 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining, Verifying, and Aligning Semantic Hierarchies in Vision-Language Model Embeddings
Mar 26, 2026Vision-language model (VLM) encoders such as CLIP enable strong retrieval and zero-shot classification in a shared image-text embedding space, yet the semantic organization of this space is rarely inspected. We present a post-hoc framework to explain, verify, and align the semantic hierarchies induced by a VLM over a given set of child classes. First, we extract a binary hierarchy by agglomerative clustering of class centroids and name internal nodes by dictionary-based matching to a concept bank. Second, we quantify plausibility by comparing the extracted tree against human ontologies using efficient tree- and edge-level consistency measures, and we evaluate utility via explainable hierarchical tree-traversal inference with uncertainty-aware early stopping (UAES). Third, we propose an ontology-guided post-hoc alignment method that learns a lightweight embedding-space transformation, using UMAP to generate target neighborhoods from a desired hierarchy. Across 13 pretrained VLMs and 4 image datasets, our method finds systematic modality differences: image encoders are more discriminative, while text encoders induce hierarchies that better match human taxonomies. Overall, the results reveal a persistent trade-off between zero-shot accuracy and ontological plausibility and suggest practical routes to improve semantic alignment in shared embedding spaces.
On Background Bias of Post-Hoc Concept Embeddings in Computer Vision DNNs
Apr 11, 2025The thriving research field of concept-based explainable artificial intelligence (C-XAI) investigates how human-interpretable semantic concepts embed in the latent spaces of deep neural networks (DNNs). Post-hoc approaches therein use a set of examples to specify a concept, and determine its embeddings in DNN latent space using data driven techniques. This proved useful to uncover biases between different target (foreground or concept) classes. However, given that the background is mostly uncontrolled during training, an important question has been left unattended so far: Are/to what extent are state-of-the-art, data-driven post-hoc C-XAI approaches themselves prone to biases with respect to their backgrounds? E.g., wild animals mostly occur against vegetation backgrounds, and they seldom appear on roads. Even simple and robust C-XAI methods might abuse this shortcut for enhanced performance. A dangerous performance degradation of the concept-corner cases of animals on the road could thus remain undiscovered. This work validates and thoroughly confirms that established Net2Vec-based concept segmentation techniques frequently capture background biases, including alarming ones, such as underperformance on road scenes. For the analysis, we compare 3 established techniques from the domain of background randomization on >50 concepts from 2 datasets, and 7 diverse DNN architectures. Our results indicate that even low-cost setups can provide both valuable insight and improved background robustness.
Benchmarking Vision Foundation Models for Input Monitoring in Autonomous Driving
Jan 14, 2025Deep neural networks (DNNs) remain challenged by distribution shifts in complex open-world domains like automated driving (AD): Absolute robustness against yet unknown novel objects (semantic shift) or styles like lighting conditions (covariate shift) cannot be guaranteed. Hence, reliable operation-time monitors for identification of out-of-training-data-distribution (OOD) scenarios are imperative. Current approaches for OOD classification are untested for complex domains like AD, are limited in the kinds of shifts they detect, or even require supervision with OOD samples. To prepare for unanticipated shifts, we instead establish a framework around a principled, unsupervised, and model-agnostic method that unifies detection of all kinds of shifts: Find a full model of the training data's feature distribution, to then use its density at new points as in-distribution (ID) score. To implement this, we propose to combine the newly available Vision Foundation Models (VFM) as feature extractors with one of four alternative density modeling techniques. In an extensive benchmark of 4 VFMs against 20 baselines, we show the superior performance of VFM feature encodings compared to shift-specific OOD monitors. Additionally, we find that sophisticated architectures outperform larger latent space dimensionality; and our method identifies samples with higher risk of errors on downstream tasks, despite being model-agnostic. This suggests that VFMs are promising to realize model-agnostic, unsupervised, reliable safety monitors in complex vision tasks.
Unveiling Ontological Commitment in Multi-Modal Foundation Models
Sep 25, 2024



Ontological commitment, i.e., used concepts, relations, and assumptions, are a corner stone of qualitative reasoning (QR) models. The state-of-the-art for processing raw inputs, though, are deep neural networks (DNNs), nowadays often based off from multimodal foundation models. These automatically learn rich representations of concepts and respective reasoning. Unfortunately, the learned qualitative knowledge is opaque, preventing easy inspection, validation, or adaptation against available QR models. So far, it is possible to associate pre-defined concepts with latent representations of DNNs, but extractable relations are mostly limited to semantic similarity. As a next step towards QR for validation and verification of DNNs: Concretely, we propose a method that extracts the learned superclass hierarchy from a multimodal DNN for a given set of leaf concepts. Under the hood we (1) obtain leaf concept embeddings using the DNN's textual input modality; (2) apply hierarchical clustering to them, using that DNNs encode semantic similarities via vector distances; and (3) label the such-obtained parent concepts using search in available ontologies from QR. An initial evaluation study shows that meaningful ontological class hierarchies can be extracted from state-of-the-art foundation models. Furthermore, we demonstrate how to validate and verify a DNN's learned representations against given ontologies. Lastly, we discuss potential future applications in the context of QR.
Investigating Calibration and Corruption Robustness of Post-hoc Pruned Perception CNNs: An Image Classification Benchmark Study
May 31, 2024


Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance in many computer vision tasks. However, high computational and storage demands hinder their deployment into resource-constrained environments, such as embedded devices. Model pruning helps to meet these restrictions by reducing the model size, while maintaining superior performance. Meanwhile, safety-critical applications pose more than just resource and performance constraints. In particular, predictions must not be overly confident, i.e., provide properly calibrated uncertainty estimations (proper uncertainty calibration), and CNNs must be robust against corruptions like naturally occurring input perturbations (natural corruption robustness). This work investigates the important trade-off between uncertainty calibration, natural corruption robustness, and performance for current state-of-research post-hoc CNN pruning techniques in the context of image classification tasks. Our study reveals that post-hoc pruning substantially improves the model's uncertainty calibration, performance, and natural corruption robustness, sparking hope for safe and robust embedded CNNs.Furthermore, uncertainty calibration and natural corruption robustness are not mutually exclusive targets under pruning, as evidenced by the improved safety aspects obtained by post-hoc unstructured pruning with increasing compression.
The Anatomy of Adversarial Attacks: Concept-based XAI Dissection
Mar 25, 2024Adversarial attacks (AAs) pose a significant threat to the reliability and robustness of deep neural networks. While the impact of these attacks on model predictions has been extensively studied, their effect on the learned representations and concepts within these models remains largely unexplored. In this work, we perform an in-depth analysis of the influence of AAs on the concepts learned by convolutional neural networks (CNNs) using eXplainable artificial intelligence (XAI) techniques. Through an extensive set of experiments across various network architectures and targeted AA techniques, we unveil several key findings. First, AAs induce substantial alterations in the concept composition within the feature space, introducing new concepts or modifying existing ones. Second, the adversarial perturbation itself can be linearly decomposed into a set of latent vector components, with a subset of these being responsible for the attack's success. Notably, we discover that these components are target-specific, i.e., are similar for a given target class throughout different AA techniques and starting classes. Our findings provide valuable insights into the nature of AAs and their impact on learned representations, paving the way for the development of more robust and interpretable deep learning models, as well as effective defenses against adversarial threats.
GCPV: Guided Concept Projection Vectors for the Explainable Inspection of CNN Feature Spaces
Nov 24, 2023



For debugging and verification of computer vision convolutional deep neural networks (CNNs) human inspection of the learned latent representations is imperative. Therefore, state-of-the-art eXplainable Artificial Intelligence (XAI) methods globally associate given natural language semantic concepts with representing vectors or regions in the CNN latent space supporting manual inspection. Yet, this approach comes with two major disadvantages: They are locally inaccurate when reconstructing a concept label and discard information about the distribution of concept instance representations. The latter, though, is of particular interest for debugging, like finding and understanding outliers, learned notions of sub-concepts, and concept confusion. Furthermore, current single-layer approaches neglect that information about a concept may be spread over the CNN depth. To overcome these shortcomings, we introduce the local-to-global Guided Concept Projection Vectors (GCPV) approach: It (1) generates local concept vectors that each precisely reconstruct a concept segmentation label, and then (2) generalizes these to global concept and even sub-concept vectors by means of hiearchical clustering. Our experiments on object detectors demonstrate improved performance compared to the state-of-the-art, the benefit of multi-layer concept vectors, and robustness against low-quality concept segmentation labels. Finally, we demonstrate that GCPVs can be applied to find root causes for confusion of concepts like bus and truck, and reveal interesting concept-level outliers. Thus, GCPVs pose a promising step towards interpretable model debugging and informed data improvement.
Have We Ever Encountered This Before? Retrieving Out-of-Distribution Road Obstacles from Driving Scenes
Sep 08, 2023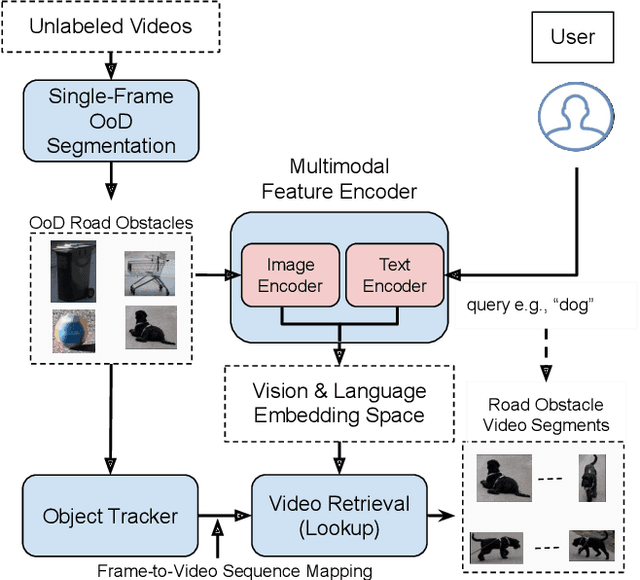
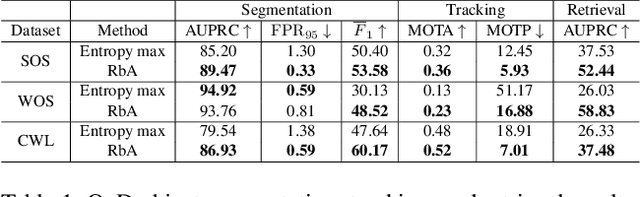
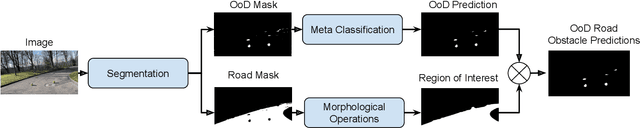
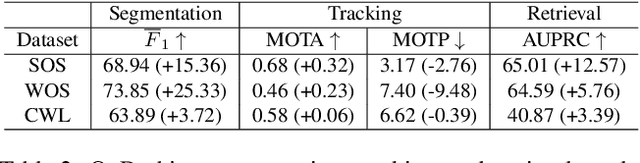
In the life cycle of highly automated systems operating in an open and dynamic environment, the ability to adjust to emerging challenges is crucial. For systems integrating data-driven AI-based components, rapid responses to deployment issues require fast access to related data for testing and reconfiguration. In the context of automated driving, this especially applies to road obstacles that were not included in the training data, commonly referred to as out-of-distribution (OoD) road obstacles. Given the availability of large uncurated recordings of driving scenes, a pragmatic approach is to query a database to retrieve similar scenarios featuring the same safety concerns due to OoD road obstacles. In this work, we extend beyond identifying OoD road obstacles in video streams and offer a comprehensive approach to extract sequences of OoD road obstacles using text queries, thereby proposing a way of curating a collection of OoD data for subsequent analysis. Our proposed method leverages the recent advances in OoD segmentation and multi-modal foundation models to identify and efficiently extract safety-relevant scenes from unlabeled videos. We present a first approach for the novel task of text-based OoD object retrieval, which addresses the question ''Have we ever encountered this before?''.
Quantified Semantic Comparison of Convolutional Neural Networks
Apr 30, 2023



The state-of-the-art in convolutional neural networks (CNNs) for computer vision excels in performance, while remaining opaque. But due to safety regulations for safety-critical applications, like perception for automated driving, the choice of model should also take into account how candidate models represent semantic information for model transparency reasons. To tackle this yet unsolved problem, our work proposes two methods for quantifying the similarity between semantic information in CNN latent spaces. These allow insights into both the flow and similarity of semantic information within CNN layers, and into the degree of their similitude between different networks. As a basis, we use renown techniques from the field of explainable artificial intelligence (XAI), which are used to obtain global vector representations of semantic concepts in each latent space. These are compared with respect to their activation on test inputs. When applied to three diverse object detectors and two datasets, our methods reveal the findings that (1) similar semantic concepts are learned \emph{regardless of the CNN architecture}, and (2) similar concepts emerge in similar \emph{relative} layer depth, independent of the total number of layers. Finally, our approach poses a promising step towards informed model selection and comprehension of how CNNs process semantic information.
Evaluating the Stability of Semantic Concept Representations in CNNs for Robust Explainability
Apr 28, 2023



Analysis of how semantic concepts are represented within Convolutional Neural Networks (CNNs) is a widely used approach in Explainable Artificial Intelligence (XAI) for interpreting CNNs. A motivation is the need for transparency in safety-critical AI-based systems, as mandated in various domains like automated driving. However, to use the concept representations for safety-relevant purposes, like inspection or error retrieval, these must be of high quality and, in particular, stable. This paper focuses on two stability goals when working with concept representations in computer vision CNNs: stability of concept retrieval and of concept attribution. The guiding use-case is a post-hoc explainability framework for object detection (OD) CNNs, towards which existing concept analysis (CA) methods are successfully adapted. To address concept retrieval stability, we propose a novel metric that considers both concept separation and consistency, and is agnostic to layer and concept representation dimensionality. We then investigate impacts of concept abstraction level, number of concept training samples, CNN size, and concept representation dimensionality on stability. For concept attribution stability we explore the effect of gradient instability on gradient-based explainability methods. The results on various CNNs for classification and object detection yield the main findings that (1) the stability of concept retrieval can be enhanced through dimensionality reduction via data aggregation, and (2) in shallow layers where gradient instability is more pronounced, gradient smoothing techniques are advised. Finally, our approach provides valuable insights into selecting the appropriate layer and concept representation dimensionality, paving the way towards CA in safety-critical XAI applications.