 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Background Bias of Post-Hoc Concept Embeddings in Computer Vision DNNs
Apr 11, 2025The thriving research field of concept-based explainable artificial intelligence (C-XAI) investigates how human-interpretable semantic concepts embed in the latent spaces of deep neural networks (DNNs). Post-hoc approaches therein use a set of examples to specify a concept, and determine its embeddings in DNN latent space using data driven techniques. This proved useful to uncover biases between different target (foreground or concept) classes. However, given that the background is mostly uncontrolled during training, an important question has been left unattended so far: Are/to what extent are state-of-the-art, data-driven post-hoc C-XAI approaches themselves prone to biases with respect to their backgrounds? E.g., wild animals mostly occur against vegetation backgrounds, and they seldom appear on roads. Even simple and robust C-XAI methods might abuse this shortcut for enhanced performance. A dangerous performance degradation of the concept-corner cases of animals on the road could thus remain undiscovered. This work validates and thoroughly confirms that established Net2Vec-based concept segmentation techniques frequently capture background biases, including alarming ones, such as underperformance on road scenes. For the analysis, we compare 3 established techniques from the domain of background randomization on >50 concepts from 2 datasets, and 7 diverse DNN architectures. Our results indicate that even low-cost setups can provide both valuable insight and improved background robustness.
Locally Testing Model Detections for Semantic Global Concepts
May 29, 2024Ensuring the quality of black-box Deep Neural Networks (DNNs) has become ever more significant, especially in safety-critical domains such as automated driving. While global concept encodings generally enable a user to test a model for a specific concept, linking global concept encodings to the local processing of single network inputs reveals their strengths and limitations. Our proposed framework global-to-local Concept Attribution (glCA) uses approaches from local (why a specific prediction originates) and global (how a model works generally) eXplainable Artificial Intelligence (xAI) to test DNNs for a predefined semantical concept locally. The approach allows for conditioning local, post-hoc explanations on predefined semantic concepts encoded as linear directions in the model's latent space. Pixel-exact scoring concerning the global concept usage assists the tester in further understanding the model processing of single data points for the selected concept. Our approach has the advantage of fully covering the model-internal encoding of the semantic concept and allowing the localization of relevant concept-related information. The results show major differences in the local perception and usage of individual global concept encodings and demand for further investigations regarding obtaining thorough semantic concept encodings.
The Anatomy of Adversarial Attacks: Concept-based XAI Dissection
Mar 25, 2024Adversarial attacks (AAs) pose a significant threat to the reliability and robustness of deep neural networks. While the impact of these attacks on model predictions has been extensively studied, their effect on the learned representations and concepts within these models remains largely unexplored. In this work, we perform an in-depth analysis of the influence of AAs on the concepts learned by convolutional neural networks (CNNs) using eXplainable artificial intelligence (XAI) techniques. Through an extensive set of experiments across various network architectures and targeted AA techniques, we unveil several key findings. First, AAs induce substantial alterations in the concept composition within the feature space, introducing new concepts or modifying existing ones. Second, the adversarial perturbation itself can be linearly decomposed into a set of latent vector components, with a subset of these being responsible for the attack's success. Notably, we discover that these components are target-specific, i.e., are similar for a given target class throughout different AA techniques and starting classes. Our findings provide valuable insights into the nature of AAs and their impact on learned representations, paving the way for the development of more robust and interpretable deep learning models, as well as effective defenses against adversarial threats.
GCPV: Guided Concept Projection Vectors for the Explainable Inspection of CNN Feature Spaces
Nov 24, 2023



For debugging and verification of computer vision convolutional deep neural networks (CNNs) human inspection of the learned latent representations is imperative. Therefore, state-of-the-art eXplainable Artificial Intelligence (XAI) methods globally associate given natural language semantic concepts with representing vectors or regions in the CNN latent space supporting manual inspection. Yet, this approach comes with two major disadvantages: They are locally inaccurate when reconstructing a concept label and discard information about the distribution of concept instance representations. The latter, though, is of particular interest for debugging, like finding and understanding outliers, learned notions of sub-concepts, and concept confusion. Furthermore, current single-layer approaches neglect that information about a concept may be spread over the CNN depth. To overcome these shortcomings, we introduce the local-to-global Guided Concept Projection Vectors (GCPV) approach: It (1) generates local concept vectors that each precisely reconstruct a concept segmentation label, and then (2) generalizes these to global concept and even sub-concept vectors by means of hiearchical clustering. Our experiments on object detectors demonstrate improved performance compared to the state-of-the-art, the benefit of multi-layer concept vectors, and robustness against low-quality concept segmentation labels. Finally, we demonstrate that GCPVs can be applied to find root causes for confusion of concepts like bus and truck, and reveal interesting concept-level outliers. Thus, GCPVs pose a promising step towards interpretable model debugging and informed data improvement.
Quantified Semantic Comparison of Convolutional Neural Networks
Apr 30, 2023



The state-of-the-art in convolutional neural networks (CNNs) for computer vision excels in performance, while remaining opaque. But due to safety regulations for safety-critical applications, like perception for automated driving, the choice of model should also take into account how candidate models represent semantic information for model transparency reasons. To tackle this yet unsolved problem, our work proposes two methods for quantifying the similarity between semantic information in CNN latent spaces. These allow insights into both the flow and similarity of semantic information within CNN layers, and into the degree of their similitude between different networks. As a basis, we use renown techniques from the field of explainable artificial intelligence (XAI), which are used to obtain global vector representations of semantic concepts in each latent space. These are compared with respect to their activation on test inputs. When applied to three diverse object detectors and two datasets, our methods reveal the findings that (1) similar semantic concepts are learned \emph{regardless of the CNN architecture}, and (2) similar concepts emerge in similar \emph{relative} layer depth, independent of the total number of layers. Finally, our approach poses a promising step towards informed model selection and comprehension of how CNNs process semantic information.
Evaluating the Stability of Semantic Concept Representations in CNNs for Robust Explainability
Apr 28, 2023



Analysis of how semantic concepts are represented within Convolutional Neural Networks (CNNs) is a widely used approach in Explainable Artificial Intelligence (XAI) for interpreting CNNs. A motivation is the need for transparency in safety-critical AI-based systems, as mandated in various domains like automated driving. However, to use the concept representations for safety-relevant purposes, like inspection or error retrieval, these must be of high quality and, in particular, stable. This paper focuses on two stability goals when working with concept representations in computer vision CNNs: stability of concept retrieval and of concept attribution. The guiding use-case is a post-hoc explainability framework for object detection (OD) CNNs, towards which existing concept analysis (CA) methods are successfully adapted. To address concept retrieval stability, we propose a novel metric that considers both concept separation and consistency, and is agnostic to layer and concept representation dimensionality. We then investigate impacts of concept abstraction level, number of concept training samples, CNN size, and concept representation dimensionality on stability. For concept attribution stability we explore the effect of gradient instability on gradient-based explainability methods. The results on various CNNs for classification and object detection yield the main findings that (1) the stability of concept retrieval can be enhanced through dimensionality reduction via data aggregation, and (2) in shallow layers where gradient instability is more pronounced, gradient smoothing techniques are advised. Finally, our approach provides valuable insights into selecting the appropriate layer and concept representation dimensionality, paving the way towards CA in safety-critical XAI applications.
Unsupervised Contrastive Hashing for Cross-Modal Retrieval in Remote Sensing
Apr 19, 2022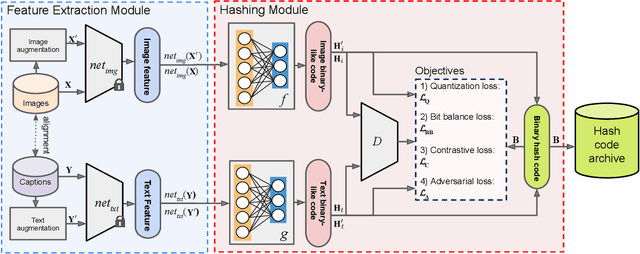
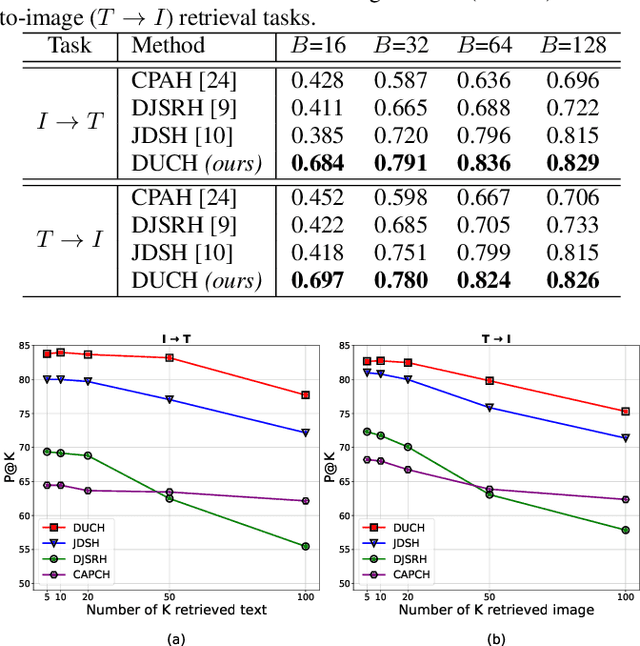

The development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in remote sensing (RS). In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems in RS require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel unsupervised cross-modal contrastive hashing (DUCH) method for text-image retrieval in RS. To this end, the proposed DUCH is made up of two main modules: 1) feature extraction module, which extracts deep representations of two modalities; 2) hashing module that learns to generate cross-modal binary hash codes from the extracted representations. We introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; and iii) binarization objectives for generating hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.
An Unsupervised Cross-Modal Hashing Method Robust to Noisy Training Image-Text Correspondences in Remote Sensing
Feb 26, 2022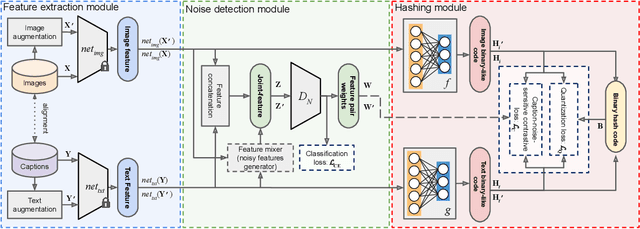
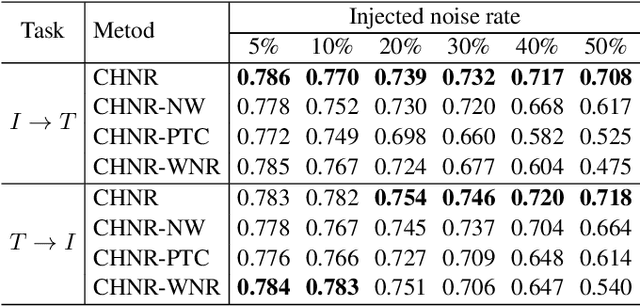
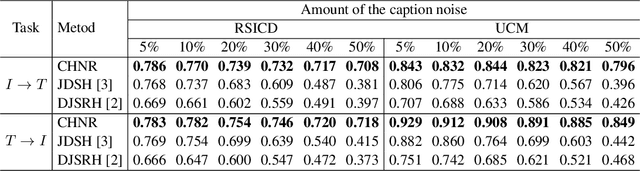
The development of accurate and scalable cross-modal image-text retrieval methods, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., remote sensing image) has attracted great attention in remote sensing (RS). Most of the existing methods assume that a reliable multi-modal training set with accurately matched text-image pairs is existing. However, this assumption may not always hold since the multi-modal training sets may include noisy pairs (i.e., textual descriptions/captions associated to training images can be noisy), distorting the learning process of the retrieval methods. To address this problem, we propose a novel unsupervised cross-modal hashing method robust to the noisy image-text correspondences (CHNR). CHNR consists of three modules: 1) feature extraction module, which extracts feature representations of image-text pairs; 2) noise detection module, which detects potential noisy correspondences; and 3) hashing module that generates cross-modal binary hash codes. The proposed CHNR includes two training phases: i) meta-learning phase that uses a small portion of clean (i.e., reliable) data to train the noise detection module in an adversarial fashion; and ii) the main training phase for which the trained noise detection module is used to identify noisy correspondences while the hashing module is trained on the noisy multi-modal training set. Experimental results show that the proposed CHNR outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/chnr
Deep Unsupervised Contrastive Hashing for Large-Scale Cross-Modal Text-Image Retrieval in Remote Sensing
Jan 20, 2022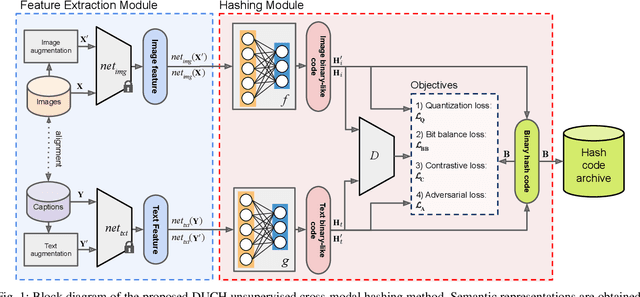
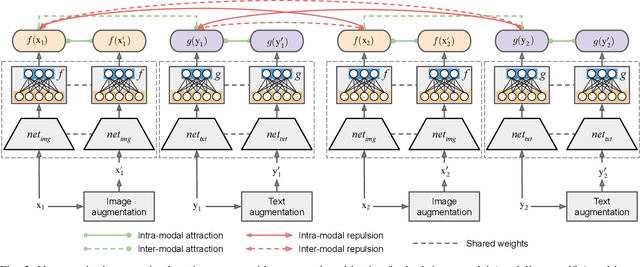

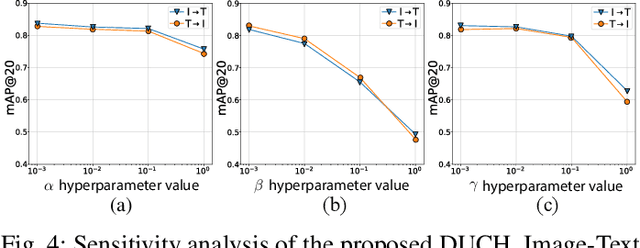
Due to the availability of large-scale multi-modal data (e.g., satellite images acquired by different sensors, text sentences, etc) archives, the development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in RS. In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval due to their intrinsic characteristics. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel deep unsupervised cross-modal contrastive hashing (DUCH) method for RS text-image retrieval. The proposed DUCH is made up of two main modules: 1) feature extraction module (which extracts deep representations of the text-image modalities); and 2) hashing module (which learns to generate cross-modal binary hash codes from the extracted representations). Within the hashing module, we introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in both intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; iii) binarization objectives for generating representative hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art unsupervised cross-modal hashing methods on two multi-modal (image and text) benchmark archives in RS. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.