 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the right XAI method -- A Guide for the Evaluation and Ranking of Explainable AI Methods in Climate Science
Mar 01, 2023



Explainable artificial intelligence (XAI) methods shed light on the predictions of deep neural networks (DNNs). Several different approaches exist and have partly already been successfully applied in climate science. However, the often missing ground truth explanations complicate their evaluation and validation, subsequently compounding the choice of the XAI method. Therefore, in this work, we introduce XAI evaluation in the context of climate research and assess different desired explanation properties, namely, robustness, faithfulness, randomization, complexity, and localization. To this end we build upon previous work and train a multi-layer perceptron (MLP) and a convolutional neural network (CNN) to predict the decade based on annual-mean temperature maps. Next, multiple local XAI methods are applied and their performance is quantified for each evaluation property and compared against a baseline test. Independent of the network type, we find that the XAI methods Integrated Gradients, Layer-wise relevance propagation, and InputGradients exhibit considerable robustness, faithfulness, and complexity while sacrificing randomization. The opposite is true for Gradient, SmoothGrad, NoiseGrad, and FusionGrad. Notably, explanations using input perturbations, such as SmoothGrad and Integrated Gradients, do not improve robustness and faithfulness, contrary to previous claims. Overall, our experiments offer a comprehensive overview of different properties of explanation methods in the climate science context and supports users in the selection of a suitable XAI method.
The Meta-Evaluation Problem in Explainable AI: Identifying Reliable Estimators with MetaQuantus
Feb 14, 2023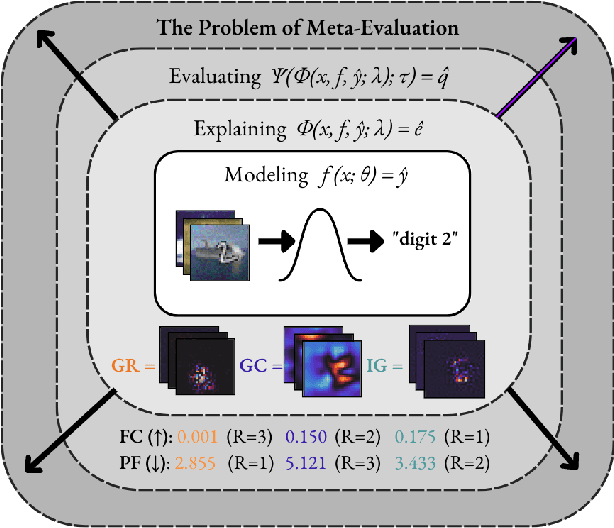



Explainable AI (XAI) is a rapidly evolving field that aims to improve transparency and trustworthiness of AI systems to humans. One of the unsolved challenges in XAI is estimating the performance of these explanation methods for neural networks, which has resulted in numerous competing metrics with little to no indication of which one is to be preferred. In this paper, to identify the most reliable evaluation method in a given explainability context, we propose MetaQuantus -- a simple yet powerful framework that meta-evaluates two complementary performance characteristics of an evaluation method: its resilience to noise and reactivity to randomness. We demonstrate the effectiveness of our framework through a series of experiments, targeting various open questions in XAI, such as the selection of explanation methods and optimisation of hyperparameters of a given metric. We release our work under an open-source license to serve as a development tool for XAI researchers and Machine Learning (ML) practitioners to verify and benchmark newly constructed metrics (i.e., ``estimators'' of explanation quality). With this work, we provide clear and theoretically-grounded guidance for building reliable evaluation methods, thus facilitating standardisation and reproducibility in the field of XAI.