 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLa-DCE -- Concept-guided Latent Diffusion Counterfactual Explanations
Jun 03, 2024



Recent advancements in generative AI have introduced novel prospects and practical implementations. Especially diffusion models show their strength in generating diverse and, at the same time, realistic features, positioning them well for generating counterfactual explanations for computer vision models. Answering "what if" questions of what needs to change to make an image classifier change its prediction, counterfactual explanations align well with human understanding and consequently help in making model behavior more comprehensible. Current methods succeed in generating authentic counterfactuals, but lack transparency as feature changes are not directly perceivable. To address this limitation, we introduce Concept-guided Latent Diffusion Counterfactual Explanations (CoLa-DCE). CoLa-DCE generates concept-guided counterfactuals for any classifier with a high degree of control regarding concept selection and spatial conditioning. The counterfactuals comprise an increased granularity through minimal feature changes. The reference feature visualization ensures better comprehensibility, while the feature localization provides increased transparency of "where" changed "what". We demonstrate the advantages of our approach in minimality and comprehensibility across multiple image classification models and datasets and provide insights into how our CoLa-DCE explanations help comprehend model errors like misclassification cases.
Locally Testing Model Detections for Semantic Global Concepts
May 29, 2024Ensuring the quality of black-box Deep Neural Networks (DNNs) has become ever more significant, especially in safety-critical domains such as automated driving. While global concept encodings generally enable a user to test a model for a specific concept, linking global concept encodings to the local processing of single network inputs reveals their strengths and limitations. Our proposed framework global-to-local Concept Attribution (glCA) uses approaches from local (why a specific prediction originates) and global (how a model works generally) eXplainable Artificial Intelligence (xAI) to test DNNs for a predefined semantical concept locally. The approach allows for conditioning local, post-hoc explanations on predefined semantic concepts encoded as linear directions in the model's latent space. Pixel-exact scoring concerning the global concept usage assists the tester in further understanding the model processing of single data points for the selected concept. Our approach has the advantage of fully covering the model-internal encoding of the semantic concept and allowing the localization of relevant concept-related information. The results show major differences in the local perception and usage of individual global concept encodings and demand for further investigations regarding obtaining thorough semantic concept encodings.
The Anatomy of Adversarial Attacks: Concept-based XAI Dissection
Mar 25, 2024Adversarial attacks (AAs) pose a significant threat to the reliability and robustness of deep neural networks. While the impact of these attacks on model predictions has been extensively studied, their effect on the learned representations and concepts within these models remains largely unexplored. In this work, we perform an in-depth analysis of the influence of AAs on the concepts learned by convolutional neural networks (CNNs) using eXplainable artificial intelligence (XAI) techniques. Through an extensive set of experiments across various network architectures and targeted AA techniques, we unveil several key findings. First, AAs induce substantial alterations in the concept composition within the feature space, introducing new concepts or modifying existing ones. Second, the adversarial perturbation itself can be linearly decomposed into a set of latent vector components, with a subset of these being responsible for the attack's success. Notably, we discover that these components are target-specific, i.e., are similar for a given target class throughout different AA techniques and starting classes. Our findings provide valuable insights into the nature of AAs and their impact on learned representations, paving the way for the development of more robust and interpretable deep learning models, as well as effective defenses against adversarial threats.
Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanations
Feb 14, 2022
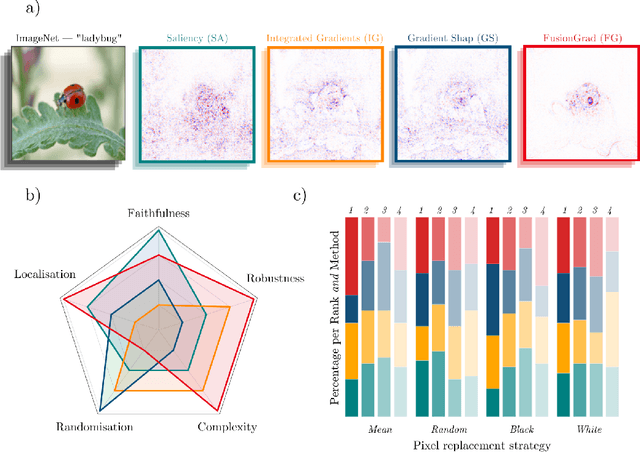
The evaluation of explanation methods is a research topic that has not yet been explored deeply, however, since explainability is supposed to strengthen trust in artificial intelligence, it is necessary to systematically review and compare explanation methods in order to confirm their correctness. Until now, no tool exists that exhaustively and speedily allows researchers to quantitatively evaluate explanations of neural network predictions. To increase transparency and reproducibility in the field, we therefore built Quantus - a comprehensive, open-source toolkit in Python that includes a growing, well-organised collection of evaluation metrics and tutorials for evaluating explainable methods. The toolkit has been thoroughly tested and is available under open source license on PyPi (or on https://github.com/understandable-machine-intelligence-lab/quantus/).
Measurably Stronger Explanation Reliability via Model Canonization
Feb 14, 2022
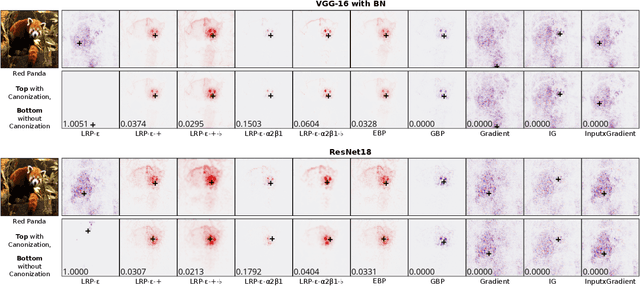

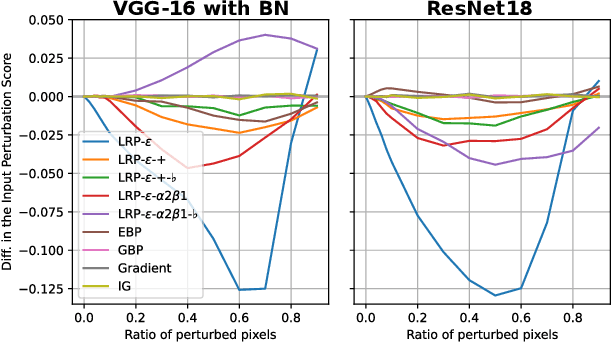
While rule-based attribution methods have proven useful for providing local explanations for Deep Neural Networks, explaining modern and more varied network architectures yields new challenges in generating trustworthy explanations, since the established rule sets might not be sufficient or applicable to novel network structures. As an elegant solution to the above issue, network canonization has recently been introduced. This procedure leverages the implementation-dependency of rule-based attributions and restructures a model into a functionally identical equivalent of alternative design to which established attribution rules can be applied. However, the idea of canonization and its usefulness have so far only been explored qualitatively. In this work, we quantitatively verify the beneficial effects of network canonization to rule-based attributions on VGG-16 and ResNet18 models with BatchNorm layers and thus extend the current best practices for obtaining reliable neural network explanations.