 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture-Shape Bias Balancing for Robust Synthetic-to-Real Semantic Segmentation in Automotive NIR Imagery
Jun 13, 2026Semantic segmentation is a fundamental component of visual perception in modern automotive systems, enabling pixel-level scene understanding. Near-Infrared imaging (NIR) offers stable detection under difficult illumination conditions, but the development of domain-specific semantic segmentation models remains challenging due to the lack of high-quality annotated data from real-world scenarios. Synthetic datasets offer a scalable alternative, but models trained on synthetic images often suffer performance degradation when transferred to real domains. We present the first systematic study on synthetic to real domain adaptation for semantic segmentation in NIR images in the automotive domain. We propose a generative augmentation framework that transforms synthetic images into realistic NIR-style variants via our introduced target style adaptation (TSA). TSA fine-tunes a latent diffusion model via low-rank adaptation on a small curated set of real NIR images and applies it to synthetic training data using structure-preserving multi-signal conditioning. To reduce texture bias and improve segmentation robustness, we further apply a Voronoi-based style diversification strategy (VSD) that modifies the original textures while preserving scene geometry. Experiments with multiple model architectures on NIR data from vehicle interiors and street scenes show that balancing inductive bias during training leads to noticeably more robust semantic segmentation and effectively reduces the domain gap in our real-world scenarios by up to 63.6% on exterior and 28.4% on interior data. The code is available at GitHub.
Explaining, Verifying, and Aligning Semantic Hierarchies in Vision-Language Model Embeddings
Mar 26, 2026Vision-language model (VLM) encoders such as CLIP enable strong retrieval and zero-shot classification in a shared image-text embedding space, yet the semantic organization of this space is rarely inspected. We present a post-hoc framework to explain, verify, and align the semantic hierarchies induced by a VLM over a given set of child classes. First, we extract a binary hierarchy by agglomerative clustering of class centroids and name internal nodes by dictionary-based matching to a concept bank. Second, we quantify plausibility by comparing the extracted tree against human ontologies using efficient tree- and edge-level consistency measures, and we evaluate utility via explainable hierarchical tree-traversal inference with uncertainty-aware early stopping (UAES). Third, we propose an ontology-guided post-hoc alignment method that learns a lightweight embedding-space transformation, using UMAP to generate target neighborhoods from a desired hierarchy. Across 13 pretrained VLMs and 4 image datasets, our method finds systematic modality differences: image encoders are more discriminative, while text encoders induce hierarchies that better match human taxonomies. Overall, the results reveal a persistent trade-off between zero-shot accuracy and ontological plausibility and suggest practical routes to improve semantic alignment in shared embedding spaces.
Out-of-Distribution Object Detection in Street Scenes via Synthetic Outlier Exposure and Transfer Learning
Mar 17, 2026Out-of-distribution (OOD) object detection is an important yet underexplored task. A reliable object detector should be able to handle OOD objects by localizing and correctly classifying them as OOD. However, a critical issue arises when such atypical objects are completely missed by the object detector and incorrectly treated as background. Existing OOD detection approaches in object detection often rely on complex architectures or auxiliary branches and typically do not provide a framework that treats in-distribution (ID) and OOD in a unified way. In this work, we address these limitations by enabling a single detector to detect OOD objects, that are otherwise silently overlooked, alongside ID objects. We present \textbf{SynOE-OD}, a \textbf{Syn}thetic \textbf{O}utlier-\textbf{E}xposure-based \textbf{O}bject \textbf{D}etection framework, that leverages strong generative models, like Stable Diffusion, and Open-Vocabulary Object Detectors (OVODs) to generate semantically meaningful, object-level data that serve as outliers during training. The generated data is used for transfer-learning to establish strong ID task performance and supplement detection models with OOD object detection robustness. Our approach achieves state-of-the-art average precision on an established OOD object detection benchmark, where OVODs, such as GroundingDINO, show limited zero-shot performance in detecting OOD objects in street-scenes.
Learning Brenier Potentials with Convex Generative Adversarial Neural Networks
Apr 28, 2025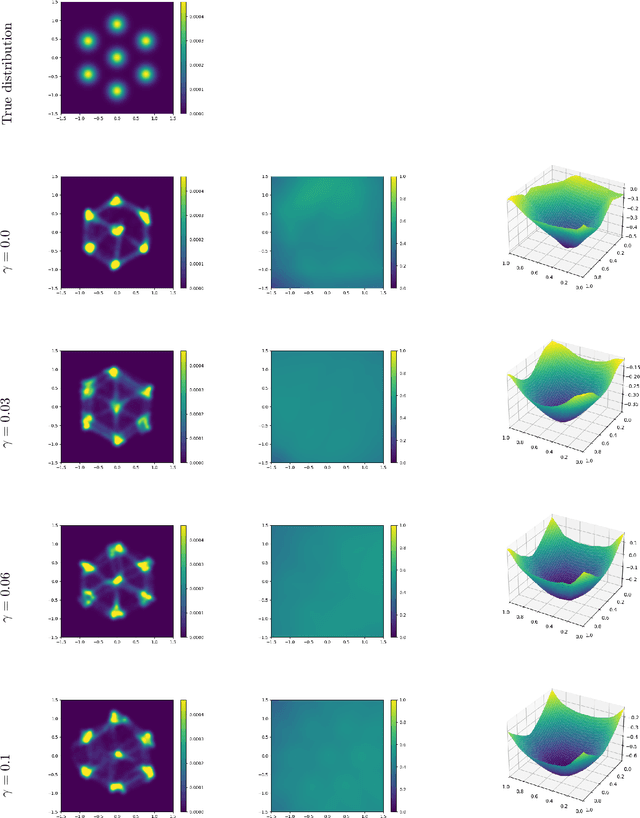


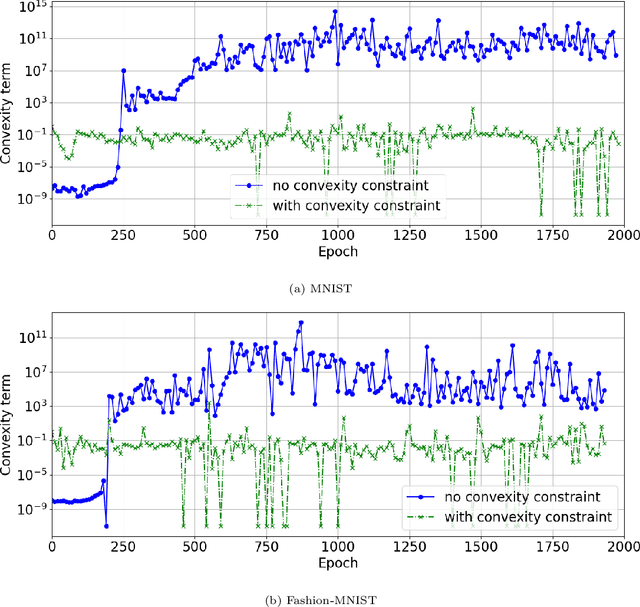
Brenier proved that under certain conditions on a source and a target probability measure there exists a strictly convex function such that its gradient is a transport map from the source to the target distribution. This function is called the Brenier potential. Furthermore, detailed information on the H\"older regularity of the Brenier potential is available. In this work we develop the statistical learning theory of generative adversarial neural networks that learn the Brenier potential. As by the transformation of densities formula, the density of the generated measure depends on the second derivative of the Brenier potential, we develop the universal approximation theory of ReCU networks with cubic activation $\mathtt{ReCU}(x)=\max\{0,x\}^3$ that combines the favorable approximation properties of H\"older functions with a Lipschitz continuous density. In order to assure the convexity of such general networks, we introduce an adversarial training procedure for a potential function represented by the ReCU networks that combines the classical discriminator cross entropy loss with a penalty term that enforces (strict) convexity. We give a detailed decomposition of learning errors and show that for a suitable high penalty parameter all networks chosen in the adversarial min-max optimization problem are strictly convex. This is further exploited to prove the consistency of the learning procedure for (slowly) expanding network capacity. We also implement the described learning algorithm and apply it to a number of standard test cases from Gaussian mixture to image data as target distributions. As predicted in theory, we observe that the convexity loss becomes inactive during the training process and the potentials represented by the neural networks have learned convexity.
On Background Bias of Post-Hoc Concept Embeddings in Computer Vision DNNs
Apr 11, 2025The thriving research field of concept-based explainable artificial intelligence (C-XAI) investigates how human-interpretable semantic concepts embed in the latent spaces of deep neural networks (DNNs). Post-hoc approaches therein use a set of examples to specify a concept, and determine its embeddings in DNN latent space using data driven techniques. This proved useful to uncover biases between different target (foreground or concept) classes. However, given that the background is mostly uncontrolled during training, an important question has been left unattended so far: Are/to what extent are state-of-the-art, data-driven post-hoc C-XAI approaches themselves prone to biases with respect to their backgrounds? E.g., wild animals mostly occur against vegetation backgrounds, and they seldom appear on roads. Even simple and robust C-XAI methods might abuse this shortcut for enhanced performance. A dangerous performance degradation of the concept-corner cases of animals on the road could thus remain undiscovered. This work validates and thoroughly confirms that established Net2Vec-based concept segmentation techniques frequently capture background biases, including alarming ones, such as underperformance on road scenes. For the analysis, we compare 3 established techniques from the domain of background randomization on >50 concepts from 2 datasets, and 7 diverse DNN architectures. Our results indicate that even low-cost setups can provide both valuable insight and improved background robustness.
Shape Bias and Robustness Evaluation via Cue Decomposition for Image Classification and Segmentation
Mar 16, 2025



Previous works studied how deep neural networks (DNNs) perceive image content in terms of their biases towards different image cues, such as texture and shape. Previous methods to measure shape and texture biases are typically style-transfer-based and limited to DNNs for image classification. In this work, we provide a new evaluation procedure consisting of 1) a cue-decomposition method that comprises two AI-free data pre-processing methods extracting shape and texture cues, respectively, and 2) a novel cue-decomposition shape bias evaluation metric that leverages the cue-decomposition data. For application purposes we introduce a corresponding cue-decomposition robustness metric that allows for the estimation of the robustness of a DNN w.r.t. image corruptions. In our numerical experiments, our findings for biases in image classification DNNs align with those of previous evaluation metrics. However, our cue-decomposition robustness metric shows superior results in terms of estimating the robustness of DNNs. Furthermore, our results for DNNs on the semantic segmentation datasets Cityscapes and ADE20k for the first time shed light into the biases of semantic segmentation DNNs.
Does Knowledge About Perceptual Uncertainty Help an Agent in Automated Driving?
Feb 17, 2025Agents in real-world scenarios like automated driving deal with uncertainty in their environment, in particular due to perceptual uncertainty. Although, reinforcement learning is dedicated to autonomous decision-making under uncertainty these algorithms are typically not informed about the uncertainty currently contained in their environment. On the other hand, uncertainty estimation for perception itself is typically directly evaluated in the perception domain, e.g., in terms of false positive detection rates or calibration errors based on camera images. Its use for deciding on goal-oriented actions remains largely unstudied. In this paper, we investigate how an agent's behavior is influenced by an uncertain perception and how this behavior changes if information about this uncertainty is available. Therefore, we consider a proxy task, where the agent is rewarded for driving a route as fast as possible without colliding with other road users. For controlled experiments, we introduce uncertainty in the observation space by perturbing the perception of the given agent while informing the latter. Our experiments show that an unreliable observation space modeled by a perturbed perception leads to a defensive driving behavior of the agent. Furthermore, when adding the information about the current uncertainty directly to the observation space, the agent adapts to the specific situation and in general accomplishes its task faster while, at the same time, accounting for risks.
On the Influence of Shape, Texture and Color for Learning Semantic Segmentation
Oct 18, 2024



In recent years, a body of works has emerged, studying shape and texture biases of off-the-shelf pre-trained deep neural networks (DNN) for image classification. These works study how much a trained DNN relies on image cues, predominantly shape and texture. In this work, we switch the perspective, posing the following questions: What can a DNN learn from each of the image cues, i.e., shape, texture and color, respectively? How much does each cue influence the learning success? And what are the synergy effects between different cues? Studying these questions sheds light upon cue influences on learning and thus the learning capabilities of DNNs. We study these questions on semantic segmentation which allows us to address our questions on pixel level. To conduct this study, we develop a generic procedure to decompose a given dataset into multiple ones, each of them only containing either a single cue or a chosen mixture. This framework is then applied to two real-world datasets, Cityscapes and PASCAL Context, and a synthetic data set based on the CARLA simulator. We learn the given semantic segmentation task from these cue datasets, creating cue experts. Early fusion of cues is performed by constructing appropriate datasets. This is complemented by a late fusion of experts which allows us to study cue influence location-dependent on pixel level. Our study on three datasets reveals that neither texture nor shape clearly dominate the learning success, however a combination of shape and color but without texture achieves surprisingly strong results. Our findings hold for convolutional and transformer backbones. In particular, qualitatively there is almost no difference in how both of the architecture types extract information from the different cues.
Semi-supervised domain adaptation with CycleGAN guided by a downstream task loss
Aug 18, 2022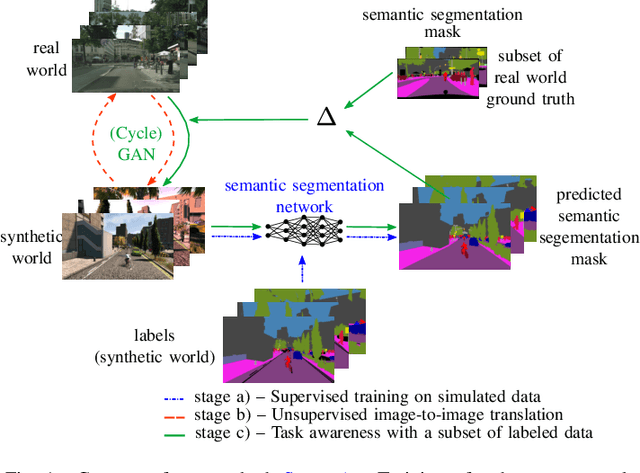
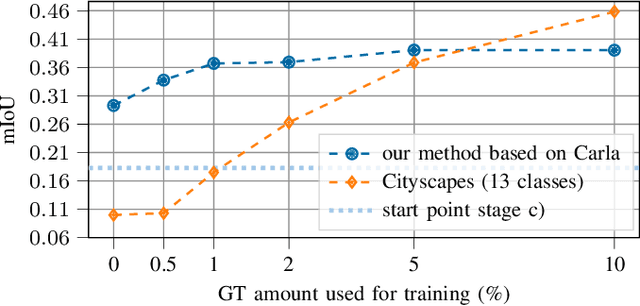


Domain adaptation is of huge interest as labeling is an expensive and error-prone task, especially when labels are needed on pixel-level like in semantic segmentation. Therefore, one would like to be able to train neural networks on synthetic domains, where data is abundant and labels are precise. However, these models often perform poorly on out-of-domain images. To mitigate the shift in the input, image-to-image approaches can be used. Nevertheless, standard image-to-image approaches that bridge the domain of deployment with the synthetic training domain do not focus on the downstream task but only on the visual inspection level. We therefore propose a "task aware" version of a GAN in an image-to-image domain adaptation approach. With the help of a small amount of labeled ground truth data, we guide the image-to-image translation to a more suitable input image for a semantic segmentation network trained on synthetic data (synthetic-domain expert). The main contributions of this work are 1) a modular semi-supervised domain adaptation method for semantic segmentation by training a downstream task aware CycleGAN while refraining from adapting the synthetic semantic segmentation expert 2) the demonstration that the method is applicable to complex domain adaptation tasks and 3) a less biased domain gap analysis by using from scratch networks. We evaluate our method on a classification task as well as on semantic segmentation. Our experiments demonstrate that our method outperforms CycleGAN - a standard image-to-image approach - by 7 percent points in accuracy in a classification task using only 70 (10%) ground truth images. For semantic segmentation we can show an improvement of about 4 to 7 percent points in mean Intersection over union on the Cityscapes evaluation dataset with only 14 ground truth images during training.