 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
Jun 18, 2025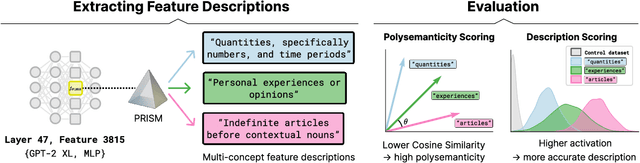

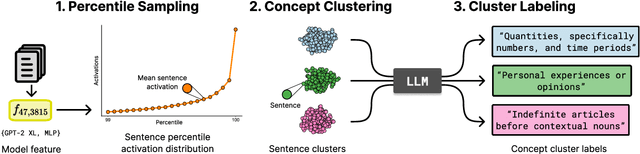

Automated interpretability research aims to identify concepts encoded in neural network features to enhance human understanding of model behavior. Current feature description methods face two critical challenges: limited robustness and the flawed assumption that each neuron encodes only a single concept (monosemanticity), despite growing evidence that neurons are often polysemantic. This assumption restricts the expressiveness of feature descriptions and limits their ability to capture the full range of behaviors encoded in model internals. To address this, we introduce Polysemantic FeatuRe Identification and Scoring Method (PRISM), a novel framework that captures the inherent complexity of neural network features. Unlike prior approaches that assign a single description per feature, PRISM provides more nuanced descriptions for both polysemantic and monosemantic features. We apply PRISM to language models and, through extensive benchmarking against existing methods, demonstrate that our approach produces more accurate and faithful feature descriptions, improving both overall description quality (via a description score) and the ability to capture distinct concepts when polysemanticity is present (via a polysemanticity score).
Evaluate with the Inverse: Efficient Approximation of Latent Explanation Quality Distribution
Feb 21, 2025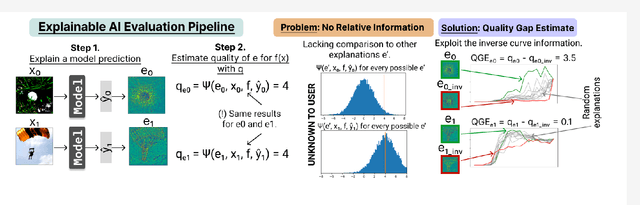



Obtaining high-quality explanations of a model's output enables developers to identify and correct biases, align the system's behavior with human values, and ensure ethical compliance. Explainable Artificial Intelligence (XAI) practitioners rely on specific measures to gauge the quality of such explanations. These measures assess key attributes, such as how closely an explanation aligns with a model's decision process (faithfulness), how accurately it pinpoints the relevant input features (localization), and its consistency across different cases (robustness). Despite providing valuable information, these measures do not fully address a critical practitioner's concern: how does the quality of a given explanation compare to other potential explanations? Traditionally, the quality of an explanation has been assessed by comparing it to a randomly generated counterpart. This paper introduces an alternative: the Quality Gap Estimate (QGE). The QGE method offers a direct comparison to what can be viewed as the `inverse' explanation, one that conceptually represents the antithesis of the original explanation. Our extensive testing across multiple model architectures, datasets, and established quality metrics demonstrates that the QGE method is superior to the traditional approach. Furthermore, we show that QGE enhances the statistical reliability of these quality assessments. This advance represents a significant step toward a more insightful evaluation of explanations that enables a more effective inspection of a model's behavior.
From Flexibility to Manipulation: The Slippery Slope of XAI Evaluation
Dec 07, 2024



The lack of ground truth explanation labels is a fundamental challenge for quantitative evaluation in explainable artificial intelligence (XAI). This challenge becomes especially problematic when evaluation methods have numerous hyperparameters that must be specified by the user, as there is no ground truth to determine an optimal hyperparameter selection. It is typically not feasible to do an exhaustive search of hyperparameters so researchers typically make a normative choice based on similar studies in the literature, which provides great flexibility for the user. In this work, we illustrate how this flexibility can be exploited to manipulate the evaluation outcome. We frame this manipulation as an adversarial attack on the evaluation where seemingly innocent changes in hyperparameter setting significantly influence the evaluation outcome. We demonstrate the effectiveness of our manipulation across several datasets with large changes in evaluation outcomes across several explanation methods and models. Lastly, we propose a mitigation strategy based on ranking across hyperparameters that aims to provide robustness towards such manipulation. This work highlights the difficulty of conducting reliable XAI evaluation and emphasizes the importance of a holistic and transparent approach to evaluation in XAI.
Benchmarking XAI Explanations with Human-Aligned Evaluations
Nov 04, 2024


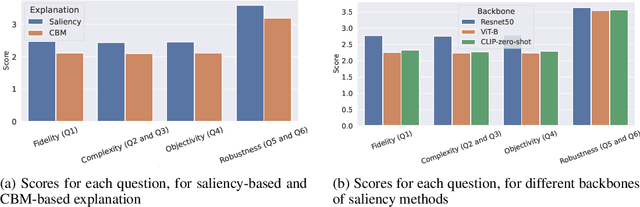
In this paper, we introduce PASTA (Perceptual Assessment System for explanaTion of Artificial intelligence), a novel framework for a human-centric evaluation of XAI techniques in computer vision. Our first key contribution is a human evaluation of XAI explanations on four diverse datasets (COCO, Pascal Parts, Cats Dogs Cars, and MonumAI) which constitutes the first large-scale benchmark dataset for XAI, with annotations at both the image and concept levels. This dataset allows for robust evaluation and comparison across various XAI methods. Our second major contribution is a data-based metric for assessing the interpretability of explanations. It mimics human preferences, based on a database of human evaluations of explanations in the PASTA-dataset. With its dataset and metric, the PASTA framework provides consistent and reliable comparisons between XAI techniques, in a way that is scalable but still aligned with human evaluations. Additionally, our benchmark allows for comparisons between explanations across different modalities, an aspect previously unaddressed. Our findings indicate that humans tend to prefer saliency maps over other explanation types. Moreover, we provide evidence that human assessments show a low correlation with existing XAI metrics that are numerically simulated by probing the model.
Quanda: An Interpretability Toolkit for Training Data Attribution Evaluation and Beyond
Oct 10, 2024

In recent years, training data attribution (TDA) methods have emerged as a promising direction for the interpretability of neural networks. While research around TDA is thriving, limited effort has been dedicated to the evaluation of attributions. Similar to the development of evaluation metrics for traditional feature attribution approaches, several standalone metrics have been proposed to evaluate the quality of TDA methods across various contexts. However, the lack of a unified framework that allows for systematic comparison limits trust in TDA methods and stunts their widespread adoption. To address this research gap, we introduce Quanda, a Python toolkit designed to facilitate the evaluation of TDA methods. Beyond offering a comprehensive set of evaluation metrics, Quanda provides a uniform interface for seamless integration with existing TDA implementations across different repositories, thus enabling systematic benchmarking. The toolkit is user-friendly, thoroughly tested, well-documented, and available as an open-source library on PyPi and under https://github.com/dilyabareeva/quanda.
CoSy: Evaluating Textual Explanations of Neurons
May 30, 2024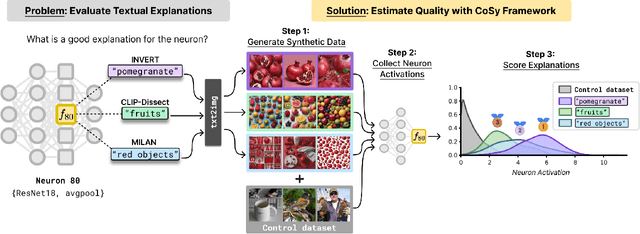


A crucial aspect of understanding the complex nature of Deep Neural Networks (DNNs) is the ability to explain learned concepts within their latent representations. While various methods exist to connect neurons to textual descriptions of human-understandable concepts, evaluating the quality of these explanation methods presents a major challenge in the field due to a lack of unified, general-purpose quantitative evaluation. In this work, we introduce CoSy (Concept Synthesis) -- a novel, architecture-agnostic framework to evaluate the quality of textual explanations for latent neurons. Given textual explanations, our proposed framework leverages a generative model conditioned on textual input to create data points representing the textual explanation. Then, the neuron's response to these explanation data points is compared with the response to control data points, providing a quality estimate of the given explanation. We ensure the reliability of our proposed framework in a series of meta-evaluation experiments and demonstrate practical value through insights from benchmarking various concept-based textual explanation methods for Computer Vision tasks, showing that tested explanation methods significantly differ in quality.
A Fresh Look at Sanity Checks for Saliency Maps
May 03, 2024The Model Parameter Randomisation Test (MPRT) is highly recognised in the eXplainable Artificial Intelligence (XAI) community due to its fundamental evaluative criterion: explanations should be sensitive to the parameters of the model they seek to explain. However, recent studies have raised several methodological concerns for the empirical interpretation of MPRT. In response, we propose two modifications to the original test: Smooth MPRT and Efficient MPRT. The former reduces the impact of noise on evaluation outcomes via sampling, while the latter avoids the need for biased similarity measurements by re-interpreting the test through the increase in explanation complexity after full model randomisation. Our experiments show that these modifications enhance the metric reliability, facilitating a more trustworthy deployment of explanation methods.
Sanity Checks Revisited: An Exploration to Repair the Model Parameter Randomisation Test
Jan 12, 2024The Model Parameter Randomisation Test (MPRT) is widely acknowledged in the eXplainable Artificial Intelligence (XAI) community for its well-motivated evaluative principle: that the explanation function should be sensitive to changes in the parameters of the model function. However, recent works have identified several methodological caveats for the empirical interpretation of MPRT. To address these caveats, we introduce two adaptations to the original MPRT -- Smooth MPRT and Efficient MPRT, where the former minimises the impact that noise has on the evaluation results through sampling and the latter circumvents the need for biased similarity measurements by re-interpreting the test through the explanation's rise in complexity, after full parameter randomisation. Our experimental results demonstrate that these proposed variants lead to improved metric reliability, thus enabling a more trustworthy application of XAI methods.
Explainable AI in Grassland Monitoring: Enhancing Model Performance and Domain Adaptability
Dec 13, 2023



Grasslands are known for their high biodiversity and ability to provide multiple ecosystem services. Challenges in automating the identification of indicator plants are key obstacles to large-scale grassland monitoring. These challenges stem from the scarcity of extensive datasets, the distributional shifts between generic and grassland-specific datasets, and the inherent opacity of deep learning models. This paper delves into the latter two challenges, with a specific focus on transfer learning and eXplainable Artificial Intelligence (XAI) approaches to grassland monitoring, highlighting the novelty of XAI in this domain. We analyze various transfer learning methods to bridge the distributional gaps between generic and grassland-specific datasets. Additionally, we showcase how explainable AI techniques can unveil the model's domain adaptation capabilities, employing quantitative assessments to evaluate the model's proficiency in accurately centering relevant input features around the object of interest. This research contributes valuable insights for enhancing model performance through transfer learning and measuring domain adaptability with explainable AI, showing significant promise for broader applications within the agricultural community.
Finding the right XAI method -- A Guide for the Evaluation and Ranking of Explainable AI Methods in Climate Science
Mar 01, 2023



Explainable artificial intelligence (XAI) methods shed light on the predictions of deep neural networks (DNNs). Several different approaches exist and have partly already been successfully applied in climate science. However, the often missing ground truth explanations complicate their evaluation and validation, subsequently compounding the choice of the XAI method. Therefore, in this work, we introduce XAI evaluation in the context of climate research and assess different desired explanation properties, namely, robustness, faithfulness, randomization, complexity, and localization. To this end we build upon previous work and train a multi-layer perceptron (MLP) and a convolutional neural network (CNN) to predict the decade based on annual-mean temperature maps. Next, multiple local XAI methods are applied and their performance is quantified for each evaluation property and compared against a baseline test. Independent of the network type, we find that the XAI methods Integrated Gradients, Layer-wise relevance propagation, and InputGradients exhibit considerable robustness, faithfulness, and complexity while sacrificing randomization. The opposite is true for Gradient, SmoothGrad, NoiseGrad, and FusionGrad. Notably, explanations using input perturbations, such as SmoothGrad and Integrated Gradients, do not improve robustness and faithfulness, contrary to previous claims. Overall, our experiments offer a comprehensive overview of different properties of explanation methods in the climate science context and supports users in the selection of a suitable XAI method.