 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Background Bias of Post-Hoc Concept Embeddings in Computer Vision DNNs
Apr 11, 2025The thriving research field of concept-based explainable artificial intelligence (C-XAI) investigates how human-interpretable semantic concepts embed in the latent spaces of deep neural networks (DNNs). Post-hoc approaches therein use a set of examples to specify a concept, and determine its embeddings in DNN latent space using data driven techniques. This proved useful to uncover biases between different target (foreground or concept) classes. However, given that the background is mostly uncontrolled during training, an important question has been left unattended so far: Are/to what extent are state-of-the-art, data-driven post-hoc C-XAI approaches themselves prone to biases with respect to their backgrounds? E.g., wild animals mostly occur against vegetation backgrounds, and they seldom appear on roads. Even simple and robust C-XAI methods might abuse this shortcut for enhanced performance. A dangerous performance degradation of the concept-corner cases of animals on the road could thus remain undiscovered. This work validates and thoroughly confirms that established Net2Vec-based concept segmentation techniques frequently capture background biases, including alarming ones, such as underperformance on road scenes. For the analysis, we compare 3 established techniques from the domain of background randomization on >50 concepts from 2 datasets, and 7 diverse DNN architectures. Our results indicate that even low-cost setups can provide both valuable insight and improved background robustness.
Unveiling Ontological Commitment in Multi-Modal Foundation Models
Sep 25, 2024



Ontological commitment, i.e., used concepts, relations, and assumptions, are a corner stone of qualitative reasoning (QR) models. The state-of-the-art for processing raw inputs, though, are deep neural networks (DNNs), nowadays often based off from multimodal foundation models. These automatically learn rich representations of concepts and respective reasoning. Unfortunately, the learned qualitative knowledge is opaque, preventing easy inspection, validation, or adaptation against available QR models. So far, it is possible to associate pre-defined concepts with latent representations of DNNs, but extractable relations are mostly limited to semantic similarity. As a next step towards QR for validation and verification of DNNs: Concretely, we propose a method that extracts the learned superclass hierarchy from a multimodal DNN for a given set of leaf concepts. Under the hood we (1) obtain leaf concept embeddings using the DNN's textual input modality; (2) apply hierarchical clustering to them, using that DNNs encode semantic similarities via vector distances; and (3) label the such-obtained parent concepts using search in available ontologies from QR. An initial evaluation study shows that meaningful ontological class hierarchies can be extracted from state-of-the-art foundation models. Furthermore, we demonstrate how to validate and verify a DNN's learned representations against given ontologies. Lastly, we discuss potential future applications in the context of QR.
How Could Generative AI Support Compliance with the EU AI Act? A Review for Safe Automated Driving Perception
Aug 30, 2024



Deep Neural Networks (DNNs) have become central for the perception functions of autonomous vehicles, substantially enhancing their ability to understand and interpret the environment. However, these systems exhibit inherent limitations such as brittleness, opacity, and unpredictable behavior in out-of-distribution scenarios. The European Union (EU) Artificial Intelligence (AI) Act, as a pioneering legislative framework, aims to address these challenges by establishing stringent norms and standards for AI systems, including those used in autonomous driving (AD), which are categorized as high-risk AI. In this work, we explore how the newly available generative AI models can potentially support addressing upcoming regulatory requirements in AD perception, particularly with respect to safety. This short review paper summarizes the requirements arising from the EU AI Act regarding DNN-based perception systems and systematically categorizes existing generative AI applications in AD. While generative AI models show promise in addressing some of the EU AI Acts requirements, such as transparency and robustness, this review examines their potential benefits and discusses how developers could leverage these methods to enhance compliance with the Act. The paper also highlights areas where further research is needed to ensure reliable and safe integration of these technologies.
Content Disentanglement for Semantically Consistent Synthetic-to-Real Domain Adaptation
May 27, 2021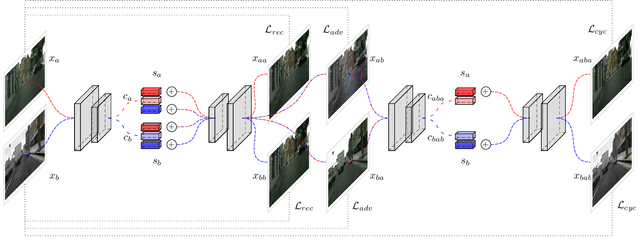



Synthetic data generation is an appealing approach to generate novel traffic scenarios in autonomous driving. However, deep learning techniques trained solely on synthetic data encounter dramatic performance drops when they are tested on real data. Such performance drop is commonly attributed to the domain gap between real and synthetic data. Domain adaptation methods have been applied to mitigate the aforementioned domain gap. These methods achieve visually appealing results, but the translated samples usually introduce semantic inconsistencies. In this work, we propose a new, unsupervised, end-to-end domain adaptation network architecture that enables semantically consistent domain adaptation between synthetic and real data. We evaluate our architecture on the downstream task of semantic segmentation and show that our method achieves superior performance compared to the state-of-the-art methods.