches mainly rely on the appearance of objects, we find that geometric cues improve unknown recall. Although additional supervision from pseudo-labels helps to detect unknown objects, it also introduces confusion for known classes. We observed a notable decline in the model's performance for detecting known objects in the presence of noisy pseudo-labels. Drawing inspiration from studies on human cognition, we propose to group known classes into superclasses. By identifying similarities between classes within a superclass, we can identify unknown classes through an odd-one-out scoring mechanism. Our experiments on open-world detection benchmarks demonstrate significant improvements in unknown recall, consistently across all tasks. Crucially, we achieve this without compromising known performance, thanks to better partitioning of the feature space with superclasses.
Robust Bird's Eye View Segmentation by Adapting DINOv2
Sep 16, 2024



Extracting a Bird's Eye View (BEV) representation from multiple camera images offers a cost-effective, scalable alternative to LIDAR-based solutions in autonomous driving. However, the performance of the existing BEV methods drops significantly under various corruptions such as brightness and weather changes or camera failures. To improve the robustness of BEV perception, we propose to adapt a large vision foundational model, DINOv2, to BEV estimation using Low Rank Adaptation (LoRA). Our approach builds on the strong representation space of DINOv2 by adapting it to the BEV task in a state-of-the-art framework, SimpleBEV. Our experiments show increased robustness of BEV perception under various corruptions, with increasing gains from scaling up the model and the input resolution. We also showcase the effectiveness of the adapted representations in terms of fewer learnable parameters and faster convergence during training.
Self-Evolving Depth-Supervised 3D Gaussian Splatting from Rendered Stereo Pairs
Sep 11, 2024



3D Gaussian Splatting (GS) significantly struggles to accurately represent the underlying 3D scene geometry, resulting in inaccuracies and floating artifacts when rendering depth maps. In this paper, we address this limitation, undertaking a comprehensive analysis of the integration of depth priors throughout the optimization process of Gaussian primitives, and present a novel strategy for this purpose. This latter dynamically exploits depth cues from a readily available stereo network, processing virtual stereo pairs rendered by the GS model itself during training and achieving consistent self-improvement of the scene representation. Experimental results on three popular datasets, breaking ground as the first to assess depth accuracy for these models, validate our findings.
A Likelihood Ratio-Based Approach to Segmenting Unknown Objects
Sep 10, 2024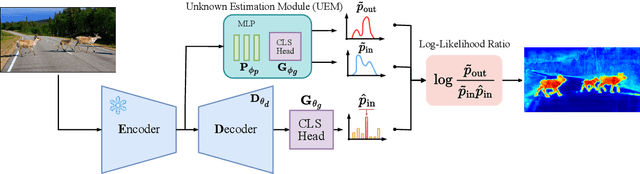

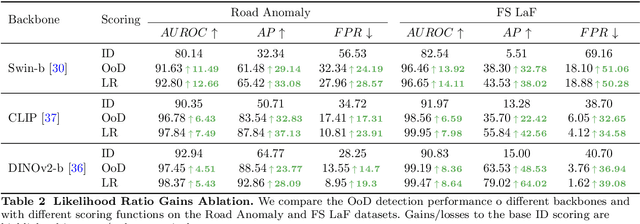
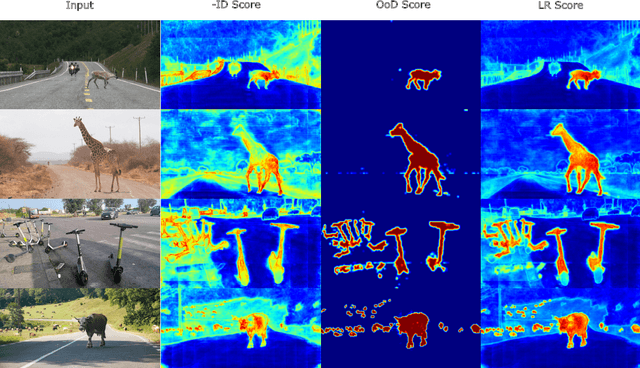
Addressing the Out-of-Distribution (OoD) segmentation task is a prerequisite for perception systems operating in an open-world environment. Large foundational models are frequently used in downstream tasks, however, their potential for OoD remains mostly unexplored. We seek to leverage a large foundational model to achieve robust representation. Outlier supervision is a widely used strategy for improving OoD detection of the existing segmentation networks. However, current approaches for outlier supervision involve retraining parts of the original network, which is typically disruptive to the model's learned feature representation. Furthermore, retraining becomes infeasible in the case of large foundational models. Our goal is to retrain for outlier segmentation without compromising the strong representation space of the foundational model. To this end, we propose an adaptive, lightweight unknown estimation module (UEM) for outlier supervision that significantly enhances the OoD segmentation performance without affecting the learned feature representation of the original network. UEM learns a distribution for outliers and a generic distribution for known classes. Using the learned distributions, we propose a likelihood-ratio-based outlier scoring function that fuses the confidence of UEM with that of the pixel-wise segmentation inlier network to detect unknown objects. We also propose an objective to optimize this score directly. Our approach achieves a new state-of-the-art across multiple datasets, outperforming the previous best method by 5.74% average precision points while having a lower false-positive rate. Importantly, strong inlier performance remains unaffected.