 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment-Level Road Obstacle Detection Using Visual Foundation Model Priors and Likelihood Ratios
Dec 07, 2024



Detecting road obstacles is essential for autonomous vehicles to navigate dynamic and complex traffic environments safely. Current road obstacle detection methods typically assign a score to each pixel and apply a threshold to generate final predictions. However, selecting an appropriate threshold is challenging, and the per-pixel classification approach often leads to fragmented predictions with numerous false positives. In this work, we propose a novel method that leverages segment-level features from visual foundation models and likelihood ratios to predict road obstacles directly. By focusing on segments rather than individual pixels, our approach enhances detection accuracy, reduces false positives, and offers increased robustness to scene variability. We benchmark our approach against existing methods on the RoadObstacle and LostAndFound datasets, achieving state-of-the-art performance without needing a predefined threshold.
Have We Ever Encountered This Before? Retrieving Out-of-Distribution Road Obstacles from Driving Scenes
Sep 08, 2023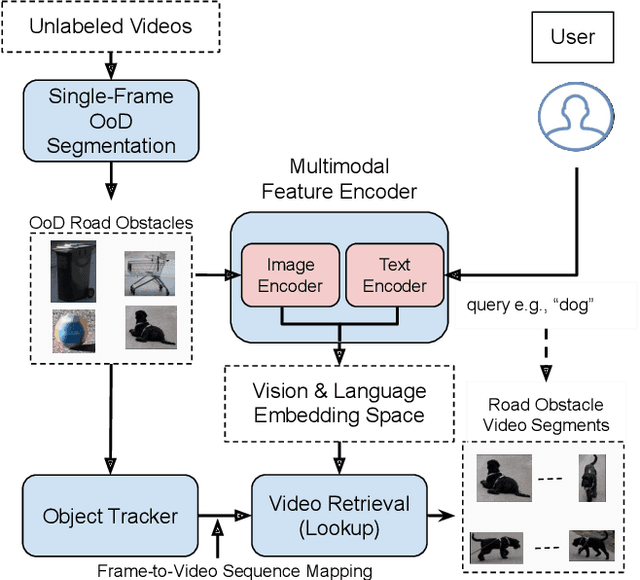
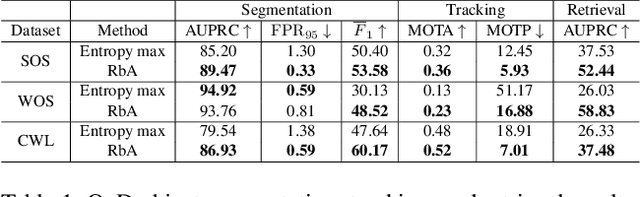
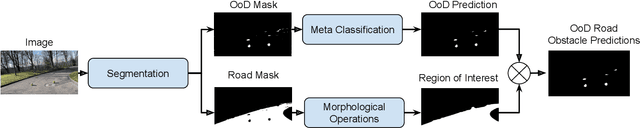
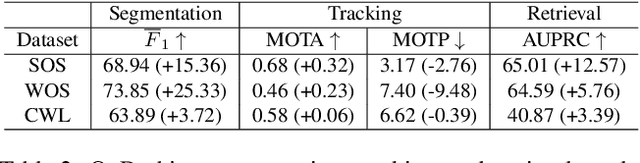
In the life cycle of highly automated systems operating in an open and dynamic environment, the ability to adjust to emerging challenges is crucial. For systems integrating data-driven AI-based components, rapid responses to deployment issues require fast access to related data for testing and reconfiguration. In the context of automated driving, this especially applies to road obstacles that were not included in the training data, commonly referred to as out-of-distribution (OoD) road obstacles. Given the availability of large uncurated recordings of driving scenes, a pragmatic approach is to query a database to retrieve similar scenarios featuring the same safety concerns due to OoD road obstacles. In this work, we extend beyond identifying OoD road obstacles in video streams and offer a comprehensive approach to extract sequences of OoD road obstacles using text queries, thereby proposing a way of curating a collection of OoD data for subsequent analysis. Our proposed method leverages the recent advances in OoD segmentation and multi-modal foundation models to identify and efficiently extract safety-relevant scenes from unlabeled videos. We present a first approach for the novel task of text-based OoD object retrieval, which addresses the question ''Have we ever encountered this before?''.