 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating Feature Visualizations with Gradient Slingshots
Jan 11, 2024
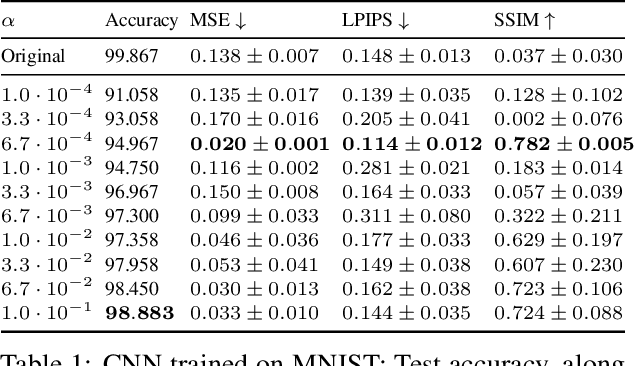
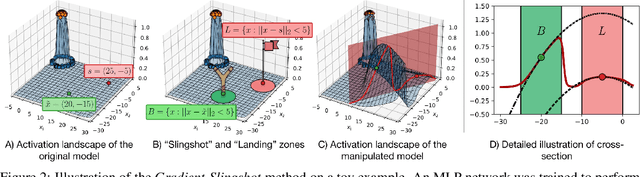
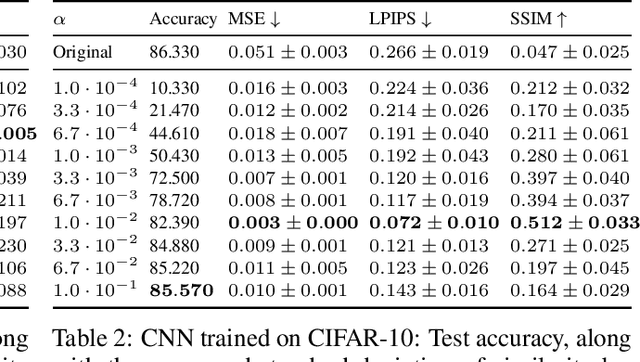
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
Evil from Within: Machine Learning Backdoors through Hardware Trojans
Apr 18, 2023



Backdoors pose a serious threat to machine learning, as they can compromise the integrity of security-critical systems, such as self-driving cars. While different defenses have been proposed to address this threat, they all rely on the assumption that the hardware on which the learning models are executed during inference is trusted. In this paper, we challenge this assumption and introduce a backdoor attack that completely resides within a common hardware accelerator for machine learning. Outside of the accelerator, neither the learning model nor the software is manipulated, so that current defenses fail. To make this attack practical, we overcome two challenges: First, as memory on a hardware accelerator is severely limited, we introduce the concept of a minimal backdoor that deviates as little as possible from the original model and is activated by replacing a few model parameters only. Second, we develop a configurable hardware trojan that can be provisioned with the backdoor and performs a replacement only when the specific target model is processed. We demonstrate the practical feasibility of our attack by implanting our hardware trojan into the Xilinx Vitis AI DPU, a commercial machine-learning accelerator. We configure the trojan with a minimal backdoor for a traffic-sign recognition system. The backdoor replaces only 30 (0.069%) model parameters, yet it reliably manipulates the recognition once the input contains a backdoor trigger. Our attack expands the hardware circuit of the accelerator by 0.24% and induces no run-time overhead, rendering a detection hardly possible. Given the complex and highly distributed manufacturing process of current hardware, our work points to a new threat in machine learning that is inaccessible to current security mechanisms and calls for hardware to be manufactured only in fully trusted environments.
Machine Unlearning of Features and Labels
Aug 26, 2021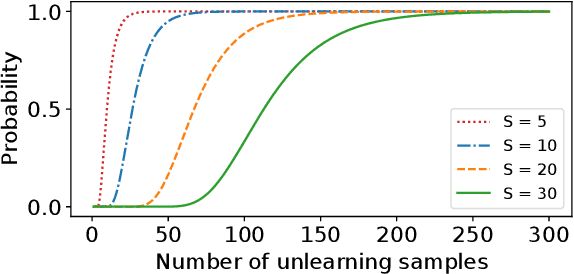

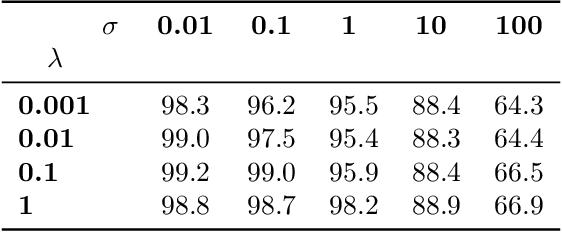
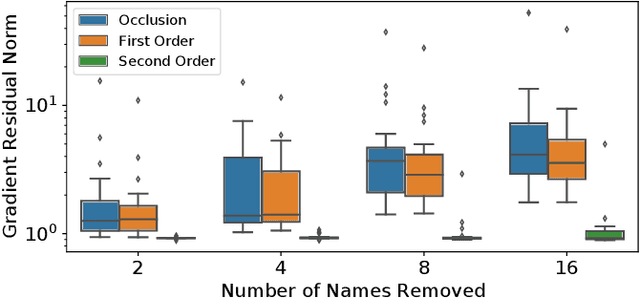
Removing information from a machine learning model is a non-trivial task that requires to partially revert the training process. This task is unavoidable when sensitive data, such as credit card numbers or passwords, accidentally enter the model and need to be removed afterwards. Recently, different concepts for machine unlearning have been proposed to address this problem. While these approaches are effective in removing individual data points, they do not scale to scenarios where larger groups of features and labels need to be reverted. In this paper, we propose a method for unlearning features and labels. Our approach builds on the concept of influence functions and realizes unlearning through closed-form updates of model parameters. It enables to adapt the influence of training data on a learning model retrospectively, thereby correcting data leaks and privacy issues. For learning models with strongly convex loss functions, our method provides certified unlearning with theoretical guarantees. For models with non-convex losses, we empirically show that unlearning features and labels is effective and significantly faster than other strategies.
Dos and Don'ts of Machine Learning in Computer Security
Oct 19, 2020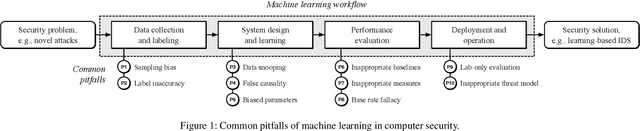
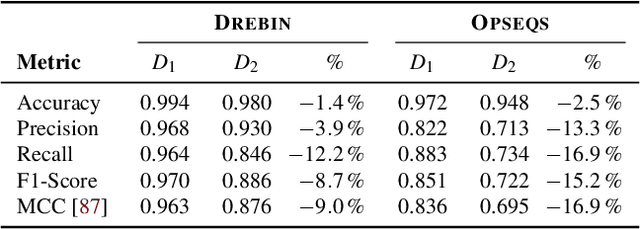
With the growing processing power of computing systems and the increasing availability of massive datasets, machine learning algorithms have led to major breakthroughs in many different areas. This development has influenced computer security, spawning a series of work on learning-based security systems, such as for malware detection, vulnerability discovery, and binary code analysis. Despite great potential, machine learning in security is prone to subtle pitfalls that undermine its performance and render learning-based systems potentially unsuitable for security tasks and practical deployment. In this paper, we look at this problem with critical eyes. First, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems. We conduct a longitudinal study of 30 papers from top-tier security conferences within the past 10 years, confirming that these pitfalls are widespread in the current security literature. In an empirical analysis, we further demonstrate how individual pitfalls can lead to unrealistic performance and interpretations, obstructing the understanding of the security problem at hand. As a remedy, we derive a list of actionable recommendations to support researchers and our community in avoiding pitfalls, promoting a sound design, development, evaluation, and deployment of learning-based systems for computer security.
Don't Paint It Black: White-Box Explanations for Deep Learning in Computer Security
Jun 06, 2019


Deep learning is increasingly used as a basic building block of security systems. Unfortunately, deep neural networks are hard to interpret, and their decision process is opaque to the practitioner. Recent work has started to address this problem by considering black-box explanations for deep learning in computer security (CCS'18). The underlying explanation methods, however, ignore the structure of neural networks and thus omit crucial information for analyzing the decision process. In this paper, we investigate white-box explanations and systematically compare them with current black-box approaches. In an extensive evaluation with learning-based systems for malware detection and vulnerability discovery, we demonstrate that white-box explanations are more concise, sparse, complete and efficient than black-box approaches. As a consequence, we generally recommend the use of white-box explanations if access to the employed neural network is available, which usually is the case for stand-alone systems for malware detection, binary analysis, and vulnerability discovery.