 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeafTrackNet: A Deep Learning Framework for Robust Leaf Tracking in Top-Down Plant Phenotyping
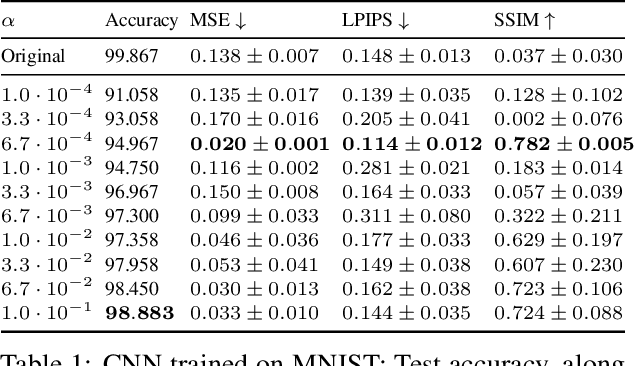
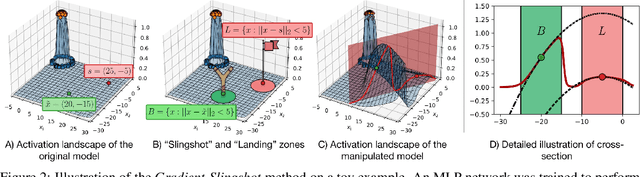
Dec 15, 2025High resolution phenotyping at the level of individual leaves offers fine-grained insights into plant development and stress responses. However, the full potential of accurate leaf tracking over time remains largely unexplored due to the absence of robust tracking methods-particularly for structurally complex crops such as canola. Existing plant-specific tracking methods are typically limited to small-scale species or rely on constrained imaging conditions. In contrast, generic multi-object tracking (MOT) methods are not designed for dynamic biological scenes. Progress in the development of accurate leaf tracking models has also been hindered by a lack of large-scale datasets captured under realistic conditions. In this work, we introduce CanolaTrack, a new benchmark dataset comprising 5,704 RGB images with 31,840 annotated leaf instances spanning the early growth stages of 184 canola plants. To enable accurate leaf tracking over time, we introduce LeafTrackNet, an efficient framework that combines a YOLOv10-based leaf detector with a MobileNetV3-based embedding network. During inference, leaf identities are maintained over time through an embedding-based memory association strategy. LeafTrackNet outperforms both plant-specific trackers and state-of-the-art MOT baselines, achieving a 9% HOTA improvement on CanolaTrack. With our work we provide a new standard for leaf-level tracking under realistic conditions and we provide CanolaTrack - the largest dataset for leaf tracking in agriculture crops, which will contribute to future research in plant phenotyping. Our code and dataset are publicly available at https://github.com/shl-shawn/LeafTrackNet.
Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
Jun 18, 2025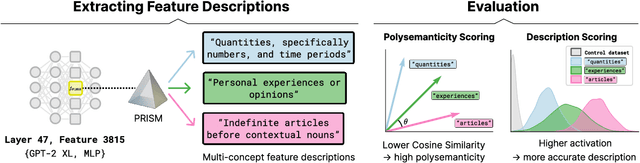

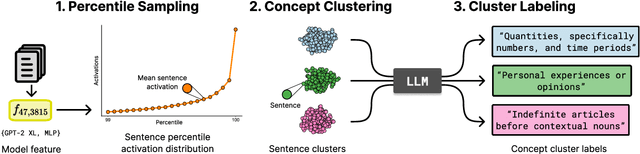

Automated interpretability research aims to identify concepts encoded in neural network features to enhance human understanding of model behavior. Current feature description methods face two critical challenges: limited robustness and the flawed assumption that each neuron encodes only a single concept (monosemanticity), despite growing evidence that neurons are often polysemantic. This assumption restricts the expressiveness of feature descriptions and limits their ability to capture the full range of behaviors encoded in model internals. To address this, we introduce Polysemantic FeatuRe Identification and Scoring Method (PRISM), a novel framework that captures the inherent complexity of neural network features. Unlike prior approaches that assign a single description per feature, PRISM provides more nuanced descriptions for both polysemantic and monosemantic features. We apply PRISM to language models and, through extensive benchmarking against existing methods, demonstrate that our approach produces more accurate and faithful feature descriptions, improving both overall description quality (via a description score) and the ability to capture distinct concepts when polysemanticity is present (via a polysemanticity score).
Deep Learning Meets Teleconnections: Improving S2S Predictions for European Winter Weather
Apr 10, 2025Predictions on subseasonal-to-seasonal (S2S) timescales--ranging from two weeks to two month--are crucial for early warning systems but remain challenging owing to chaos in the climate system. Teleconnections, such as the stratospheric polar vortex (SPV) and Madden-Julian Oscillation (MJO), offer windows of enhanced predictability, however, their complex interactions remain underutilized in operational forecasting. Here, we developed and evaluated deep learning architectures to predict North Atlantic-European (NAE) weather regimes, systematically assessing the role of remote drivers in improving S2S forecast skill of deep learning models. We implemented (1) a Long Short-term Memory (LSTM) network predicting the NAE regimes of the next six weeks based on previous regimes, (2) an Index-LSTM incorporating SPV and MJO indices, and (3) a ViT-LSTM using a Vision Transformer to directly encode stratospheric wind and tropical outgoing longwave radiation fields. These models are compared with operational hindcasts as well as other AI models. Our results show that leveraging teleconnection information enhances skill at longer lead times. Notably, the ViT-LSTM outperforms ECMWF's subseasonal hindcasts beyond week 4 by improving Scandinavian Blocking (SB) and Atlantic Ridge (AR) predictions. Analysis of high-confidence predictions reveals that NAO-, SB, and AR opportunity forecasts can be associated with SPV variability and MJO phase patterns aligning with established pathways, also indicating new patterns. Overall, our work demonstrates that encoding physically meaningful climate fields can enhance S2S prediction skill, advancing AI-driven subseasonal forecast. Moreover, the experiments highlight the potential of deep learning methods as investigative tools, providing new insights into atmospheric dynamics and predictability.
Evaluate with the Inverse: Efficient Approximation of Latent Explanation Quality Distribution
Feb 21, 2025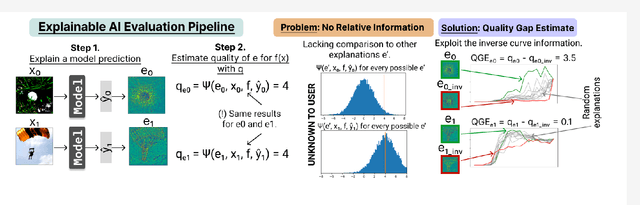



Obtaining high-quality explanations of a model's output enables developers to identify and correct biases, align the system's behavior with human values, and ensure ethical compliance. Explainable Artificial Intelligence (XAI) practitioners rely on specific measures to gauge the quality of such explanations. These measures assess key attributes, such as how closely an explanation aligns with a model's decision process (faithfulness), how accurately it pinpoints the relevant input features (localization), and its consistency across different cases (robustness). Despite providing valuable information, these measures do not fully address a critical practitioner's concern: how does the quality of a given explanation compare to other potential explanations? Traditionally, the quality of an explanation has been assessed by comparing it to a randomly generated counterpart. This paper introduces an alternative: the Quality Gap Estimate (QGE). The QGE method offers a direct comparison to what can be viewed as the `inverse' explanation, one that conceptually represents the antithesis of the original explanation. Our extensive testing across multiple model architectures, datasets, and established quality metrics demonstrates that the QGE method is superior to the traditional approach. Furthermore, we show that QGE enhances the statistical reliability of these quality assessments. This advance represents a significant step toward a more insightful evaluation of explanations that enables a more effective inspection of a model's behavior.
Model Guidance via Explanations Turns Image Classifiers into Segmentation Models
Jul 03, 2024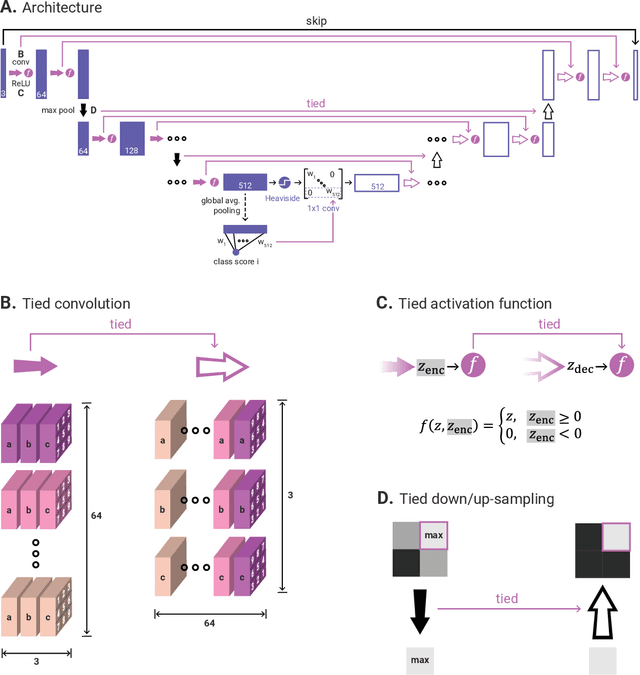
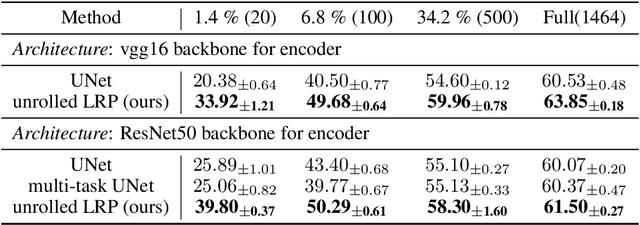

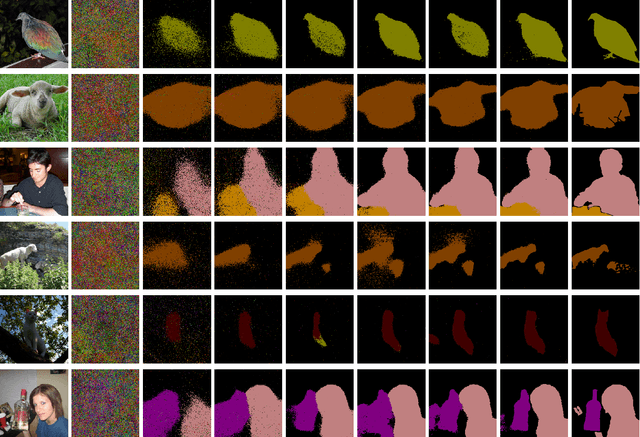
Heatmaps generated on inputs of image classification networks via explainable AI methods like Grad-CAM and LRP have been observed to resemble segmentations of input images in many cases. Consequently, heatmaps have also been leveraged for achieving weakly supervised segmentation with image-level supervision. On the other hand, losses can be imposed on differentiable heatmaps, which has been shown to serve for (1)~improving heatmaps to be more human-interpretable, (2)~regularization of networks towards better generalization, (3)~training diverse ensembles of networks, and (4)~for explicitly ignoring confounding input features. Due to the latter use case, the paradigm of imposing losses on heatmaps is often referred to as "Right for the right reasons". We unify these two lines of research by investigating semi-supervised segmentation as a novel use case for the Right for the Right Reasons paradigm. First, we show formal parallels between differentiable heatmap architectures and standard encoder-decoder architectures for image segmentation. Second, we show that such differentiable heatmap architectures yield competitive results when trained with standard segmentation losses. Third, we show that such architectures allow for training with weak supervision in the form of image-level labels and small numbers of pixel-level labels, outperforming comparable encoder-decoder models. Code is available at \url{https://github.com/Kainmueller-Lab/TW-autoencoder}.
CoSy: Evaluating Textual Explanations of Neurons
May 30, 2024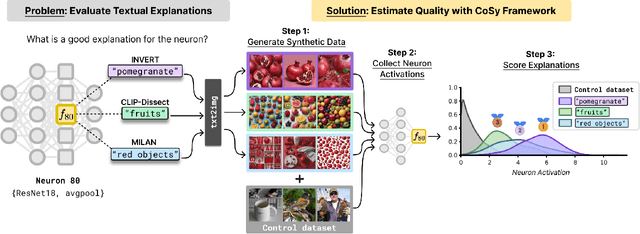


A crucial aspect of understanding the complex nature of Deep Neural Networks (DNNs) is the ability to explain learned concepts within their latent representations. While various methods exist to connect neurons to textual descriptions of human-understandable concepts, evaluating the quality of these explanation methods presents a major challenge in the field due to a lack of unified, general-purpose quantitative evaluation. In this work, we introduce CoSy (Concept Synthesis) -- a novel, architecture-agnostic framework to evaluate the quality of textual explanations for latent neurons. Given textual explanations, our proposed framework leverages a generative model conditioned on textual input to create data points representing the textual explanation. Then, the neuron's response to these explanation data points is compared with the response to control data points, providing a quality estimate of the given explanation. We ensure the reliability of our proposed framework in a series of meta-evaluation experiments and demonstrate practical value through insights from benchmarking various concept-based textual explanation methods for Computer Vision tasks, showing that tested explanation methods significantly differ in quality.
Manipulating Feature Visualizations with Gradient Slingshots
Jan 11, 2024
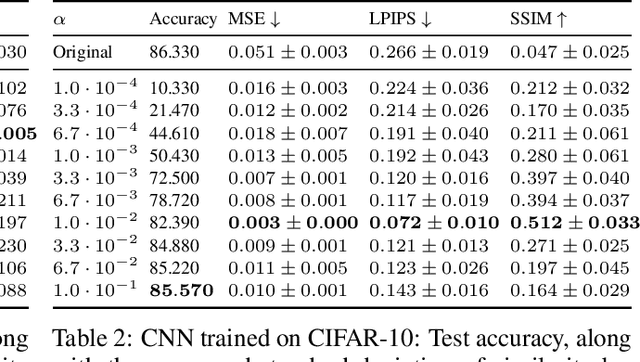
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
Explainable AI in Grassland Monitoring: Enhancing Model Performance and Domain Adaptability
Dec 13, 2023



Grasslands are known for their high biodiversity and ability to provide multiple ecosystem services. Challenges in automating the identification of indicator plants are key obstacles to large-scale grassland monitoring. These challenges stem from the scarcity of extensive datasets, the distributional shifts between generic and grassland-specific datasets, and the inherent opacity of deep learning models. This paper delves into the latter two challenges, with a specific focus on transfer learning and eXplainable Artificial Intelligence (XAI) approaches to grassland monitoring, highlighting the novelty of XAI in this domain. We analyze various transfer learning methods to bridge the distributional gaps between generic and grassland-specific datasets. Additionally, we showcase how explainable AI techniques can unveil the model's domain adaptation capabilities, employing quantitative assessments to evaluate the model's proficiency in accurately centering relevant input features around the object of interest. This research contributes valuable insights for enhancing model performance through transfer learning and measuring domain adaptability with explainable AI, showing significant promise for broader applications within the agricultural community.
Labeling Neural Representations with Inverse Recognition
Nov 22, 2023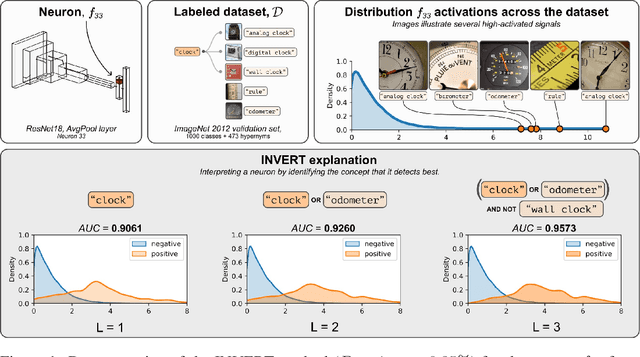

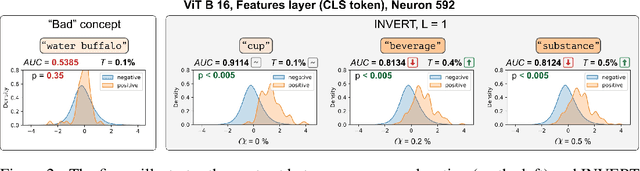
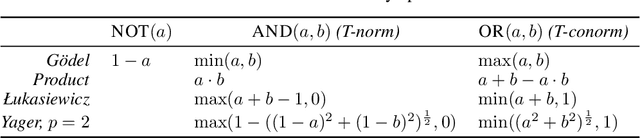
Deep Neural Networks (DNNs) demonstrated remarkable capabilities in learning complex hierarchical data representations, but the nature of these representations remains largely unknown. Existing global explainability methods, such as Network Dissection, face limitations such as reliance on segmentation masks, lack of statistical significance testing, and high computational demands. We propose Inverse Recognition (INVERT), a scalable approach for connecting learned representations with human-understandable concepts by leveraging their capacity to discriminate between these concepts. In contrast to prior work, INVERT is capable of handling diverse types of neurons, exhibits less computational complexity, and does not rely on the availability of segmentation masks. Moreover, INVERT provides an interpretable metric assessing the alignment between the representation and its corresponding explanation and delivering a measure of statistical significance, emphasizing its utility and credibility. We demonstrate the applicability of INVERT in various scenarios, including the identification of representations affected by spurious correlations, and the interpretation of the hierarchical structure of decision-making within the models.
* 24 pages, 16 figures
Kidnapping Deep Learning-based Multirotors using Optimized Flying Adversarial Patches
Aug 01, 2023
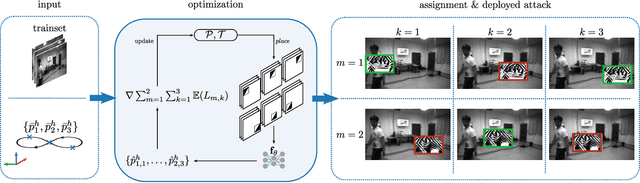
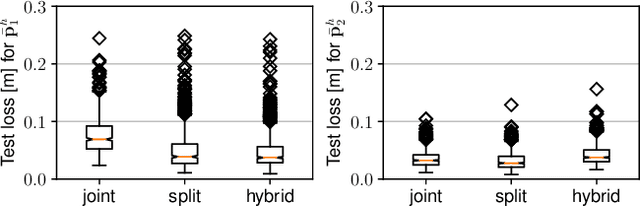
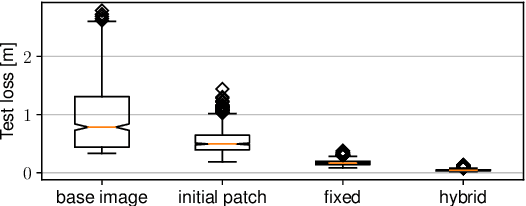
Autonomous flying robots, such as multirotors, often rely on deep learning models that makes predictions based on a camera image, e.g. for pose estimation. These models can predict surprising results if applied to input images outside the training domain. This fault can be exploited by adversarial attacks, for example, by computing small images, so-called adversarial patches, that can be placed in the environment to manipulate the neural network's prediction. We introduce flying adversarial patches, where multiple images are mounted on at least one other flying robot and therefore can be placed anywhere in the field of view of a victim multirotor. By introducing the attacker robots, the system is extended to an adversarial multi-robot system. For an effective attack, we compare three methods that simultaneously optimize multiple adversarial patches and their position in the input image. We show that our methods scale well with the number of adversarial patches. Moreover, we demonstrate physical flights with two robots, where we employ a novel attack policy that uses the computed adversarial patches to kidnap a robot that was supposed to follow a human.